요인 분석
덤프버전 :

1. 소개[편집]
要因分析 / Factor analysis
양적 분석방법 중의 하나로, 다수 혹은 대량의 측정된 자료를 처리하여, 기존에는 관찰되지 않았으나 의미 있는 소수의 요인들을 추출하는 방법이다. 인자분석(因子分析)이라는 번역어와도 혼용되며, 특히 일본 학계에서 이런 표현을 쓰기도 하지만 국내에서도 표준국어대사전에 올라 있는 용어다.
요인분석은 분석가가 갖고 있는 분석목적에 따라 두 가지로 분류된다. 먼저 탐색적 요인분석(이하 EFA; exploratory factor analysis)은 기존에 요인모형이 존재하지 않는 상태에서 요인을 어림해 만들어 보는 것이다. 당연히, EFA를 거쳐 만들어진 요인모형은 검증되지 않은 것이기 때문에 남들에게 설득력 있게 제시할 수가 없다. 그렇기 때문에 연구자는 반드시 확인적 요인분석(이하 CFA; confirmatory factor analysis)을 거쳐서 그 모형이 정말로 적합하게 만들어졌는지, 요인구조에서 손봐야 할 곳이나 다듬을 점은 없는지 확인해야 한다.
때로는 여러 요인들의 배후에 존재하는 또 다른 요인을 찾아내기 위한 방법인 고차요인분석(higher-order factor analysis) 같은 것도 활용되곤 하지만, 이는 연구상황에 비추어서 요인이 너무 많고 복잡하다 싶을 때 연구자가 주체적으로 결정해야 하는 부분이다.
방금 언급한 "복잡함" 을 줄이는 것이 바로 요인분석의 특기다. 요인분석은 복잡한 추상적 개념을 간명하게 정리한다. 요인분석이 가장 싫어하는 것이 바로 복잡한 설명이다. 다양한 현상으로 나타나는 본질적인 하나의 특성(개념)을 찾고 싶을 때, 그것의 본질을 해치지 않는 선에서 최대한 명쾌하게 설명할 길을 찾는다. 따라서 요인분석에는 (다른 분석들과는 달리) 독립변인이니 종속변인이니 하는 개념들이 일체 불필요하다.
또한 요인분석은 질적인 의미해석을 위해 양적인 방법에 의존한다. 본 문서는 문두에서부터 '양적 분석방법 중의 하나' 라고 말하긴 했지만, 엄밀하게 말하자면 '양적으로 계산한 결과를 주관적으로 해석하는 분석방법' 이라고 보아야 한다. 당장 요인이라는 개념부터가 통계적으로 드러나지는 않았으되 분석가가 임의로 의미를 부여함으로써 성립하는 것이기 때문이다. 정말 주관적 해석을 싹 배제한 분석은 하술할 주성분분석(이하 PCA; principal component analysis)이 오히려 더 가깝다. 그래서 응용학문보다는 순수학문적 성격이 강한 통계학자일수록 요인분석에 시큰둥해하고 PCA에 관심을 갖는 경향이 있다. 대표적으로 통계학과 학부생들이 쓰는 유명 회귀분석 교과서를 보면 PCA를 활용한 회귀분석응 설명하는 교과서는 많지만, 요인분석의 결과물을 사용한 회귀분석을 설명하는 교과서는 없다. 사회과학계에서도 계량경제학 같은 '하드한' 분야에서는 PCA를 적극적으로 가져다 쓴다.[1] 마케팅 등의 '당장 써먹어야 하는' 분야에서는 요인분석(특히 CFA)을 집중적으로 파는 경향이 있다.
사실 학문적으로 따지자면 요인분석은 심리학계에 가장 큰 빚을 지고 있다. 당초 1869년에 프랜시스 골턴(F.Galton)이 그 논리적 기초를 다진 뒤, 하나의 연구방법론으로서 처음 데뷔한 것이 1904년 찰스 스피어만(C.Spearman)의 일반지능(general intelligence)에 대한 연구에서였다.[2] 여기서 그는 '지능' 이라는 밑도끝도 없이 뜬구름 잡는 개념을 명쾌하게 설명하기 위해 "인간의 지능은 일반적인 요인과 특수한 요인으로 나누어진다" 는 방법론적 전제를 세워놓았다. 어설프게나마 예를 들어서 수학 점수가 60점이고 체육 점수가 90점이라면, 두 과목 점수의 60점은 일반적인 지능 덕분에, 체육 점수의 나머지 30점은 체육에만 한정된 특수한 지능 덕분에 가능했다는 얘기다.
요인분석을 공부할 경우, 통계학과 학생들은 다변량분석을 공부하면서 같이 배운다. 보통 선형대수학과 수리통계학을 배운 후에 접하기 때문에 처음부터 끝까지 행렬이다. 통계학과 고학년 수업에 행렬아닌 걸 찾아보기가 더 힘들긴 하지만... 실제로 요인분석은 그 배경지식으로서 행렬에 대한 수학적 이해가 필수적이다.
한편 사회과학 분야에서는 사정이 좋지 못하다. 보통 이들이 접하는 사회통계 과목에서는 분포, 추정, 검정을 배운 후 분석이라 해 봤자 분산분석, 카이자승 분석, 회귀분석 정도를 맛보기로 접하는 데 그치기 때문에, 정말 의욕 있는 강사가 아니라면 요인 분석까지 가르칠 일이 없다. 그런데 막상 대학원 레벨에서는 당장 본인이 요인 분석을 써야 하거나, 혹은 요인 분석을 썼던 동료 연구자의 논문을 읽고 이해해야 한다. 그러다 보니 박사급 선배들에게 야매로 배우거나 아니면 돈 내고 어디서 방법론 특강을 듣거나, 그도 아니면 도서관에서 독학하는 수밖에 없게 된다.
도서관에 가기로 결정했다면, EFA의 경우 큰 도움을 받진 못할 가능성이 높다. CFA의 경우에는 2010년대 후반 들어 굉장히 좋은 책들이 많이 쏟아져나오고 있으며 그것들을 참고할 수 있지만, EFA는 상대적으로 오래 된 책들의 비율이 꽤 많은 편이다. 십수 년도 더 된 옛날의 통계 교과서에서 예컨대 "사각회전은 설득력 있는 통계적 처리가 어렵기 때문에 잘 쓰이지는 않는다" 는 문구가 발견된다 해도, 이를 2020년대에 접어들면서까지 곧이곧대로 믿을 이유가 전혀 없다! 그 동안 통계학자들이 뒹굴거리며 놀고 있었던 게 아니기 때문이다. 본인이 의욕이 있다면 해외원서 중에 임상심리학자 티모시 브라운(T.A.Brown)의 어려운 CFA 학술서를 손대 볼 수도 있다.[3] 그리고 참고로, 국내 번역서 중에는 《인자분석》 이라는 제하에 일본에서 만화 형태로 구성한
구글링은 가급적 보조적인 용도로만 사용하자. 국내 웹상에 퍼져 있는 요인분석 관련 블로그 포스트나 티스토리 등에서 요인분석과 PCA를 엄밀하게 구분하고 각각의 용도와 장단점을 비교해 주는 사례가 그야말로 손에 꼽는다.
아무튼 이런 접근성 문제로 인하여 요인분석이 "어렵다", "고급이다" 라는 이미지를 흔히 뒤집어쓰게 되기도 하지만, 사실 깊이 파고들었을 때 안 어려운 양적 연구방법은 없다고 봐야 한다. 그리고 어차피 가장 쉽다고 여겨지는 일원분산분석 같은 것도 진입장벽이 낮아 보이는 것일 뿐, 정말 제대로 이해하려면 통계학의 꽃이자 가장 다재다능(versatile)한 분석인 회귀분석에 대한 명쾌한 지식이 뒷받침되어야 한다. 통계적 방법은 기본적으로 연구문제에 봉착했을 때 그걸 설득력 있게 풀어내기 위한 수단일 뿐이며, 방법론의 진입장벽이 높아지는 이유는 그만큼 그 연구문제가 까다로워서 간단히 남을 설득하기가 힘들어지기 때문이다. 어려운 양적 분석은 연구자들을 괴롭히기 위한 수학 굇수들의 사디스틱한 수학문제 출제가 아니다(…). 요인분석의 기본적인 논리(logic) 자체는 고등학생이라 할지라도 납득할 수 있을 만큼 소박하다. 복잡한 개념을 단순 명쾌하게 교통정리하고(EFA), 자신이 정리한 결과물이 정말 합당한지 따져 보는(CFA) 과정이 바로 요인분석이다.
그렇다면 연구자가 정말로 결정해야만 하는 것은, 자신이 갖고 있는 연구문제가 그런 활동으로 해결하기에 적합한지이다. 사실, 눈돌아가는 휘황찬란한 통계적 처리보다 훨씬 더 중요한 것이 바로 이 지점이다. 이 연구문제가 과연 요인분석을 쓰기에 적합한가? PCA를 쓰는 편이 더 낫지는 않은가? 경로분석(path analysis)을 써야 하는가, 아니면 CFA를 써야 하는가? 이런 걸 모르면 요인분석을 한답시고 SPSS를 당당하게 돌렸는데 "추출 방법: 주성분 분석" 이라는 텍스트가 떡하니 찍혀나오는(…) 사태가 벌어질 수 있다. 피부 트러블에 무턱대고 아무 연고나 치덕치덕 바르는 것처럼, 연구문제에 무턱대고 아무 분석이나 들이대는 것이다.
연구 현장에서 요인분석은 두 가지 용도로 쓰인다. 첫째, 간단하게 설명하기 어려운 추상적 개념을 여러 하위개념으로 쪼개어 개념화해야 할 때에 쓰인다. 예컨대, 성격심리학에서 정립한 Big5에 대한 설명이 바로 이런 노력의 가장 빛나는 성과물이라고 할 수 있다. 요인분석을 통해 "성격이 뭐야?" 라는 밑도끝도 없는 질문에 대답할 수 있게 된 것이다. 둘째, 어떤 추상적 개념을 수치화하기 위한 척도 등의 측정도구를 타당화해야 할 때에 쓰인다. 세상에 '행복' 이나 '자존감' 같은 추상적인 개념에 대고 줄자로 폭과 높이 등을 재어 볼 수 있는 사람은 없다(…). 그래서 연구자들은 관련성이 있는 문항들에 얼마나 긍정적으로, 얼마나 강하게 응답하는지 간접적으로 재어 보려 한다. 여기서 '우리가 재어 본 결과가 실제로 그 개념에 일치한다' 고 얼마나 설득할 수 있는지는 요인분석 결과에 달렸다. 신뢰도와 타당도 문서도 함께 참고하자.
방법론 상의 대항마로서 Q방법론 같은 것들도 존재하기는 하나, 학계에서의 요인분석의 위상에는 미치지 못하고 있다.
방대한 요인분석의 개념에 대해 직관적으로 설명한 영상이 있다.
1.1. 시작하기 전에: 가상의 분석 예시[편집]
"너 말하는 걸 보니, 정말 나무위키 같구나!"
이 말에 대해 우리는 어떤 표정으로 반응해야 할까? 화자는 이 말의 청자에게 '나무위키다움' 이라는 뭔가를 느꼈기 때문에 그렇게 말한 것이 분명하다. 하지만 의문은 가시지 않는다. 도대체 나무위키답다는 건 무엇인가? 그것이 뭔가 긍정적일 수도 있지만, 나무위키의 평판을 냉정하게 따지자면 반대로 부정적일 수도 있다. 하지만 그렇다고 화자의 멱살을 잡기에는 그 '근거' 가 부족하다. 무엇을 근거로 나무위키 같다는 말이 부정적이라고 이해하는가?
대부분의 사람들은 그 자리에서 그게 무슨 뜻이냐며 캐묻겠지만, 시간도 쓸데없이 많고 열정도 쓸데없이 넘치는 김 씨가 구태여 요인분석을 준비한다고 가정하자. 먼저, 인터넷 사이트 이곳저곳을 뒤적거린 끝에, 김 씨는 나무위키를 묘사하기 위해서 숱한 사람들이 동원한 형용사들 상당수를 확보할 수 있었고, 그 중에서 특히 많이 활용되는 형용사 15개를 추려낼 수 있었다.
- 방대한 / 무가치한 / 신뢰할 수 없는 / 세세한 / 무책임한 / 웃기는 / 편향적인 / 중독적인 / 개방적인 / 민주적인 / 혐오스러운 / 가벼운 / 뭐든지 있는 / 아는 체하는 / 정보성 있는
그러나, 이걸 이대로 고스란히 설명에 활용하기에는 너무 복잡하다. 그 화자가 청자에게 "네 지식은 정말 방대하고 무가치하고 신뢰할 수 없고 세세하고 무책임하고..." 같은 식의 의미를 전달하려던 건 아닐 것이기 때문이다. 뭔가 더 간단 명료하면서도 설득력 있는 설명이 필요하다. 물론 주관적으로 몇 가지 의미로 묶을 수는 있겠지만, 의미군(群)으로 나누는 기준이 뭐냐고 물으면 대답할 길이 없고, 왜 하필 의미군의 개수가 그만큼이냐는 질문에도 대답할 수 없기 때문이다. 따라서 김 씨는 요인분석, 특히 EFA를 통해 자신의 교통정리에 설득력을 부여해야 한다.
김 씨는 요인분석이 어떤 논리를 따르는지 알고 있었던 데다, 운 좋게도 수백 명의 잠재적 응답자들을 보유하고 있었다. 김 씨는 그들에게 각각의 형용사가 나무위키를 얼마나 잘 묘사한다고 생각하는지 10점 만점으로 점수를 각각 매겨 달라고 요청했고, 그 응답 데이터를 확보할 수 있었다.
첫째 관문은 상관행렬이다. 요인분석의 논리에 따라, 김 씨는 문항 간 상관을 계수(coefficient)로서 나타내는 행렬을 15개 형용사들 간에 전부 계산했다. 그러나 행렬이 너무 거대하고 숫자가 너무 많아서 눈이 빙글빙글 돌 것 같았기 때문에, 여기서는 계수 절대값의 일정한 크기에 따라 색상으로 각 셀을 색칠했다. ±0.3 이하일 때에는 가장 흐리게, ±0.5 이상으로 커질 때에는 가장 진하게 표시하면, 상관행렬은 다음과 같은 모습으로 알록달록해진다.
둘째 관문은 요인추출이다. 김 씨는 자신이 공통요인모형에 입각해서 분석을 진행한다는 것을 인식하고 있었으므로, 이 행렬의 숫자들을 이리저리 뜯어고치고 분해하고 추정한 끝에, 비로소 각 요인성분의 행렬을 얻어낼 수 있었다. 원론적으로 요인의 수는 문항의 수만큼 만들어질 수 있는데, 일단 김 씨는 네 개까지 따져볼 법하지 않을까 하고 상상한 뒤 요인행렬을 만들었다.
[4]
이 요인행렬은 훈련된 연구자가 보더라도 그저 숫자더미에 불과하다. 김 씨 또한, 자신이 얻은 이 밑도끝도 없는 숫자놀음을 수학적으로 훼손하지는 않으면서 좀 더 "예쁘게" 꾸밀 필요가 있었다. 그래야만 그 숫자들을 해석하고 의미부여를 하기에 쉬워지기 때문이다.
셋째 관문은 요인회전이다. 김 씨는 위의 저 막막한 행렬을 살짝 바꾸어, 수학적으로 완벽하게 동일한 가치를 갖는 또 다른 형태의 행렬로 변화시켰다. 그리고 각 문항들을 숫자의 크기에 맞게 새롭게 정렬하고 순서대로 하이라이트했다. 결과적으로, 요인분석가라면 누구나 간절히 바라는 '아름다운' 숫자들이 나타났다.
[5]
마지막 순간, 막상 이 네 개의 요인들을 전부 인정하려던 김 씨는 설명이 너무 복잡해지는 게 아닌가 하는 의구심을 느꼈다. 단순한 설명을 원해서 시작한 분석인데, 요인을 네 개씩이나 포함하면 분석하는 의미가 없기 때문이다. 혹시나 싶어서 각 요인들이 갖는 일종의 '해석적 중요성' 을 비교해 보기로 했다. 다행히 김 씨는 '스크리도표' 라는 그래프에 대해 알고 있었다.

여기서 네 번째 요인은 숫자 1 이하로 떨어져 있기 때문에, 이를 기준점으로 삼아서 김 씨는 넷째 요인이 너무 사소하다는 이유로 자신의 해석에 굳이 포함시키지 않기로 결정했다. 김 씨는 남겨진 세 개의 요인에 이름을 붙이고, 이를 바탕으로 하여 "나무위키답다는 것은 무엇인가?" 의 질문에 답하고자 하였다.
- 나무위키다움은 무엇인가?
- [ 요인 1 ] 비신뢰성: 신뢰할 수 없고, 편향적이며, 무책임하고, 혐오스러우며, 아는 체하고, 무가치한 것
- [ 요인 2 ] 가벼움: 가볍고, 웃기고, 중독적인 것
- [ 요인 3 ] 포괄성: 뭐든지 있고, 방대하며, 세세하고, 정보성 있는 것
-
[ 요인 4 ] 개방성: 개방적이고, 민주적인 것
즉, 김 씨의 요인분석에 따르면, 누군가를 나무위키답다고 비유하는 것은 곧 "너는 어디서 굴러먹던 이상한 썰이나 나불대는 주제에 은근히 웃겨서 자꾸 듣게 된단 말이지, 게다가 쓸데없이 별걸 다 알고 있어" 의 메시지를 전달한다는 해석이 가능하며, 윗줄의 해석은 심지어 통계적 방법으로 지지되고 있다고도 말할 수 있다.
이 분석 결과에 따르면, 나무위키답다는 말은 그다지 칭찬하는 표현이 아니다. 가장 먼저 튀어나온 요인이 하필이면 '비신뢰성', 즉 부정적인 의미가 부여되어 있기 때문이다. 둘째 및 셋째 요인이 꽤나 긍정적인 의미라는 점이 그나마 위안. 김 씨는 그 청자가 화자의 멱살을 잡는다 해도 굳이 말리지는 않을 가능성이 높다.
이제 김 씨가 어떻게 분석을 한 것인지 차근차근 되짚어 보기로 하자.
2. 설명[편집]
국내에는 미번역된 《Exploratory Factor Analysis》 라는 교과서에 따르면,[6] 요인분석의 기본 전제(basic assumptions)는 다음과 같다.
- 인과성(causality)
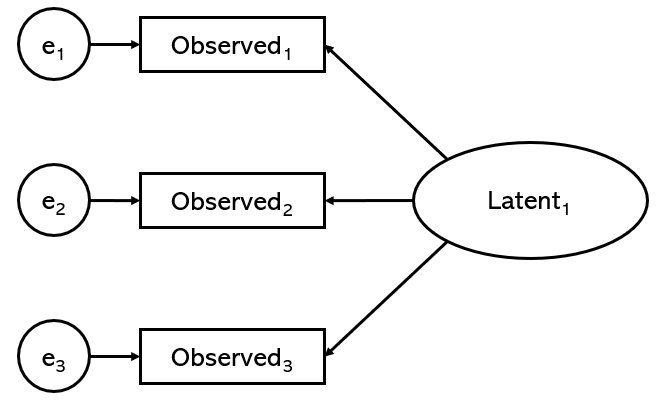
요인분석에서는 모든 '공통요인' 이 지표변인(indicator)[7]의 원인이 되는 인과적 관계가 성립한다. 본 문서의 맨 위로 올라가서 요인분석을 묘사한 그림자료를 보자. 타원형으로 표시된 공통요인, 사각형으로 표시된 지표변인 사이에서 화살표가 어디로 향하고 있는지 살펴보자. 타원형과 사각형을 연결하는 모든 화살표는 타원형에서 사각형으로 향하고 있음을 알 수 있다. 즉, 요인분석은 각 지표변인들의 배후에 있는 원인(cause)으로서 요인을 지목한다. 이것은 아래 CFA에서 설명하게 될 '반영지표모형' 의 논리와도 상통한다.
- 선형성(linearity)
위에서 전제했던 공통요인과 지표변인 사이의 인과성에는 선형적 관계가 성립한다. 즉, 인과성의 크기가 갑자기 커지거나 갑자기 작아지거나, 거꾸로 뒤바뀌거나 하는 경우는 없다고 상정한다. 이게 왜 중요한가 싶을 수도 있지만, 바로 이 전제 때문에 분석에 동원되는 모든 지표변인들은 측정 수준(measurement level)에 있어서 등간 또는 비율 수준의 측정이어야 한다는 전제가 새로 발생하고, 공통요인들 사이의 상호작용(interaction) 효과 또한 0이라고 상정된다. 흔히 "요인분석에 성별이나 종교유무 여부를 묻지 말라" 는 충고가 있는데, 따지고 올라가면 "그렇다 vs. 아니다" 류의 명목적인 질문 문항들은 선형성 가정을 위반하기 때문이다.
단, 이런 한계점이 있다는 것은 뒤집어 말하면 방법론 연구자들이나 통계학자들에게는 좋은 연구거리가 된다는 말인지라, 먹이를 노리는 매의 눈으로 요인분석을 주시하는 수많은 학자들이 비선형적 요인분석(nonlinear factor analysis)을 만들기 위해 지금 이 순간에도 실시간으로 갈려나가고 있다.[8] 새로운 방법론이 개발된다면 그때에는 기본 전제에 있어서 지금보다 더 자유로워질 것으로 보인다.
단, 이런 한계점이 있다는 것은 뒤집어 말하면 방법론 연구자들이나 통계학자들에게는 좋은 연구거리가 된다는 말인지라, 먹이를 노리는 매의 눈으로 요인분석을 주시하는 수많은 학자들이 비선형적 요인분석(nonlinear factor analysis)을 만들기 위해 지금 이 순간에도 실시간으로 갈려나가고 있다.[8] 새로운 방법론이 개발된다면 그때에는 기본 전제에 있어서 지금보다 더 자유로워질 것으로 보인다.
- 다변량 정규성(multivariate normality)
항상 전제되는 것은 아니고, 특정 방법으로 모형적합도 검정을 할 때에만 유효하다고 상정되는 전제다. 이것은 모든 지표변인들이 다변량 정규분포를 따를 것이라는 진술이다. 이 전제가 깨어지게 되는 특수한 경우가 있는데, 하술하게 될 '최대우도법' 이라는 방법을 사용해야 할 때에 데이터 세트의 절대적 왜도(skewness) 값이 2 이상이면서 그와 동시에 절대적 첨도(kurtosis) 값이 7 이상인 경우이다. 이런 상황에서 '최대우도법' 을 써서 모형적합도를 따질 경우, 그 결과물에 대해서 이의제기가 나올 수 있음을 예상하라는 얘기.
- 완전 선형 의존성(perfect linear dependency)의 부재
이 역시 모형적합도 검정을 할 때에만 추가로 따라붙는 기본 전제이다. 이것은 모든 지표변인들이 서로 간에 완전선형함수의 관계를 갖지 않는다고 진술한다. 복잡해 보이지만 간단히 말하면, 다른 지표변인들의 합계나 평균을 계산한 결과가 지표변인들 사이에 끼어들어 있으면 분석을 재고해야 한다는 얘기다. 예컨대, 지표변인 5번이 지표변인 1번~4번의 값을 평균한 것이라면, 원칙적으로 모형적합도를 따져볼 수 없다.
요인분석에 대해 설명하기 위해서는 먼저 요인이라는 개념에 대해서부터 설명하고 넘어가야 할 것이다. 요인을 엄밀하게 정의하자면 이론화 과정에서 가설(假設)할 것이 요구되는 개념적 구성(construct)으로 요약될 수 있다. 즉 '사변적인 설명을 위해서 인위적으로 만들어놓아야 하는 어떤 응집된 개념' 이라는 것이며, 이미 여기서 요인이라는 개념은 숫자의 세계를 벗어나게 된다. 그래서 수학자들과 통계학자들은 요인이라는 '주관적' 인 단어를 좋아하지 않으며, 그저 잠재변인(latent variable) 내지는 관측되지 않은 변인(unobserved variable)이라고만 이름붙이고는 별다른 관심을 주지 않는다.
요인분석에서 모든 요인들은 둘로 나누어지는데, 먼저 (위에서 잠깐 언급했던) 공통요인(common factor)이 그 하나요, 그리고 고유요인(unique factor)이 다른 하나이다. 다시 이 문서 맨 위의 그림으로 돌아가 보자. 그 그림에서 상단에 '에타' 가 붙은 타원형이 바로 공통요인이며, 하단에 '엡실론' 이 붙은 원형이 바로 고유요인이 된다. 은근히 중요한 것인데, 요인분석의 통계적인 특징 중 하나가 바로 이 고유요인의 존재를 끊임없이 인식하면서 분석에 반영한다는 데 있다. 요인분석을 하는 초보 연구자가 고유요인의 존재를 무시하다시피 하면서 공통요인만 가지고 분석결과를 해석했다가는 방법론 연구자들의 거센 반발을 부르기 십상이다.
공통요인들과 고유요인들은 각 지표변인들에 저마다 영향을 끼친다. 어떤 요인이 지표변인에 끼치는 영향의 크기, 좀 더 정확히 말하자면 그 요인이 지표변인에 끼치는 공분산의 크기를 나타내는 개념이 바로 요인적재량(factor loading)이다. 이 개념은 일본 학계에서는 부하량(負荷量)으로 번역하고 있으며 국내에서도 그 영향인지 다양한 분야들에서 부하량이라고들 하지만, SPSS 한글 번역판에서 표기하듯이 '적재량' 으로 번역하는 편이 조금 더 정확할 것으로 보인다. 이 개념은 '람다' 기호를 사용해서 나타낼 수 있다.
요인적재량은 해당 지표변인과 요인 사이의 상관관계를 -1 ~ +1 사이의 값으로 표시한다. 확고한 기준은 없지만, 그 값이 보통 ±0.5 이상일 때 유의하다고 하는데, 표본이 작고 지표변인의 수도 적다면 허들을 높일 필요가 있다고 알려져 있다. 요인적재량을 제곱하면 총분산 중 그 요인을 통해 설명되는 분산의 비율을 얻을 수 있다. 또 요인적재량이 양수 값이라면 지표변인이 단위별로 증가할 때 공통요인도 증가하는 관계가 존재하는 선형적 관계가 존재한다고 해석할 수 있다. 이런 면모들로 보자면 요인적재량은 피어슨 상관계수 개념과도 유사한 점이 있다.
요인적재량과 비슷한 개념으로 고유값(eigenvalue)이라는 게 있다. 이는 각 요인이 담당하는 분산의 양을 표현하는 값이다. 즉 고유값이 클수록 그 요인은 중요성을 갖는 요인이라는 뜻이 되며, 위의 예시에서 한번 보았던 '스크리도표' 의 세로축이 바로 이 고유값을 가리키는 것이다. 고유값이 큰 요인은 스크리도표의 왼쪽에 놓이게 되며, 대개 연구자의 관심을 끌게 된다. 이처럼, 고유값의 크기는 논리적으로 그 요인모형에서 해석의 대상으로 삼을 요인의 수를 결정하는 데 결정적인 영향을 끼친다.
또 다른 비슷한 개념으로 공통성(commonality)이 있다. 이것은 어떤 지표변인의 총분산 중에서 이 공통요인들에 의해 설명될 수 있는 분산이며, 표현을 바꾸자면 주어진 지표변인들로부터의 공통요인에 대한 요인적재량의 제곱합이라고도 할 수 있다. 말이야 어렵지만 '제곱' 합이라는 점에서 회귀분석에 나오는 r2 개념과도 유사하다. 공통성 역시 0에서 1 사이의 값을 갖는데, 1에서 공통성을 뺀 값은 고유요인으로 설명해야 할 오차분산으로 취급한다. 공통성이 0.5 이상으로 높은 지표변인은 요인모형을 구성하는 데 큰 역할을 하며, 연구자가 분석 과정에서 의미부여를 할 때에도 공통성 높은 지표변인을 크게 참고하게 된다.
고유값이 전체 요인모형에서 '특정 요인 자체가 갖는 중요성' 을 나타낸다면, 공통성은 '특정 지표변인에서 전체 공통요인이 갖는 설명적 중요성', 요인적재량은 '특정 지표변인에서 특정 공통요인이 갖는 중요성' 이라고도 할 수 있겠다. (요인적재량의 경우 '요인모형에서 화살표 하나하나가 갖게 되는 중요성', 공통성의 경우 '특정 지표변인으로 꽂히는 모든 화살표들의 중요성' 이라고 볼 수도 있을 것이다.) 정 모르겠다면 교수님이나 연구원 분들께 여쭤보자.
2.1. 탐색적 요인분석(EFA)[편집]
2.1.1. 표본의 준비[편집]
이제 주요 개념들도 한 번씩 짚어봤으니, 드디어 요인분석을 본격적으로 시작할 차례다. 이것도 일단은 통계적 방법을 동원하는 분석인 만큼, 우리가 분석에 활용할 데이터가 필요하다. 그리고 그 데이터는 다양한 방식으로 얻어지지만, 여기서는 일단 질문지법을 활용한다고 가정하자. 제일 먼저 봉착하는 문제는 표본의 크기다. 요인분석에서는 N≥30 같은 어림법이 일체 불필요하기 때문이다. 요인분석에 필요한 표본은 얼마나 커야 하는가?
물론 통계적 분석이라는 것은 늘 표본이 크면 클수록 그만큼 신뢰를 받을 수 있지만, 이게 말이 쉽지 대부분의 경우에는 자신이 희망하는 규모의 표본을 모으기가 많이 힘들다. 흔한 대학원생 나부랭이(?)들은 더 말할 것도 없거니와 현직 교수들도 네 자리 숫자의 표본을 만드는 건 쉬운 일이 아니다. 무슨 (종합)사회조사 같은 거라도 쓸 게 아니라면, 대개의 연구자들은 수백 명 수준에서 설문 응답자들을 구하고자 할 것이다. 그렇다면 표본의 크기가 문제가 된다는 것은, 요인분석에서 그 정당성을 인정받을 수 있는 최소한의 표본 크기가 얼마인지의 문제로 정리할 수 있다.
일단 절대적인 표본 크기가 중요하다는 의견들이 있다. 요인분석에서도 "잘 모르겠으면 몇 명 이상!" 의 기준을 세울 수 있다는 것이다. 그런데 그 숫자는 아직까지 제대로 합의되지 않았다. 어떤 문헌에서는[9] 그 기준을 100명으로 설정하라는 제안도 있지만, 다른 문헌에서는[10] 300명이 넘어가야만 한다고 단호하게 조언한다. 다른 쪽에서는 지표변인의 수와 응답자 수의 비율, 소위 관측 대 변인(observations to variables) 비율을 함께 볼 것을 제안한다. 예컨대, 한 문헌에서는[11] 관측변인의 수보다 응답자의 수가 5배 이상이면서, 절대적으로 보아도 응답자가 100명을 넘겨야 한다고 하였으며, 앞에서 소개했던 조지프 헤어(J.F.Hair)의 문헌에서는 앞의 100명 기준에 더하여 20:1의 아득한 비율을 요구했다.
하지만 《Exploratory Factor Analysis》 에서 정리하듯이, 현대의 방법론 연구자들은 이것이 단순한 어림법에 가까운 문제이며 이를 어긴다고 해서 딱히 큰일이 나는 것도 아니라고 생각한다. 오히려 정말 중요한 것은 표본의 크기가 아니라 그 표본이 얼마나 질적으로 좋은 표본인가의 문제라는 것이다. 계량심리학계의 몇몇 논문들에 따르면[12][13] 그 표본에서 요인적재량과 공통성이 좋게 나타난다면 그만큼 표본이 작더라도 그 분석결과를 신뢰할 수 있다. 이 바닥에서 특히 많이 인용된 한 논문에 따르면[14] 공통성이 .70 이상이면서 각 요인마다 3~5개의 지표변인이 적재되는 '최적의 조건' 에서는 N=100 표본으로도 충분하지만, 공통성이 .40 이하이고 일부 요인들에서 2개 이하의 지표변인만이 적재되는 '열악한 조건' 이라면 N≥400 표본조차도 부적절할 수 있다고 한다. 요인분석을 시행하는 연구자가 스스로 "완벽한 표본조사" 를 수행할 수 있다는 자신이 있다면 몰라도(…), 교내에서 수업 중에 들어가서 설문을 실시할 수밖에 없다면 별 수 없이 닥치고 최대한 긁어모으는 수밖에 없다는 것.
참고로 요인분석은 결측값을 처리하지 못한다. 따라서, 표본으로부터 데이터를 얻었다면 분석을 시작하기 전에 먼저 한번 스크리닝을 실시할 필요가 있다. 누군가는 어쩌면 설문지의 일부 문항에 기입하는 것을 깜박했을 수도 있고, 그 결측값이 데이터 세트에 섞여들어가면 요인분석 전체를 망가뜨린다(…). 왜냐하면 요인분석이 첫 시작점으로 삼는 문항 간의 상관은, 어떤 지표변인에서 단 하나의 결측이 확인된다면 그걸 핑계(?)로 그 지표변인 전체의 응답을 제거해 버리기 때문이다. 이를 목록 전체 제거(list-wise deletion)라고도 한다. 따라서 표본이 충분히 크다면 그 응답자의 응답지를 빼 버릴 수 있고, 표본이 너무 작다면 그 빈 값을 해당 지표변인의 평균으로 임의로 채울 수도 있다. 물론 이런 한계를 극복하는 것 역시 연구업적이 되는지라, 고금의 방법론 연구자들이 달려들어서 파고 있는 주제이기도 하다.[15][16]
2.1.2. 상관행렬[편집]
위의 예시에서 김 씨가 그랬듯이, 요인분석은 상관행렬을 그 재료로 삼아서 시작한다. 상관행렬(correlation matrix)이란, 다수의 관찰된 변인들 (요인분석의 경우 다수의 지표변인들) 간의 상관계수 값으로 구성된 행렬을 의미한다. 설령 수포자(…) 출신의 사회과학도라 할지라도, 상관행렬은 몇 번 보면 금방 익숙해질 만큼 특이하기 짝이 없는 행렬의 모습을 하고 있다. SPSS에서나 논문에서나, 상관행렬은 언제나 우하향 대각선의 숫자가 1.0 으로 통일되어서 출력된다. 그리고 요인분석은 여러 지표변인들을 요인으로 묶어주기 위해, 서로 상관이 높아 보이는 지표변인들에 우선적으로 주목한다. 위에서 소개한 조지프 헤어에 따르면 그 상관관계의 크기는 계수 값이 ±0.3일 때 최소한의 수준, ±0.4일 때 중요한 수준, ±0.5일 때 실질적으로 유의하다고 한다.
상관행렬을 얻었다면 본격적으로 분석하기 전에 과연 이 상관행렬이 요인분석에 얼마나 적합한 행렬인지를 먼저 따져봐야 한다. 기껏 상관행렬을 구했는데 지표변인 간 상관관계가 거의 제대로 나타나지 않으면 골치아파지기 때문이다. 이것을 구형성 검정(test of sphericity)이라고 부른다. 여기에는 크게 두 가지가 제시되어 있다. 구형성 검정을 처음 제안한 사람의 이름을 딴 Bartlett의 방법에 따르면,[17] 모집단에서 모든 상관관계가 0이라는 영가설을 세워놓고 이를 검정할 수 있다. 문항 간 상관이 모든 경우에 0이라는 통계적으로 괴이한 상황이 아니라면, 즉 영가설이 기각된다면 비로소 그 자료에서 뭔가 공통요인을 발견할 수 있으리라 믿고 요인분석을 실시해 보자는 것이다. 영가설의 기각 기준은 p<.05 정도로 대개 잡아놓는다. 다음으로 Kaiser-Meyer-Olkin(KMO) 값을 들 수 있다. 여기서는 각 지표변인들이 셋 이상 상관을 갖는 정도를 확인한다. 물론 KMO 값이 크면 클수록 뭔가 지표변인들 사이에 상관이 예쁘게 나타난다는 말이니, 요인분석이 가능하다고 할 수 있다. 여기서의 임계치는 KMO>.50 정도로 하되, 양호한 수준은 .80 ~ .90 정도로 잡을 수 있다.[18]
구형성 검정에서 긍정적인 결과를 얻었다면, 이제 바로 분석을 시작하면 될까? 사실, 여기서 방법론 간의 첫 갈림길이 나타난다. PCA를 진행하는 연구자라면, 이 행렬을 고스란히 분석에 써먹으면 된다. 하지만 요인분석을 진행하는 연구자는 여기서 저 숫자 1의 대각선을 의심스럽게 볼 수밖에 없다. 요인분석의 시각에서 볼 때, 숫자 1의 대각선에는 공통요인의 분산, 고유요인의 분산, 공통성, 고유분산 등이 전부 뒤섞여 있기 때문이다. 따라서 차후 이 행렬을 분해하고자 해도, 이대로는 공통요인과 고유요인을 분리한 수치를 얻을 수 없다. 과거 국내에 요인분석이 희귀했던 시절에는 이 문제를 너무나 관행적으로 무시해 왔지만, 사실 이대로는 요인분석이 불가능하다. 요인분석은 '요인 = 공통요인 + 고유요인' 등식을 세우고 있으며, 앞에서도 언급했지만 요즘에는 고유요인의 존재를 무시하고 해석했다가는 큰일난다! 요인분석을 진행하기 전에, 연구자는 반드시 이 문제를 해결해야만 한다.
그래서 나온 것이 바로 축소상관행렬(reduced correlation matrix) 혹은 수정상관행렬(adjusted correlation matrix)이다. 이 행렬은 상관행렬의 저 독특한 숫자 1 대각선의 각 값들을 각 변인들이 갖는 공통성으로 대체한 것이다. 그리고 상관행렬을 이렇게 '축소' 하는 과정을 사전 공통성 추정(prior commonality estimate)이라고 부른다. 숫자 1 대신에 집어넣을 공통성을 알아야 하니, 일단은 추정해서라도 그 자리에 뭔가 공통성 같아 보이는 숫자로 채워넣자는 것이다(…).
먼저 언급할 만한 추정법으로는, 다소 마이너하게 쓰이긴 하지만 회귀분석의
다음으로 메이저한 추정법을 소개하자면 재분해법(refactoring)이 있다. 여기서는 최초의 축소상관행렬을 구할 때에는 앞에서 소개한 SMC 값을 활용하되, 그 결과 얻어진 행렬을 자료로 삼아서 다시 공통성 추정을 계속 계산해 나간다는 논리를 따른다. 재분해법의 논리 역시 간단한 if-then 구문을 따른다. 앞에서 얻은 공통성 추정치와 새롭게 얻어진 공통성 추정치를 서로 비교하여, 만일 그 값이 기준점 이상의 차이를 보일 경우 계산을 새로 반복한다. 만일 값의 차이가 기준점 이하로 떨어지면, 축소상관행렬의 반복 계산을 종료한다. 물론 이 경우에도 한계점이 없는 건 아니다. 이쪽은 거꾸로 실제 공통성에 비해서 추정된 공통성이 과대추정되어, 그 수치가 이상하게 더 크게 나타난다고.
그리고 재분해법은 반복 분해 과정에서 수학적으로 납득할 수 없는 기이한 괴현상(?)이 나타나기도 한다. 통계학자들에 의하여 헤이우드 사례(Heywood case)라는 이름이 붙은 이 현상은, 반복 계산 도중에 어떤 지표변인의 표준화된 요인적재량이 1.0 이상으로 돌파하여 아예 설명 자체를 불가능하게 만들어 버리는 상황이다. 앞에서도 언급했지만 요인분석은 지표변인의 분산의 일부는 공통요인으로 설명하고, 나머지는 (절대 간과하면 안 되는) 고유요인으로 설명한다. 그런데 헤이우드 사례는, 즉 요인적재량이 1.0 이상으로 올라간다는 소리는, 지표변인의 분산에 추가로 유령분산(?)까지 설명해내고, 고유요인은 음수 값(…)의 분산을 설명한다는 황당한 경우다.
그러나 린드리 파브리거(L.R.Fabrigar)를 비롯한 현대의 방법론 연구자들은 이것이 딱히 재분해법의 '한계점' 이라고 보지는 않는다. 오히려 재분해 과정에서 헤이우드 사례가 나타났다면, 이는 표본 자체에 뭔가 문제가 있다거나, 모델링 자체가 부적합하다는 중요한 신호라고 고맙게 여겨야 한다는 것이다. 또한 헤이우드 사례는 이상값(outlier)이나 결측값으로 인해 발생하는 것이 아니며, 가장 적절한 조치는 표본크기를 확대하거나 지표변인의 수를 충분히 증가시키는 것이라고 조언한다.
2.1.3. 요인추출[편집]
factor extraction
이제 연구자는 축소상관행렬을 분해하여 요인적재량의 행렬을 계산하고, 여기서 고유치를 확보하여 요인의 숫자를 잠정적으로 결정해야 한다. 기존에는 관행적으로 PCA의 힘을 빌려서 이 단계를 지나가곤 했지만, 누차 언급하듯이 오늘날에는 요인분석을 한답시고 추출 단계에서 PCA를 활용했다가는 반드시 누군가에게 욕을 먹게 되어 있다(…). 그래서 관련자료를 뒤적이다가 PCA 설명을 보게 되더라도, 그것은 그저 비교 삼아서 참고하는 정도가 좋다.
머나먼 옛날, 그러니까 대략 1960년대 이전까지는 컴퓨터 계산이 존재하지 않았기 때문에, 그 시절 연구자들은 직접 공학용 계산기를 두들기면서 요인추출을 했다고 전해진다(…). 연구의 시간 당 생산성이 떨어지는 건 당연한 일. 이때 사용했던 방법이 바로 무게중심법(Centroid method)인데, 오늘날까지 이런 추출법을 활용하는 경우는 없다고 봐도 무방하다. 단, 일부 해외 교과서들에서는 무게중심법을 소개하면서, 그것이 역사적 의의가 있으며 다양한 행렬들에 범용적으로 적용이 가능하고, 요인추출을 가르치기 위한 교수법적인 가치가 크다고 평가하는 경우가 있다. 오늘날에는? 그저 SPSS에서 대화 창 하나에 클릭 몇 번으로 끝나는 단계다(…).
위에서 언급한 SMC 이야기를 이어가자면, 연구자가 만일 SMC를 활용해서 공통성을 추정했다면, 이 추정치를 바탕으로 하여 요인적재량의 행렬을 수학적으로 계산할 수 있다. 이것을 주축분해법(이하 PAF; principal axis factoring)이라고 부른다. 그리고 만일 위에서 재분해법을 활용해서 공통성을 추정했다면, 이를 바탕으로 요인적재량을 구하는 과정은 반복주축분해법(iterated principal axis factoring)이라고 부르기도 한다. PAF는 (축소상관행렬을 이용한다는 점만 빼면) 논리적으로는 PCA의 방법을 많이 참고한 티가 난다. 아래에 소개할 방법에 비해 불필요한 전제가 더 붙지 않는다는 것은 장점이지만, PAF는 추출한 요인의 수가 적절한지에 대한 적합도검정을 할 수는 없다는 한계점이 있다. PAF를 이용하고자 한다면 SPSS보다는 SAS가 더 유용하다고 알려져 있다.
현대에는 요인의 수에 대한 적합도검정, 즉 정말로 요인의 수를 이 숫자로 해도 괜찮을지에 대한 검정의 가치가 점차 커지고 있다. 그런 트렌드 속에서 힘을 얻고 있는 방법이 바로 최대우도추정법(이하 ML; maximum likelihood estimation)이다. 이것은 요인행렬 속에 있는 미지수들의 적합도를 우도함수니 수치해석 알고리즘이니 하는 복잡한 절차들로 검정하는 것으로, 행렬의 해가 지표변인들 간의 상관관계를 얼마나 잘 반영하는지 판정한다. 본질적으로 이는 분포(distribution)에 기초한 추정법이므로 이후 추정이나 적합성 검정에서 검정통계량을 활용할 수 있다는 장점을 갖지만, 그 한계점도 명확하다. 대표적으로 각 지표변인들이 다변량 정규분포, 정확히는 위샤트 분포(Wishart distribution)를 따른다는 전제가 필요하다. 위에서 요인분석의 기본 전제를 설명하면서 ③ 에서 소개한 '다변량 정규성' 에 대한 전제가 바로 이것이다. 뒤집어 말하면, PAF를 사용할 연구자는 요인분석의 기본 전제가 하나 풀린 덕에 운신이 더 편해지는 셈이다.
ML의 또 다른 문제는, 분석가는 요인의 수를 몰라서 요인을 추출해야 되는데, ML로 요인을 추출하려면 사전에 요인의 수를 알고 있어야 한다는 모순적인 상황이 발생한다는 것이다(…). 요인분석에 처음 입문하는 사람이 머리를 움켜잡는 주요 지점 중 하나. 그래서 SPSS에서도 ML을 지정할 경우에는 별도로 요인의 수를 사전에 입력하는 창이 활성화되는 걸 볼 수 있다. 하지만 현실적으로 요인분석을 실시하는 연구자들은 의외로 맨땅에 헤딩하는 식으로 요인의 수를 찾지는 않는다. 이럴 때 연구자들이 도움을 받는 것이 바로 선행문헌의 존재, 그리고 무엇보다도 이론적 조망이다. 이론이 예측하는 만큼 요인의 수를 정해주고, 그에 맞게 요인을 '일단' 추출해 놓은 뒤, 자신이 추출한 결과가 정말 적합한지를 나중에 따져봐서 결정하게 되는 것이다. 바로 밑에 서술하겠지만, ML을 사용했을 때에는 요인의 수를 결정할 때에 활용할 기준이 조금 더 많아진다.
2.1.4. 요인 개수의 결정기준[편집]
요인들이 추출되었다면 이제 일정한 기준에 의거해서 최종적으로 자신이 인정할 요인의 수를 결정할 차례다. 은근히 헷갈릴 수 있는 것인데, 없는 요인을 분석가가 '만드는' 것이 아니다. 원론적으로 요인의 수는 지표변인의 수만큼 뽑아져 나올 수 있다. 분석가가 하는 일은 그 중에서 자신의 해석에 '포함시켜서' 평등하게 취급할 요인을 몇 개만큼 선택할지의 문제다. 그리고 나머지 '찌꺼기' 요인들은 전부 고유요인으로 치워버리는 것이다. 당연히 여기서도 선행연구를 계속 의식해야 하며, 선행연구에 비추어 뜬금없는 것이라면 빼는 쪽에 무게를 두거나, 선행연구에 비추어 예상대로 나온 것이라면 좀 약해 보여도 그 요인까지 포함하는 쪽에 무게를 두어 결정할 수 있다. 요인의 수는 아무리 많더라도 대개 지표변인 수의 1/3 정도를 넘어가지 않는 것이 좋다고 알려져 있다.
PCA의 영향을 받은 연구자들은 누적분산비율(cumulative proportion of variance)을 활용하기를 선호한다. 이것은 고유값을 고유값의 총합으로 나눈 분산비율(proportion of variance)을 이용하여, 각 요인들을 하나씩 하나씩 추가해 갈 때마다 누적적으로 산출되는 분산비율이 충분히 높은 수치에 도달하면 요인의 추가를 종료하는 방식이다. 당연히, 지표변인이 N개라면 N번째로 계산되는 마지막 누적분산비율은 1.0이 된다. 분석가는 그 이전에 적당한 시점에서 요인의 추가를 종료하게 되는데, 대개 그 비율이 .70 ~ .80 정도에 도달하면 '이 이후로는 새롭게 요인을 추가해 봤자 충분히 더 많은 분산을 설명할 수 있다는 실익이 없다' 고 판단하고 종료한다. 이런 방식은 기술통계학의 누적데이터 보고를 연상시키는 등 익숙한 논리를 따르지만, 요인분석의 논리와는 서로 잘 맞지 않는다 하여 부정적으로 보는 방법론 연구자들이 있다.
다음으로, 위의 김 씨가 예시에서 참고했던 자료인 스크리도표(screeplot)를 살펴보자. 여기서 scree란 보통 '자갈', '잔돌' 등을 의미한다. 혹시 성격테스트라고 하여 MBTI나 에니어그램과 비슷해 보이는 것으로 "16PF" 를 들어보았는지? 이것은 레이먼드 카텔(R.B.Cattell)이라는 초창기 성격심리학자가 Big5가 있기 전에 성격을 요인분석한 결과물이며, 그 과정에서 제안한 것이 바로 스크리도표다.[19] (한번 더 언급하지만 요인분석은 심리학에 정말 큰 빚을 지고 있다.) 이 도표는 N개의 요인들을 그 고유값의 크기 순으로 정렬해서 x축에 나열하고, y축에는 각각의 요인이 갖는 고유값을 표시한다. 분석가는 왼쪽으로부터 시작하여 오른쪽의 어느 정도까지를 요인으로 인정할지 고르게 된다.

스크리도표를 활용하면서 가장 단순하고 직관적인 방법은, 도표 상에서 소위 "꺾이는 부분"(sharp drop & levelled off)이 어디인지를 찾는 것이다. 이 지점은 그 모양새 때문에 팔꿈치(elbow)라고도 불린다. 보통 스크리도표에서 꺾은선그래프가 평평해지는 지점은, 많은 요인들이 사소한 고유값을 서로 엇비슷하게 갖기 때문에 전부 반영하기 뭣하니 싹 버리자고 판단하기가 쉬운 지점이다. 이것은 아마도 요인분석에서 요인 개수를 결정하는 가장 쉬운 방법이겠지만, 그 한계점도 명확하다. 무엇보다도, 너무 주관적이라는 게 문제다. 똑같은 부분을 보면서 어떤 분석가는 "이 정도면 꺾이는 부분이 맞네!" 라고 말하지만, 다른 분석가는 "이게 어딜 봐서 꺾이는 부분이야?" 라고 말할 수도 있다. 게다가, 꺾이는 부분이 한 군데만 나타난다는 보장도 없다. 당장 위의 예시 도표를 보자. 꺾이는 부분을 기준으로 생각한다면, 분석가는 이 요인모형을 단일요인 모형으로 취급할지, 아니면 3요인 모형으로 취급할지 난감하게 될 것이다. 게다가 이걸 단일요인으로 본다면 요인2 이후로는 싹 버린다는 말이 되는데, 그건 너무 아깝지 않은가?
다행히, 그보다 더 나은 다른 방법들이 많이 있다. 그 중에서 아마도 가장 유명하고 많이 쓰이지만 그만큼 엄청나게 욕을 먹는 방법(…)이 있다. 위에서 김 씨가 그랬듯이, 요인을 떨구는 커트라인을 일괄적으로 1.0 으로 잡는 것이다. 이 방법은 Kaiser-Guttman 방법 또는 1 이상 규칙(greater-than-one rule)이라고 불리는데, 기존에 떠돌던 아이디어를[20] PCA에 적용하려던 문헌에서 유래했다.[21] 이 논리에서는, 하나의 주성분이 설명하는 분산의 양이 하나의 변인의 분산, 즉 1.0보다 작다면 과연 그것이 PCA에서 무슨 의미 있는 통찰을 주겠느냐는 논리를 따른다. 이처럼 방법 자체가 PCA에서 유래하므로, 축소상관행렬이 아닌 일반적인 상관행렬만 있어도 분석할 수 있다. 게다가 이 방법, 스크리도표와 궁합이 너무나도 잘 맞는다!
고유값 1.0 이상의 요인만 인정하자는 기준은 현실적으로 가장 흔한 방법이며 SPSS에서도 기본으로 지정되어 있지만, 문제는 이 역시 한계가 너무 크다는 것. 한 문헌에서는[22] 아예 더 이상 요인분석에서 이 방법은 절대 쓰지 말아야 한다고까지 주장했다. 우선, 1.0 이하의 고유값이라 해도 해석이 가능할 수 있다. 실제로 PCA에서 이것이 가능함을 보인 문헌이 있다.[23] 그리고, 자칫 요인을 너무 많이 인정할 수 있다. 당장 위의 예시 도표를 보자. 1.0 기준을 잡을 때 분석가는 꼼짝없이 5요인 모형을 받아들여야 한다. 그리고 일단 선정된 이상, 5개의 요인들은 평등하게 취급되어야 한다. 하지만 정말 그래야만 하는가? 분석가는 그보다는 3요인 모형이 훨씬 더 낫다고 믿고 싶을 수도 있다. 이에 대한 대답은
스크리도표를 활용하면서 뭔가 좀 더 설득력이 있는 기준을 찾으려는 노력 중에서 가장 괜찮은 것으로 Horn의 방법이 있다.[24] 이 논리를 따라가자면, 먼저 아예 아무런 상관 자체가 존재하지 않는 완전한 무선적 데이터(random data)로부터 얻어진 수평의 그래프를 그리고, 실제로 자신이 분석하는 데이터 세트로부터의 스크리도표를 겹쳐 그린다. 분석가는 여기서 무선적 데이터가 보여주는 그래프 위로 올라가는 고유값을 갖는 요인만 채택하며, 두 그래프가 교차한 우측으로는 전부 기각한다. 보다시피 이 방법은 가장 합리적이지만 대중적이지 않으며, SPSS에서도 미구현되어 있다. 또한 이것 역시 어느 정도는 "엿장수 맘대로", 즉 분석가의 재량에 의존할 수밖에 없다. 위의 예시 도표에서 만약 (그럴 리 없겠지만) 무선적 그래프가 정확히 2.0 높이에서 그려진다면, 분석가는 이걸 2요인으로 보는 한편으로 3요인 구조를 인정하고 싶은 마음 사이에서 갈등할 수 있다. 특히나 요인3이 이론적 근거가 있을 때에는 더욱 그렇다.
스크리도표를 활용하지 않는 결정기준들도 있다. Velicer의 방법은[25] 위에서 소개한 논란 많은 Kaiser 방법을 대체할 것이라고 주목되었으며, Kaiser 방법과 마찬가지로 PCA의 논리, 그 중에서도 부분상관(partial correlation)을 빌려왔다. 이 방법이 제시하는 최소평균부분치(이하 MAP; minimum average partial)를 활용할 경우, M개의 주성분이 있을 때 하나씩 하나씩 추출되는 주성분들을 계속 통제(partial out)해 나가면서 나머지 변인 간 부분상관을 확인하게 된다. 즉, 이미 추출된 주성분은 '통제되었다' 고 생각하고 치워놓은 뒤, 나머지 분산끼리의 상관을 계속 구해보자는 것이다. 결과적으로 MAP는 이렇게 얻어진 부분상관들을 제곱한 뒤 상관행렬 내에서 평균을 구하고, 이 평균부분치(average partial)가 충분히 최소화되는 순간에 주성분의 추가 추출을 종료하는 것이다. 말이야 복잡하지만, 일정한 숫자를 염두에 두고 똑같은 계산을 계속 반복하다가 마침내 그 숫자에 도달하면 반복계산을 종료한다는 논리는, 여기까지 읽어 내려오면서 계속 보아 온 if-then 구문을 따름을 알 수 있다.
이런 반복계산의 논리를 쓰는 것 중에서 아마도 꽤나 유명할 방법으로서 카이자승 반복검정을 활용하는 것이 있다. 여기서는 먼저 영가설을 "모집단 내에 M개의 요인이 존재한다" 로 정하고, 대립가설을 "모집단 내에 M개 초과의 요인이 존재한다" 로 정한 후에 카이자승 검정으로 어느 쪽을 기각할지를 확인한다. 이때 검정 결과 얻어진 카이자승 값이 작을수록 p-값은 커지게 되며, 그 크기에 따라 판단이 갈린다. ① 그 값이 p>.05 만큼 커서 영가설을 기각할 경우, 이때는 새롭게 영가설을 "모집단 내에 M+1개의 요인이 존재한다" 로, 대립가설을 "모집단 내에 M+1개 초과의 요인이 존재한다" 로 세워서 카이자승 검정을 다시 시행한다. 만약 ② 그 값이 p<.05 로 너무 작아서 영가설을 기각하지 못할 경우, 이때까지 확보된 요인의 수를 자신의 모형에서 허용할 수 있는 요인의 최대의 수로 이해하고 반복검정을 종료한다.
카이자승 반복검정을 활용하는 것 역시
앞에서 ML을 소개하면서 잠깐 언급했지만, 분석방법으로 ML을 쓸 때에는 사전에 결정한 요인의 수를 판단할 기준이 하나 더 따라붙는다. 흔히 Tucker-Lewis 지표라고 불리는 수치인데,[26] 아예 요인구조가 존재하지 않는 상황에 비해서, 분석가가 추출한 요인모형이 그 상황보다 얼마나 많이 개선된 것인지를 알려주는 신뢰도 계수다. (CFA에 대한 지식이 이미 있다면, CFA에서의 모형적합도 검정의 논리와도 꽤나 유사함을 알 수 있을 것이다.) 이 수치는 0 ~ 1 사이의 값으로 나타나며, 일반적으로 받아들여지는 임계치는 .90 정도이고, 그 미만으로 계수가 산출되면 요인을 하나 더 추가해 놓고 수치가 얼마나 증가했는지 다시 봐야 한다.
Tucker-Lewis 지표는 가급적이면 .95 이상으로 올라가지 않게 해야 하는데, 이는 이 기준조차도 한계점을 안고 있기 때문이다. 이 숫자는 분석가가 정신줄 놓고 요인을 계속 추가하고 있으면 1.0 에 수렴하는 방향으로 일관되게 증가하기만 한다. 따라서 그 수치가 .95 이상으로 올라가는 구간에서는 새롭게 추가된 요인이 갖는 해석상의 의미가 거의 소멸되어 버리고, 심지어는 표본 자체의 특징을 하나의 요인으로 간주하는(…) 상황도 벌어진다. 다시 말해, 하필이면 그 표본집단이었기에 나타난 특징까지도 의미 있는 요인이 된다는 것이다. 대신에 다른 요인 개수 선정기준들과 병행할 경우, Tucker-Lewis 지표는 상당한 도움이 된다. 예컨대 4요인 모형과 5요인 모형 사이에서 고민하고 있는 연구자에게, 4요인에서 이미 Tucker-Lewis 지표가 .93에 도달했다는 정보는 매우 결정적이기 때문이다.
이쯤에서 마지막으로, 아까 그 레이먼드 카텔의 16PF 이야기. 카텔이 '성격' 개념을 요인분석했다는 것은 알겠는데, '16' 이라는 숫자가 도대체 무엇일까? 맞다, 이 양반이 분석에 반영하기로 결정한 요인의 개수다(…). 2020년대로 접어드는 현대의 관점에서 이런 요인분석을 시행했다면 욕을 배불리 먹고 장수했겠지만(…), 그 시절에는 뭘 어떻게 연구해 봐야 한다는 가이드라인 자체가 없었기 때문에 이런 분석이 가능했다. 현대의 후배 방법론 연구자들이 16PF에 대해서 CFA 내지 반복분석을 실시해 보면, 실제로 의미가 있는 요인의 수는 최대한 관대하게 쳐 줘도 9개도 많은 수준이라고 한다. 이 문서 서두에서 못박았듯이, 요인분석의 목적은 복잡하고 추상적인 연구대상을 간단 명료하게 요약 정리하는 데 있다. 그렇다면 카텔의 16PF는 현대의 기준에서 보면 그다지 좋은 분석은 되지 못했던 셈이다.
2.1.5. 요인회전[편집]
factor rotation
자, 이제 분석가는 드디어 요인의 개수도 정했고, 그 요인들의 요인적재량을 나타내는 요인행렬도 얻어냈다. 하지만 위의 김 씨가 느꼈던 것처럼, 지금 분석가가 갖고 있는 요인행렬은 그 자체로는 해석하기가 너무나 난감하다. 이걸 조금이라도 더 손쉽게 해석할 수 있는 방법이 없을까 고민하던 옛날 통계학자들은 행렬의 각 성분들을 기하학적 공간 속에서의 좌표로 생각하자는
다시 말해, 여기서 요인을 회전한다는 것은 요인행렬을 좌표계 위에서 새롭게 생각한다는 의미다. 이때 행렬의 각 성분들은 좌표축에 최대한 근접할수록 내용적 해석이 간편해지므로, 요인의 회전 목적은 최초 주어진 요인행렬, 즉 기초구조(initial structure)를 수학적으로 회전시키면서 가장 해석이 쉬운 요인행렬, 즉 최종구조(final structure)를 산출하는 데 있다. 여기서 내용적 해석이 쉽다는 말은, 그 성분의 값이 1.0에 가깝게 확실하게 크거나 아니면 0에 가깝게 확실하게 작다는 의미로, 행렬 속에 가능하면 소수의 아주 큰 값과 다수의 아주 작은 값들이 많아야 한다는 것이다. 분석가는 조금씩 회전을 시키면서 엄청나게 많은 동치모형 요인행렬들을 비교하게 되고, 그 중에서 가장 '예쁘게 나온' 행렬을 고르면 된다.
결국 이렇게 본다면 요인의 회전도 역시나 뭔가 휘황찬란한 통계적 테크닉 같지만, 이조차도 그저 (심하게 말하자면) 분석가의 해석의 편의를 위해서 부가적으로 실시하는 '예쁘게 정리하기' 수준밖에는 안 되는 셈이다. 수학적으로 보아 회전 이전의 기초구조와 회전 이후의 최종구조는 서로 완벽하게, 정말 완벽하게 동등한 가치를 갖는다. 단지 인간의 머리로 이해하기에 전자보다는 후자가 좀 더 설명이 편할 뿐이다. 정말 간혹가다 (가능성은 거의 없겠지만) 회전 자체가 필요없는 단순구조(simple structure)의 형태로 나타나는 요인행렬이 처음부터 갑툭튀할 수도 있다. 물론 대부분은 회전이 필요하겠지만, 그런 가능성 자체가 이미 회전이라는 것이 수학적으로 새로운 정보를 내놓는 엄연한 절차라기보다는 그저 분석을 위한 보조 도구라는 느낌을 준다.
요인회전에는 아래의 두 가지 방법이 있다. 이 두 가지 중에서 어느 쪽을 택해야 할지도 논쟁이 많다.


먼저 언급할 회전방법은 직각회전(orthogonal rotation)이다. 간혹 '직교회전' 이라고도 불리지만, 같은 뜻이다. 직각회전은 가장 전통적이고 관습적인 방법이며, 1950년대 이래로 수많은 연구자들이 사용해 왔다. 직각회전의 핵심은 각각의 좌표축 간의 각도를 정확히 90도, 즉 직각으로 유지하여 회전한다는 데 있다. 표현을 바꾸자면, 직각회전은 요인 간의 상관계수의 값을 cosine 90, 즉 0으로 가정한다. 은근 중요한 것인데, 직각회전은 요인 간 상관이 없는 모형을 원할 때 사용하는 게 아니라, 요인 간 상관이 없다고 '가정하는' 모형을 원할 때 사용하는 것이다. 현실적으로 거의 대부분의 요인모형에서, 모든 요인들 간의 상관관계가 정확히 0이라는 발상은 비현실적이다.
좌표축을 직각으로 유지한다는 것은 알겠는데, 주어진 좌표계에서 회전의 각도를 구체적으로 얼마로 설정해야 가장 적절한 회전이 될 수 있는가? 이에 대해서는 기준들이 많이 있지만, 여기서는 그 중 일부만을 제시해 볼 것이다. 물론 SPSS 같은 통계 패키지에서도 이런 방법들을 쭉 늘어놓고 이 중에서 고르라고 한다.
- 배리맥스(VARIMAX)[27]
가장 대중적인 기준이며, 관습적으로 가장 많이 쓰이고 있다. 이 회전법은 "분산이 극대화된다"(Variance is maximized)의 약자이다. 여기서는 요인의 분산을 극대화하는 논리를 따르는데, 요인행렬을 변환할 때 행렬의 열(요인)을 기준으로 하여 큰 값은 더 크게, 작은 값은 더 작게 회전하는 길을 찾는다. 배리맥스의 도입 이후, 학계에서 다요인 구조 속의 모든 요인들의 의미가 비로소 뚜렷하게 해석될 수 있게 되었다는 역사적 공로가 있다고 한다. 아무튼 요인의 수가 꽤 많다 싶을 때 쓰기 좋은 방법이다. 참고로 학회 발표에서조차 흔히 혼동하는 것인데, '베리맥스' 가 아니라 '배리맥스' 다(…).
- 쿼티맥스(QUARTIMAX)[28]
아이디어의 역사 자체는 배리맥스보다 더 길지만, 다요인 구조에서 특히 강한 배리맥스의 장점에 밀려서 거의 병풍 취급을 받고 있는 콩라인 기준이다. 여기서는 계산 과정에서 4제곱이 활용되기 때문에 이름에 quarti- 가 붙는다. 배리맥스가 행렬의 열을 기준으로 한다면, 쿼티맥스는 행렬의 행(지표변인)을 기준으로 분산을 극대화한다. 방법론 연구자들은 쿼티맥스가 제1요인만 과대해석하고 기타 요인은 과소해석하는 문제가 있다고 비판한다. 결국, 쿼티맥스는 단일요인 구조가 존재한다는 확신이 있을 때에나 한정적으로 사용할 수 있기에, 그 범용성에서 배리맥스에 너무 현격하게 밀린다.
- 이퀴맥스(EQUIMAX)
위의 두 방안을 절충하여 행렬의 행과 열을 모두 기준으로 하는 타협안. 하지만 양쪽 모두를 만족시키는 게 아니라 양쪽 모두를 불만스럽게 했던 모양인지, 학계 현장에서는 아예 존재감이 없다시피하다.


다음으로 언급할 회전방법은 사각회전(oblique rotation)이다. 물론 이것도 '사교회전' 이라는 다른 이름을 갖고 있다. 사각회전은 원론적으로만 따지자면 직각회전보다 더 우월하다. 하지만 옛날에는 설득력 있게 회전시킬 방안이 마땅치 않았던 것도 사실인지라, 초기 연구자들은 늘 군침만 흘릴 뿐 아쉬운 대로 직각회전을 쓸 수밖에 없었다. 그러자 이후의 후학들은
사각회전의 핵심은 각각의 좌표축 간의 직각을 인정하지 않으면서 회전시킨다는 것이다. 다시 말해, 사각회전은 요인들 사이의 상관이 존재함을 받아들이고 회전에 반영한다. 당장 위의 김 씨의 분석 예시를 살펴보자. 김 씨가 도출한 3요인 모형에서는 직각회전을 했지만, 제2요인과 제3요인이 서로 완벽히 '독립적' 이라고 말할 수 있을까? 어쩌면 두 요인 사이에는 다소간의 상관관계가 존재할지도 모른다. 다시 말해, 공분산(covariance)이 존재할 수 있다. 이런 가능성에 대한 확신이 있고, 또 이것이 해석에 있어 중요하다고 생각되면, 사각회전을 사용할 수 있다.
연구자들이 사각회전에 대해 난색을 표하는 이유는 그것이 통계적 처리와 해석에 있어서 상당히 까다롭고, 더 복잡하기 때문이다. 사각회전은 일단 먼저 직각회전을 한 번 실시하면서 시작하는데, 이때 각 요인별로 가장 대표성이 있어 보이는 지표변인들을 골라서, 이들끼리 갖는 상관행렬 내의 상관계수를 가지고 좌표축을 추가로 조정한다. 즉, 요인 간 상관은 이런 '대표적인 지표변인' 간의 상관을 통해서 추정되는 것이다. 이후 얼마나 회전시켜야 할지에 대해서 하술할 몇몇 종류의 기준들을 활용하게 되는데, 지표변인 간 상관에 최대한 근접하기 위한 최적의 각도를 산출하는 것이 그 목적이다. 여기서 연구자들이 가장 비판하는 지점은 바로 '대표적인 지표변인' 을 선정하는 과정이 너무 주관적이라는 것이다.
- 직접 오블리민(Direct OBLIMIN)[29]
이 방법은 SPSS에서 구동 가능한데다 눈에 잘 띄는 곳에 있어서(…) 많은 연구자들이 채택하고 있는 메이저한 기준이다. 그 논리는 '델타' 값을 기준으로 하는데, 요인 간의 사각이 클수록 델타 값은 0에 근사하지만, 요인 간 관계가 직각에 가까울수록 무한히 큰 음수 값으로 나타난다. 분석가가 어떤 지표변인을 대표성 있다고 선정하는지에 따라서 델타 값이 달라지는 주관성 문제가 있다. 이와 유사한 것으로 프로맥스(PROMAX)가 있는데, 직접 오블리민보다 최적의 사각을 찾는 컴퓨팅 속도가 더 빨라서 대용량 데이터에 적합하다는 평가를 받는다.
- 오소블리크(Orthoblique)[30]
아직까지 이 방법은 SAS에서만 구동된다. 여기서는 Harris-Kaiser 검정력(이하 HKP) 값을 활용하며, 그 값은 0 ~ 1 사이에서 나타난다. 만일 회전 시에 요인 간의 사각이 클수록 HKP 값은 0에 근사하게 되고, 요인 간 관계가 직각에 가까울수록 1에 가까운 양수 값을 갖는다. 물론 이 방법 역시 사각회전이 갖고 있는 문제점, 대표적인 지표변인의 선정이 너무 주관적이라는 문제에서 자유로울 수 없다.
- 기하학적 각도 측정[31]
어찌보면 어이없을 정도로 가장 단순하면서도 가끔은 의외로 믿을 만한 방법. 직접 오블리민과 오소블리크 모두 요인 간 상관을 추정하는 데 있어서 주관성이 개입한다고는 하나, 만약 2차원 좌표계로 표시가 가능한 2요인 모형에서라면 구태여 그런 주관성을 혼입시킬 이유가 없지 않느냐는 문제제기에서 출발했다. 따라서 이 방법은 2요인 모형에서만 한정적으로 성립이 되는데... 준비물이 좀 필요하다. 종이, 연필, 자, 그리고 각도기. 여기서는 좌표계에서 각 성분들을 두 집단으로 묶고, 각 집단의 '중앙' 과 좌표계 원점을 잇는 직선을 두 개 그린 뒤, 두 선 사이의 각도를 구해놓고 거기에 cosine을 씌워서 요인 간의 상관 추정치를 구하는 것이다.
보다시피 편법에 가까울 만큼 단순하고 직관적이지만, 그 한계도 명확하다. 우선, 2요인 모형에서나 가능하기 때문에 3차원 이상으로 넘어가 버리는 3요인 이상의 구조에서는 쓸 수가 없다. 그리고, 각 집단의 '중앙' 이 대체 어디인지를 판정하는 과정이 명확하게 제시되지 않으면 또 다른 주관성 논란에 휩싸일 수가 있다. 즉, 다른 연구자가 나서서 "거기가 중앙이 아니라, 여기야말로 중앙이지!" 라고 따질 수 있다는 것이다.
보다시피 편법에 가까울 만큼 단순하고 직관적이지만, 그 한계도 명확하다. 우선, 2요인 모형에서나 가능하기 때문에 3차원 이상으로 넘어가 버리는 3요인 이상의 구조에서는 쓸 수가 없다. 그리고, 각 집단의 '중앙' 이 대체 어디인지를 판정하는 과정이 명확하게 제시되지 않으면 또 다른 주관성 논란에 휩싸일 수가 있다. 즉, 다른 연구자가 나서서 "거기가 중앙이 아니라, 여기야말로 중앙이지!" 라고 따질 수 있다는 것이다.
직각회전과 사각회전은 각각 장단점이 있으며, 저쪽의 장점이 이쪽의 단점이 되고, 이쪽의 장점은 저쪽의 단점이 되는 상호보완적인 관계에 있다. 따라서 이를 최대한 가독성 높게 소개하자면, 다음과 같은 표로 나타낼 수 있을 것이다. 장점은 초록색, 단점은 빨간색으로 하이라이트했다.
그렇다면, 결국 현대의 방법론 연구자들이 합의하는 것처럼, 직각인가 사각인가에 대해 너무 목맬 필요는 없다. 이것은 엄밀한 수학적인 정답이 있는 문제가 아니라, 그저 분석가들이 겪는 현실적인 실용성의 문제이기 때문이다. 다시 말해서, 분석가는 둘 중 하나를 골라야 할 때 "내 분석이 굳이 복잡한 사각회전을 해야 할 정도로 요인 간 상관이 중요시되는가?" 의 자문을 할 수 있다. 만약 요인 간 상관이 존재하리라는 확신이 있고, 선행문헌 또는 이론적 조망에 비추어 봐도 요인 간 상관을 기대할 수 있다면, 그때는 당연히 사각회전을 할 수 있다. 게다가 차후 다른 분석들을 해야 하는 상황에서는 하술할 이유로 인하여 사각회전을 해야 한다. 그러나 학계에서 관행적인 직각회전이 빈번하다고 하여, 직각회전이 무조건 생각 없는 분석이라고 몰아붙일 수도 없다는 것이다.
직각회전과 사각회전은 이분법적으로 나뉘어지지 않는다. 동일한 자료를 가지고 직각회전을 한 결과와 사각회전을 한 결과를 비교했을 때, 회전방식에 따라서 소소한 차이는 있을지언정 '극적으로 큰' 차이가 나타나는 경우는 의외로 정말 많지 않다. 이런 문제는 요인 간 상관의 크기 자체가 애매한 경우가 많다는 점에서도 두드러진다. 예를 들어 보자. 두 좌표축 간에 대략 75~80˚ 정도의 사각의 유지가 필요한 상황에서, 분석가는 직각회전을 거부하고 사각회전을 써야 하는가? 이 상황에서는 직각회전이 괜찮다고 말한다면, 65~70˚ 에서까지도 직각회전을 쓸 것인가? 결국, 모 아니면 도 식의 판단으로는 별 도움이 되지 않는다. 분석가는 자기 외부의 계량화된 임계치(?)를 찾을 게 아니라, 자신이 도출한 모형에서 요인 간 상관이 어떻게 예상되는지에 대해 자기 나름의 확고한 의견을 갖고 있어야만 한다.
...자, 이제 분석가는 마침내 EFA라는 하나의 고비를 넘어서 드디어 '최종구조' 라는 결과물을 손에 넣었다. 위의 저 복잡한 논쟁의 도가니를 거쳐서 이리저리 힘겹게 고생한 끝에 요인모형 하나를 만들어 낸 것이다. 위의 저 복잡한 논쟁들과 골치 아픈 수학적 테크닉들은 전부 타인을 조금이라도 더 설득해 보기 위해서 끌어온 논리들이었다는 점에 주목해야 한다. 그 덕분에, 이제 이 결과물은 '방구석에서 풀어낸 썰' 과는 질적으로 차원이 다른, 통계적 근거를 갖고 있는 엄연한 '모형' 이 되었다. 하지만 여기서 끝이 아니다. 분석가는 이제 겨우 절반만 왔을 뿐이다. 지금 분석가가 갖고 있는 모형은 기껏해야 가설 정도에 불과하다. 이제 이 모형이 정말 제대로 만들어졌는지 확인하려면 CFA의 도움을 빌려야 한다. 그렇지 않고는 EFA 결과물을 논문이나 학회 발표의 형태로 학계에 알릴 수조차 없다. 앞으로 갈 길이 한참 먼 것이다(…).
2.1.6. SPSS에서의 EFA[편집]
비록 EFA의 대세가 SAS를 활용하는 것이라곤 하지만, SPSS를 꾸역꾸역 쓰는 분석가들도 분명 많이 있다. 이하의 순서를 따라가면 SPSS에서 EFA를 시행하는 것이 가능하다. 물론 이 내용은 가장 일반적인 경우일 뿐이고, 분석가가 처한 상황이나 여건, 분석목적 등에 따라서 세부적인 여부는 달라질 수 있다. 또한 SPSS 버전에 따라서 다소 달라질 수도 있음에 유의할 것.
요인분석에 있어서 SPSS가 초창기에 욕을 많이 먹었다(…). 몇 가지 이유가 있는데, 우선 당시에는 사전 공통성 추정에 있어서 SMC를 활용한 단일분해를 사용자가 명령할 수 없었고, 무조건 재분해법으로만 고정되어 있었다. 이는 추출할 요인의 수에 비해 지표변인의 수가 충분히 적을 때 문제가 될 수 있었다. 그리고 그보다도, 초기 SPSS는 고유값 계산에 있어서 ML이 아니라 PCA의 논리에 의존하였기 때문에 엄청난 혼동을 불러일으켰다. 이후 버전업을 하면서 PCA가 디폴트값이 되고 사용자가 공통요인 추정방식을 ML로 바꿔줄 수 있도록 하긴 했지만, 이는 통계적으로 여전히 옳지 않은 배치다. 공통요인모형 자체가 PCA와는 서로 다른 것이기 때문에, 공통요인분석 대화 창에 PCA는 존재해서는 안 되기 때문이다.
그 외에도 한글 번역판에서는 요인회전 기준들의 용어들을 전부 '~멕스' 로 이상하게 번역했다는 문제가 있다.
2.2. 확인적 요인분석(CFA)[편집]
CFA를 실시하려는 분석가는 전혀 다른 세계에 직면하게 된다. EFA에 비해서 CFA는 그 방법론적인 정립이 상당히 늦은 편이며, (늦었다 해도 짧게 잡아야 수십 년이지만) 모형에 대한 검토이기 때문에 EFA에서 익숙하게 논의하던 그것과는 생판 다른 분야의 논의의 도움을 받아야 한다. 비유하자면, 분석가는 '복잡한 자료를 정리하여 요인을 추려내는' 세계에서 벗어나, 본격적으로 "모형나라" 에 입국하게 되는 것이다. 그리고 모형나라 입국심사장에서 요인모형은 '반영지표모형' 이라는 도장을 받았고, 분석을 원한다면 '구조방정식 모형' 이라는 모형분석법을 따르라는 조언을 받은 것이다.
이제부터는 더 이상 SPSS의 도움을 받을 필요가 없다. 새로 AMOS라는 분석 패키지가 분석가를 도와줄 것이다. CFA의 세계에서는 통계적 기본 전제도 새로 추가된다. 분석 과정에서 더 이상 PCA가 섞여들지는 않는지 신경 쓸 필요도 없다. 심지어 CFA에서는 용어 하나하나조차 다 다르다. 지금까지 내려오면서 배웠던 "공통요인" 이니, "고유값" 이니, "요인적재량" 이니, "축소상관행렬" 이니 하는 것들은 이제부터는 더 이상 쓸모가 없다. 그냥 여기서부터는 아예 새롭게 모델링(modeling)에 대해 배우기 시작한다고 봐도 될 정도로 생소한 논의가 시작된다.
그러면 이제 새롭게 CFA에서 사용되는 용어들을 살펴보기로 하자(…).
- 관측변인(observed variable)
측정변인이라고도 한다. 앞에서 우리가 줄기차게 거론했던 "지표변인" 이 바로 이것이다. AMOS 환경에서는 사각형으로 출력된다.
- 잠재변인(latent variable)
앞에서 '요인' 이라는 단어의 주관성을 싫어하는 사람들이 잠재변인이라는 이름으로 부른다는 서술을 기억했다면, 이 용어가 익숙할 것이다. 모형나라에 입국한 요인모형은 '요인' 이라는 단어를 전부 '잠재변인' 으로 번역해야 한다. AMOS 환경에서는 원형으로 표시된다.
- 외생변인(exogeneous variable)
- 내생변인(endogeneous variable)
모형 속에서 한 번 이상 다른 변인에 의해 직간접적 영향을 받는 변인이다. 이 역시 회귀분석의 종속변인 y를 생각하면 편하다. 모형 속에서 화살표가 하나 이상 꽂히는 모든 변인이 내생변인으로 분류된다.
- 측정오차(measurement error)
잠재변인으로 설명할 수 없는 오차로, 관측변인 쪽에 화살표로 연결한다. AMOS 상에서 화살표가 꽂히는 모든 관측변인들에 무조건 오차항 e를 꽂아줘야 한다. 어떤 교과서에서는 화살을 맞았으면 피를 흘린다는 표시를 해야 한다고 비유했다. 즉 e → □ 형태로 나타난다.
여기서 측정오차란 일반적인 질문지법 같은 조사방법론에서 말하는 그런 측정오차가 아니다. 조사방법론에서의 측정오차는 '응답자가 문항의 질문을 거꾸로 이해하는' 등의 오차를 말하지만, 여기서는 그런 식의 오차가 완벽하게 통제되었더라도 각 응답의 값들이 불일치하기 때문에 자연히 발생하는 오차가 존재한다고 본다. (물론 조사방법론 상의 오차 역시 통계적인 측정오차에도 영향을 끼칠 수 있긴 하다.) 즉, '비신뢰성' 같은 하나의 개념에 대해 '믿을 수 없는', '무책임한', '아는 체하는' 식으로 다수의 문항이 배치되었다면, 응답자는 각 문항들에 대해 조금씩 서로 다르게 응답하게 될 수 있는데, 바로 여기서 발생하는 오차를 말한다. 통계적 방법에 익숙하다면 이쯤에서 직감적으로 문항 간 신뢰도를 떠올릴 수 있을 텐데, 실제로 문항 간 신뢰도가 높을수록 측정오차가 감소하며, 이를 통해 잠재변인(즉 요인)이 관측변인의 응답을 설명하는 양이 크다고 해석할 수 있다. 표현을 달리하면, 관측변인 간의 유사성은 신뢰도로 평가하고, 잠재변인 간의 유사성은 타당도로 평가한다고도 할 수 있다.
여기서 측정오차란 일반적인 질문지법 같은 조사방법론에서 말하는 그런 측정오차가 아니다. 조사방법론에서의 측정오차는 '응답자가 문항의 질문을 거꾸로 이해하는' 등의 오차를 말하지만, 여기서는 그런 식의 오차가 완벽하게 통제되었더라도 각 응답의 값들이 불일치하기 때문에 자연히 발생하는 오차가 존재한다고 본다. (물론 조사방법론 상의 오차 역시 통계적인 측정오차에도 영향을 끼칠 수 있긴 하다.) 즉, '비신뢰성' 같은 하나의 개념에 대해 '믿을 수 없는', '무책임한', '아는 체하는' 식으로 다수의 문항이 배치되었다면, 응답자는 각 문항들에 대해 조금씩 서로 다르게 응답하게 될 수 있는데, 바로 여기서 발생하는 오차를 말한다. 통계적 방법에 익숙하다면 이쯤에서 직감적으로 문항 간 신뢰도를 떠올릴 수 있을 텐데, 실제로 문항 간 신뢰도가 높을수록 측정오차가 감소하며, 이를 통해 잠재변인(즉 요인)이 관측변인의 응답을 설명하는 양이 크다고 해석할 수 있다. 표현을 달리하면, 관측변인 간의 유사성은 신뢰도로 평가하고, 잠재변인 간의 유사성은 타당도로 평가한다고도 할 수 있다.
- 구조오차(structural error)
이 오차는 기존 모형의 내/외생변인만으로는 설명할 수 없는 부분, 즉 모델링 분석의 주제에서 벗어나는 오차를 말한다. 모형에서 하나 이상의 화살표가 꽂히는 내생변인에 연결한다. AMOS 상에서 화살표가 꽂히는 모든 잠재변인들에 무조건 오차항 x를 꽂아줘야 한다. 즉 x → ○ 형태로 나타난다. 이 오차는 유난히 이름이 많은데(…), 교란(disturbance), 예측오차(prediction error), 또는 방정식 오차(equation error)라고 불리기도 한다.
- 재귀모형(recursive model)
전체적인 모형에서 y가 하나만 존재하며 모형 전체의 논리의 흐름이 일방향적인 경우를 말한다. 즉, 모형 속의 화살표를 따라갈 경우 '왔다갔다하는' 지점이 나타나지 않는다. 다른 이름으로 '일방향 모형'(uni-directional model), '방향 비순환 그래프'(DAG; directed acyclic graph)라고도 한다.
- 비재귀모형(non-recursive model)
전체적인 모형에서 y의 숫자가 두 개 이상이고 모형 전체의 논리의 흐름이 쌍방향적인 경우를 말한다. 즉, 모형 속의 화살표를 따라갈 경우 어딘가에서 서로에게 엮인 화살표 때문에 끝없이 '왔다갔다하는' 상황이 발생할 수 있다. 다른 이름으로 '상호적 모형'(reciprocal model), '방향 그래프'(directed graph; digraph)라고도 한다.
- 측정모형(measurement model)
관측변인과 잠재변인 사이의 상관관계를 설명하는 모형으로, CFA를 실시하려는 연구자는 당연히 측정모형에 입각해서 모델링을 다루게 된다. AMOS 환경에서는 ○ → □□□ 형태의 모형이 바로 측정모형이 된다.
- 구조모형(structural model)
여러 잠재변인들 간의 인과관계를 화살표로 연결해서 제시하는 모형으로, 이쪽은 경로분석의 논리에 해당한다. AMOS 환경에서는 ○ → ○ 형태로 엮일 수 있다.

- 조형지표모형(formative indicator model)
다른 이름으로 원인지표모형(causal indicator model)이라고도 한다. 관측변인과 잠재변인 사이에 인과성을 전제하되, 관측변인이 원인이고 잠재변인이 결과가 된다. AMOS 상에서 □ → ○ 형태가 바로 조형지표모형이다. 여기서는 구조오차의 존재를 반영한다. 조형지표모형에서 관측변인들이 일관될 필요는 없고, 관측변인 간의 상관관계가 항상 높지는 않지만 화살표로 무조건 표기되며, 화살표를 함부로 제거하지 않는다. 단, 조형지표모형이 개념적으로나 실용적으로나 그다지 좋지 못한 모델링이라는 의견도 있다.[33]
AMOS 환경에서 조형지표모형을 만들려면 해당 경로의 가중치 중 하나를 1.0으로 무조건 고정해 놓고 그 구조오차의 분산을 0으로 설정하면 된다. 이처럼 AMOS는 조형지표모형에는 약한 모습을 보이기에, 이쪽으로 분석하려는 분석가들은 대안적 소프트웨어로서 SmartPLS, RAMONA 등을 선호한다.
AMOS 환경에서 조형지표모형을 만들려면 해당 경로의 가중치 중 하나를 1.0으로 무조건 고정해 놓고 그 구조오차의 분산을 0으로 설정하면 된다. 이처럼 AMOS는 조형지표모형에는 약한 모습을 보이기에, 이쪽으로 분석하려는 분석가들은 대안적 소프트웨어로서 SmartPLS, RAMONA 등을 선호한다.
- 반영지표모형(reflective indicator model)
다른 이름으로 효과지표모형(effects indicator model)이라고도 한다. 관측변인과 잠재변인 사이의 인과성은 똑같이 전제하지만, 잠재변인이 원인이고 관측변인이 결과가 된다. AMOS 상에서 ○ → □ 형태가 바로 반영지표모형이다. 여기서는 측정오차의 존재를 반영한다. 반영지표모형에서 관측변인들은 일관되며, 따로 표시하지는 않더라도 서로 간의 상관관계가 높고, 그 대신 개념의 타당화가 매우 중요하다. 앞에서 EFA를 유심히 보았다면 느끼겠지만, 요인모형은 그 논리 자체가 반영지표모형과 호환된다. 따라서 모델링 연구자들은 CFA를 반영지표모형의 분석으로 이해한다. 따라서 요인분석가 입장에서는 이쪽에다 별표 세 개쯤 쳐 줘야 한다는 것이다.
이제부터 한 단계 더 복잡하게 꼬아 놓은(…) 모형들을 살펴보자.


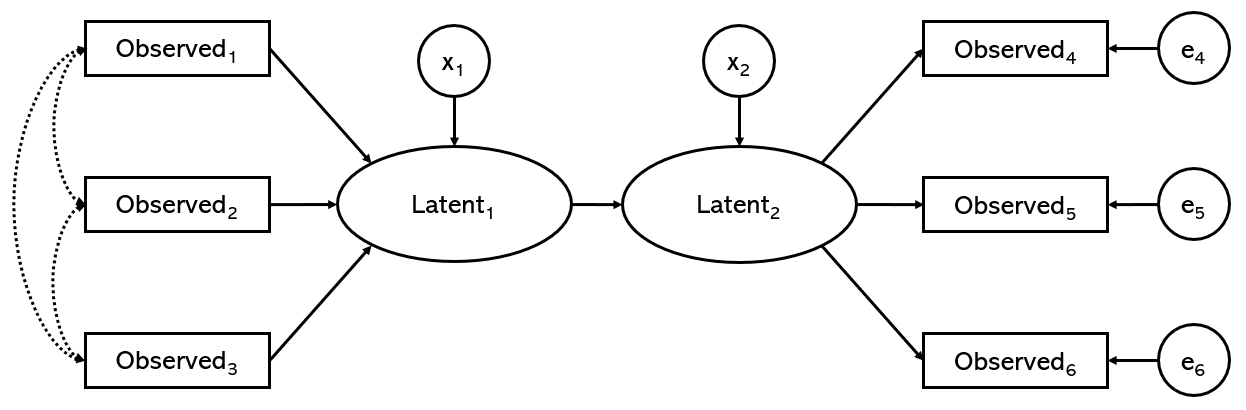
- 다중지표 모형(multiple indicator model)
다수의 관측변인을 통해서 2개 이상의 잠재변인을 생성하고, 그 잠재변인들 간의 인과관계를 화살표로 표시한다. 위에서 보았던 반영지표모형을 2개 연결해 붙여놓은 모양새라고 볼 수 있다. 즉, 요인모형 두 개를 연결해 놓고 이 요인이 저 요인의 원인이 된다고 설명하려는 모형이다.
- 다중지표 다중원인 모형(이하 MIMIC; multiple indicator multiple cause model)
다중지표 모형에서 특히 잠재변인에 영향을 주는 다른 관측된 외생변인들이 다수 존재하는 모형이다. 이 외생변인들 간의 상관관계도 확인해 보아야 하므로, 서로간에 화살표로 표시하게 된다. 결과적으로, 위에서 보았던 반영지표모형과 조형지표모형을 연결해 붙여놓은 모양새라고 볼 수 있다.
- 부분최소제곱 경로모형(이하 PLS-PM; partial least square path model)
위의 다중지표 모형과 MIMIC을 다시 섞었다(…). 잠재변인 간의 인과관계를 반영한다는 점은 다중지표 모형과도 같지만, 잠재변인에 영향을 주는 외생변인들을 관측했다는 점에서는 MIMIC과도 같다.
만약 PLS-PM에 대해서 '난 CFA만 알면 되는데 뭐 이런 것까지 알아야 하냐' 는 불만을 가졌다면, 그 불만을 갖고 있는 사람은 혼자만이 아니라는 사실에 안도해도 좋을 것이다(…). CFA를 시행하는 분석가들이 종종 모델링 과정에서 채택하긴 했지만, 일각에서는 CFA에 이것이 잘 어울리지 않는 방법이라는 지적을 하고 있다. 국내의 모델링 전문 교수들에 따르면, PLS-PM은 잠재변인과의 인과성 계산을 위해 공분산이 아닌 주성분을 바탕으로 하므로, 오히려 합성모형(composite model)이라는 다른 종류의 모형 분석에 적합하다고 한다.
만약 PLS-PM에 대해서 '난 CFA만 알면 되는데 뭐 이런 것까지 알아야 하냐' 는 불만을 가졌다면, 그 불만을 갖고 있는 사람은 혼자만이 아니라는 사실에 안도해도 좋을 것이다(…). CFA를 시행하는 분석가들이 종종 모델링 과정에서 채택하긴 했지만, 일각에서는 CFA에 이것이 잘 어울리지 않는 방법이라는 지적을 하고 있다. 국내의 모델링 전문 교수들에 따르면, PLS-PM은 잠재변인과의 인과성 계산을 위해 공분산이 아닌 주성분을 바탕으로 하므로, 오히려 합성모형(composite model)이라는 다른 종류의 모형 분석에 적합하다고 한다.
보다시피 CFA가 헤쳐나가야 하는 모형의 세계는 지금까지 이야기했던 EFA의 세계와는 너무나 다르다. 여기까지 겨우 각 용어들을 정리했으니(…) CFA에 필요한 기본 전제들을 살펴볼 수 있을 것이다.
- EFA와 동일한 전제들
- 인과성 : 여기서도 모형 속 모든 변인 간의 논리적 관계는 인과성을 따른다고 가정한다.
- 선형성 : 여기서도 모형 내의 모든 외생변인과 내생변인 사이의 관계가 선형적이라고 가정한다. 즉, 모형 내의 모든 변인들은 등간 혹은 비율 수준이어야 한다. 다만 더미(dummy)화한 이분형 자료(dichotomous data)에 한해서는 사용 가능하긴 한데, 해석이 어렵다.
- 다변량 정상성 : 여기서도 ML이 등장한다. 따라서 EFA에서와 똑같이, 다변량 정상성을 가정해야만 한다.
- 새롭게 추가되는 전제들
- 식별(identification) : 모형 내의 모든 정보의 수는 모수의 수와 같거나 혹은 더 크다고 가정한다. 다시 말해, 적정식별 또는 과잉식별 중 하나가 반드시 성립함을 참이라고 전제한다. 표현을 바꾸면, 모형 내 자유도(degree of freedom)는 0 또는 그 이상의 양수로 나타나야 한다.
- 오차변인 간의 독립 : 모형 내의 모든 오차변인들은 서로 상관이 존재하지 않는다고 가정한다. 따라서 모형을 그릴 때 오차항 e끼리 서로 연결하는 화살표를 그으면 안 된다.
EFA의 결과물을 가지고 CFA를 시작하려면, 먼저 EFA 분석을 위해 SPSS에게 출력을 요청했던 것 중에서 요인 점수(factor score)라는 것을 재료로 삼아야 한다. 요인 점수란, 분석된 요인들이 요인행렬의 계산을 통해서 다시 변인화된 수치로서, 이후 회귀분석이나 판별분석, 군집분석 등의 다른 후속 작업을 위해 사용될 수 있는 결과물이다. 특히 CFA를 시작하기 위해서도 요인 점수가 반드시 필요하다. 요인 점수의 각 수치들은 각 지표변인들이 N개의 요인들에 대해 갖는 표준화된 계숫값에 가중치를 곱한 것인데, 이를 해당 지표변인에 대한 변인으로 취급할 수 있다. 물론 CFA 이후에도 요인 점수를 다시 생성할 수 있지만, AMOS에서는 그저 가중치 값만을 제공할 뿐, 이를 일일이 곱해주는 건 분석가가 알아서 해야 한다(…).
이제야 비로소 CFA에 대해 설명할 차례가 되었다. CFA는 EFA의 결과를 통해 얻어진 요인모형을 가설로 설정하고, 동일 모집단에서 새로운 표본을 다시 추출하여 그 가설적 모형이 얼마나 적합한지를 검정하는 과정이다. 방법론 강의 중에 간혹가다 '기존의 데이터 세트를 다시 사용해서 CFA를 하면 안 되느냐' 는 질문이 종종 나오는데, 사실 어림없는 소리다(…). 학계의 관점에서는 그건 그거고, 이건 이거다. EFA를 위해 수백 명의 설문을 실시했다면, 이제 CFA를 위해 다시 새로 수백 명에게 설문을 받아야 할 차례다.
앞에서도 언급했지만 CFA는 사실 수학적 밑바탕이 1960년대 무렵에 완료되었음에도 한동안 실제로 방법론의 지위에 이르지는 못했다. 그러다가 경로분석의 도움을 받아서 '여러 요인들이 일정한 인과적 구조를 갖고 있고, 그것들이 각각 일정한 요인적재량을 갖고 여러 지표변인들에게 영향을 끼치고 있다' 는 논리가 모형의 세계에 진입할 수 있게 되었다고 할 수 있다. 그렇기 때문에, CFA를 이야기하려면 CFA가 모형의 하나로서 분석될 수 있도록 경로분석과 합쳐진 결과물, 즉 '구조방정식 모형' 에 대해서 알아야 한다.
2.2.1. 구조방정식 모형(SEM)[편집]
드디어 본격적으로 구조방정식 모형(이하 SEM; structural equation modeling)에 대해 소개할 차례가 되었다. 방법론 연구자들은 CFA를 제대로 수행하기 위해서 경로모형에 특화된 분석법, 즉 경로분석(path analysis)의 도움을 받기로 했다. 그리하여 두 분석이 파이널 퓨전(…)을 일으켰고, 그 결과 탄생한 것이 SEM이다.[34] SEM 또한 이름이 여러 가지인데, 공분산 구조분석(covariance structure analysis)이라고도 하고, 연립방정식 모형(simultaneous equation modeling)이라고 부르기도 한다. 주요 연구자로는 피터 벤틀러(P.M.Bentler) 등이 있으며, 국내에는 이학식, 김계수, 이기종, 우종필, 배병렬 교수 등이 거론되는 편이다. SEM은 유독 마케팅을 비롯한 경영학, 행정학 등에서 매우 큰 인기를 끌고 있으며, 소비자 만족도나 브랜드 이미지 등을 연구할 때 적극 활용되고 있다. 요즘에는 SEM의 확장성 덕분에 다양한 목적으로 쓰인다는 듯.
SEM은 회귀분석처럼 개별 관측값과 회귀식의 예측값 사이의 차이를 최소화하지 않는다. SEM의 목적은, 개별 관측변인으로부터 얻어진 공분산행렬과, 모형에 의해 예측된 적합행렬(fitted matrix) 간의 차이인 잔차행렬(residual matrix)의 원소를 최소화하는 것이다. 쉽게 말해, SEM은 행렬 두 개를 놓고 양쪽의 차이를 최대한 줄일 방법을 찾는다. SEM은 다수의 변인들 사이의 다대다 상관관계 및 매개효과를 한번에 파악할 수 있다는 점에서 기존의 다중회귀분석(multiple regression)보다 더 유리하며, 때로 외생변인에도 오차가 발생할 수 있음을 무시하지 않았다는 점에서 그 설득력도 인정받고 있다. 게다가 잠재변인의 존재를 인정하므로, 기존에는 측정하지 않았던 개념적 변인일지라도 모형에 포함할 수 있다. (지금까지 잘 따라왔다면 알겠지만, 이 점에서는 SEM이 요인분석에게 빚을 지고 있다.) 마지막으로, SEM은 재귀모형과 비재귀모형 모두 어려움 없이 분석할 수 있을 만큼 강력하다.
단, 여기서도 결측값과 이상값이 포함되면 분석이 불가능하며, 종단적 연구에서 종종 나타나는 절단자료(censored data)는 그대로 분석할 수 없으므로 베이지안 정리 등의 도움을 받아서 보정 조치가 필요하다. 또한 간혹가다 표준화 회귀계수 값이 ±1.0 이상으로 나와서 해석이 불가능하게 만들기도 하는데, 이 경우에는 다중공선성(multicollinearity) 문제를 우선 의심할 수 있고, 또는 동일 데이터 세트로 간략한 경로분석을 실시해 보면 정상적인 결과를 산출하는 데 도움이 된다.
2.2.2. 식별문제[편집]
identification problem
혹시 고등학교 등의 수학 시간에 "미지수의 수가 N개일 때 이를 해결하려면 최소한 N-1개 이상의 힌트가 필요하다" 는 말을 들어보았는지? 사실 통계적 방법에서 가장 설명하기 어렵다는(…) 자유도의 개념과도 관련되어 있다. 모델링 연구자들이 모형에 대해 굉장히 중요하게 보는 것 두 가지 중 하나는 그 모형이 '식별' 될 수 있는가의 여부다. 이들에 따르면, 미지의 모수행렬 내에서 추정해야 할 모수의 수가 실제로 관측된 표본의 자료의 수보다 작거나 같아야 한다. 다시 말해, 모형을 검정한다는 것은 관측된 공분산 정보를 통해서 그 모형의 공분산 정보를 모두 추정할 수 있음을 전제한다. 이를 경우에 따라 t-규칙(t-rule)이라고 부르기도 한다.
가상의 등식 A×B=40 이 있다고 할 때, 우리는 가능한 두 미지수가 '정확히' 무엇인지는 알 수 없다. 어쩌면 두 미지수는 5와 8일 수도 있지만, 4와 10일 수도 있기 때문이다. 이때 이 두 미지수는 자유모수(free parameter)이며, 여기다 이것저것 넣어 보는 것이 바로 식별이다. 만일 모형의 자유도가 높아서 식별이 잘 되었다면, 그것은 곧 그 모형이 충분히 검약적이어서 여러 숫자들을 집어넣어 보기에 '빡빡하지' 않음을 의미한다. 반면 모형의 자유도가 낮다는 것은, 모형의 모수를 추정하기 위한 정보가 너무 부족하다는 것을 의미한다. 즉 모형이 너무 난잡하여 뭔가 기존의 정보로 설명이 안 되는 부분이 발생했고, 그것이 그 부분의 숫자들을 '자유롭게 풀어놓아 버린' 것이다. 이것이 바로 식별문제가 된다.
표현을 달리할 경우, 먼저 과소식별(under-identified)은 모델링에서 반드시 지양되어야 한다. 이때 자유도는 음수 값을 가지며, 이 모형은 설명이 불충분하므로 사용할 수 없다. 다음으로 적정식별(just-identified)이 있다. 이름만 들어보면 가장 좋을 것 같지만, 사실 이것도 그다지 좋지는 않다. 분석가가 가용한 모든 정보를 사용한 결과 단 하나의 고유해(unique solution)만이 도출되었기 때문이다. 이때 자유도는 0이 되며, 모형의 검정을 위해 필요한 잔여 자유도가 없기 때문에 일반화 가능성이 떨어진다. 마지막으로 과대식별(over-identified)은 이름만 들으면 뭔가 피해야 할 것 같지만 사실은 가장 좋은 상황이다(…). 모수 추정에 있어서 여러 개의 고유해가 도출될 수 있을 만큼 많은 정보를 갖고 있다는 뜻이기 때문이다. 이때 자유도는 양수 값을 가지며, 그 여러 고유해 중에서 관측된 공분산 정보에 가장 잘 적합되는 특정 고유해를 보고하는 게 분석가의 목표가 된다. 모델링에서 자유도는 모형을 갈고 닦고 다듬기 위해 필요한 '자원' 이라고도 할 수 있으므로, 많으면 많을수록 분석가로서는 이를 반기게 된다.
그렇다면 과소식별 상황에서 분석가는 이 모형을 버리지 않고 살리기 위해 어떤 방법을 취해야 할까? 가장 좋은 것은 관측변인의 수를 증가시켜서 정보를 늘리는 것이다. 하지만 이제 와서 관측변인을 늘리는 것은 항상 쉬운 일이 아니다. 가용한 정보를 당장 늘릴 수 없다면, 결국 할 수 있는 일은 필요한 정보를 줄이는 것뿐이다. 즉, 분석가는 식별문제가 해결될 때까지 모형 내의 자유모수들을 하나씩 하나씩 고정모수로 제약(constraint)하면서 재확인할 수 있다. 설명하자면 이렇다. 모형 속의 모든 오차항들의 화살표들, 그리고 잠재변인들과 관측변인들의 화살표들은 저마다 숫자들이 전부 붙을 수 있는데, 이 숫자들은 앞에서 보았던 요인적재량 개념에 대응한다. 그 중에서 분석가가 모든 오차항에 연결된 화살표마다, 그리고 잠재변인마다 하나씩 고른 관측변인에 연결된 화살표마다 숫자 1을 임의로 부여하는 것이다. 이렇게 하면 '채워넣어야 할 미지수' 의 숫자가 줄어들어서 식별이 가능해질 수도 있는 것이다.
이처럼 한 잠재변인이 갖는 여러 지표변인들 중 하나의 화살표에 달린 숫자를 1.0으로 고정하는 방식을 준거변인(reference variable)의 제약이라고 부르기도 한다. 이 방법은 특히 잠재변인의 측정에 있어 그 척도화(scaling)에서도 상당히 유리하다고 알려져 있다. 하지만 다른 방식을 취할 수도 있다. 예컨대, 단위분산(unit variance)을 제약하는 방식이 있다. 이 경우에는 모든 잠재변인의 분산을 1.0으로 고정하는데, 그 결과 단위분산은 모집단의 표준편차와 동일해진다. 하지만 어느 쪽을 제약하든, 결과적으로 모두 동일한 자유도와 동일한 카이자승 값을 갖게 된다고. 이 단락의 내용은 잘 모르겠다면 지도교수님이나 박사급 연구원들에게 더 많은 설명을 부탁해 보자(…).
2.2.3. 모형 적합도 검정[편집]
goodness-of-fit test
이제 드디어 CFA의 목적, 자신이 갖고 있는 가설적 모형이 자신이 실제로 (두 번째로) 수집한 데이터에 비추어 얼마나 적합한지를 확인할 때가 되었다. 모델링 연구자들이 모형에 대해 중요하게 보는 것 두 번째, 그 모형이 데이터에 얼마나 '적합' 한가를 따져보는 것이다. 적합도 검정의 목적은 자신이 갖고 있는 모형이 데이터에 얼마나 적합한지, 아무것도 설명하지 않는 경우에 비해 얼마나 많은 것을 더 설명하는지, 그리고 이 모든 것을 얼마나 검약적으로 설명하는지 확인하는 데 있다.
이때 어떤 모형이 '완벽하게' 적합한 상황이 되면 남은 자유도가 0이 되면서 포화모형(saturated model)이라는 이름이 붙는다. 하지만 어차피 모든 모형들이 이리저리 다듬고 고치고 하다 보면 어느 순간 포화모형이 되므로 그리 큰 의미는 없다(…). 또한, 어떤 모형의 적합도가 높다고 해서 항상 그것이 가장 가치 있는 모형이 되는 것도 아니다. 예컨대 앞에서 말했던 등치모형의 경우, 두 공분산행렬은 수치 상 서로 동일하지만 화살표의 경로 자체는 서로 다른 모습을 하게 된다. 이때 이 두 모형은 엄연히 다름에도 불구하고 수학적으로 동일한 적합도 수치를 보이게 되므로, 둘 중 어느 쪽을 골라야 하는지는
평범한 분석가는 물론 통계의 귀재는 아닐 것이므로(…), 그 가설적 모형은 사실상 포화모형이 아닐 수밖에 없다. 결국 어딘가 개선을 위해서 손댈 만한 곳이 있다는 얘기다. 이럴 때 분석가에게 필요한 것은 모형의 적합도를 일정한 수치를 통해 알려주는 적합지수(fit index)이다. 그리고 적합지수는 그야말로 어마어마하게 다양하게 개발되어서 쏟아져나왔고, 분석가는 그 중에서 주어진 여건에 따라, 기왕이면 가장 정보가 많은 것으로 골라서 보고하게 된다. 특히 모형이 얼마나 식별되는지, 그리고 얼마나 적합한지의 두 정보를 함께 반영하는 지수가 분석가들에게 선호되는 경향이 있지만, AMOS에서 모든 지수들이 지원되는 건 아니다. 예컨대 결측값 보정을 명령한 상태에서는 일부 적합도 검정이 불가능하다.
각각을 소개하면 다음과 같다. 적합성에 대한 판정은 관행적이고 암묵적으로 합의된 것이기 때문에, 각 수치가 다소 부적합하게 나온다 할지라도 그 쪽이 오히려 선행문헌이나 이론적 조망에 어울리는 모형이라면 과감하게 그 시점에서 모형 다듬기를 종료할 수 있다. 즉, 이하에서 얼마 이상, 얼마 이하일 때 적합하다고 판정한다는 말에 너무 심하게 구애 받을 필요는 없다. 그런 것들은 분석가들끼리 대충 말을 맞춰둔 것일 뿐, 수학적 정답이 아니다.
- 절대적합지수(absolute fit index)
가장 기초적인 적합지수이다. 모형의 전반적인 적합도를 평가하기 위해, ① 데이터 상의 공분산행렬과 ② 자신의 모형에서 추정된 공분산행렬을 서로 반복 비교하여, 그 차이가 점차 작아지도록 수렴(convergence)시킬 수 있도록 분석가를 돕는다. 즉 어떤 수치가 점점 작아질 때까지 똑같은 절차를 반복한다는 얘기니까, 위의 EFA에서 질리도록 보아 온, 익숙한 논리다.
- 카이자승 값(CMIN)
가장 보편적이며, 대부분 적합도 검정을 한다고 하면 카이자승 값과 p-값부터 떠올린다. 모집단 대표성 및 데이터의 정규성이 가정됨을 전제로 하며, 대표본이나 복잡한 모형에는 적절하지 않을 수 있다는 우려의 시선도 있긴 하다. 여기서는 기대된 경로모형과 실제 경로모형의 차이가 걱정해야 할 만큼 큰지 확인한다.
통계적 검정에 익숙하다면 이 지점에서 '그럼 p-값이 작으면 안 된다는 건가?' 싶을 텐데, 실제로 그렇다. 여기서 적합하다는 판정은 p>.05 일 때 내려진다. 이때만큼은 사회통계 시간에 배웠던 것과는 반대로 생각해야 한다. 즉, p-값이 작다는 것은 '차이가 있다' 를 의미하므로, 일반적으로 평균의 차이를 비교하는 흔한 경우에는 p<.05 정도로 작아져야만 의미 있는 해석이 나오고 연구자로서도 반길 만한 상황이 된다. 하지만 적합도 검정의 경우, p-값이 작다는 것은 '네가 만든 모형은 이 데이터에 너무 안 맞잖아멍청아' 를 의미하기 때문에(…) 모형을 여기저기 손보고 다듬어야 하는 상황이 된다. 결국, p>.05 만큼 높아졌을 때 모형과 데이터에서 나온 두 행렬의 차이가 같다고 판단하게 되므로, 평균 차이를 비교할 때에는 연구자를 좌절시켰던 높은 p-값이 거꾸로 적합도 검정 때에는 분석가를 들뜨게 만든다.
통계적 검정에 익숙하다면 이 지점에서 '그럼 p-값이 작으면 안 된다는 건가?' 싶을 텐데, 실제로 그렇다. 여기서 적합하다는 판정은 p>.05 일 때 내려진다. 이때만큼은 사회통계 시간에 배웠던 것과는 반대로 생각해야 한다. 즉, p-값이 작다는 것은 '차이가 있다' 를 의미하므로, 일반적으로 평균의 차이를 비교하는 흔한 경우에는 p<.05 정도로 작아져야만 의미 있는 해석이 나오고 연구자로서도 반길 만한 상황이 된다. 하지만 적합도 검정의 경우, p-값이 작다는 것은 '네가 만든 모형은 이 데이터에 너무 안 맞잖아
- 카이자승 값과 자유도의 비율(CMIN/df)
위에서 보았던 카이자승 값을 자유도로 나눈다. 이 값을 간혹 표준화된 카이자승 값이라고도 부른다. 수치가 1에 가까운 작은 수로 나올 때 모형이 적합하다고 판정한다.
- 적합선도(이하 GFI; goodness-of-fit index)
이쪽도 꽤 많이 쓰이는 적합지수인데, 회귀분석의 r2 논리와도 유사하다. 실제 데이터가 갖는 분산과 공분산의 양이, 가설적 모형을 통해서 얼마나 예측될 수 있는지를 평가한다. 그 수치는 0에서 1 사이로 나타나며, 당연히 1에 가까운 큰 수로 나올 때 모형이 적합하다고 판정한다. GFI는 표본크기에 대한 제약이나 다변량 정규성의 전제로부터 자유롭다.
- 조정적합선도(이하 AGFI; adjusted GFI)
위에서 보았던 GFI를 자유도를 통해 한번 더 조정했다. 이 역시 회귀분석의 조정된 r2(adjusted r2)와도 유사하다. 마찬가지로, AGFI도 0에서 1 사이의 수치로 나타나며, 1에 가까운 큰 수로 나올 때 모형이 적합하다고 판정한다.
- 잔차제곱평균근(RMR 또는 RMSR; root mean squared residual)
이것도 은근히 쓰이는 적합지수. 모형으로 추정된 행렬과 실제 데이터로 관찰된 행렬 사이의 잔차평균을 구하는데, 이 숫자가 적절한 범위에서 나타나야 한다. 경우에 따라서는 1보다 큰 숫자로 나올 수도 있으며, 대개 .05~.08 사이일 때 모형이 적합하다고 판정한다.
- 표준화된 잔차제곱평균근(이하 SRMR; standardized RMR)
위에서 보았던 RMR은 측정 단위에 영향을 받는다는 한계가 있다. 물론 통계학 개론 수업에서 언급되듯이, 단위의 영향으로부터 자유로우려면 표준화를 시켜 놓으면 된다. SRMR도 .05~.08 사이일 때 모형이 적합하다고 판정한다. 이 적합지수는 AMOS에서도 출력 가능하다.
- 근사오차제곱평균근(이하 RMSEA; root mean square error of approximation)
눈이 빙빙 도는 이름과는 달리(…) 꽤 많이 쓰이고, 방법론 연구자들에게도 비상한 관심을 받고 있는 '잘 나가는' 적합지수다. 이 적합지수는 저 위에 있는 카이자승 값의 한계를 극복하기 위해 마련되었다. 카이자승 값을 쓸 때에는 그 모형이 모집단을 정확하게 대표한다는 기본 전제로 인하여, 모형이 쓸 만함에도 불구하고 자칫 과도하게 기각될 수 있다는 우려가 제기되었다. 따라서 RMSEA는 이 문제를 해결하기 위해 근사적합도(close fit) 개념을 도입했다. RMSEA에 따르면 그 수치가 .10 이하로 작은 수일 때 모형이 적합하다고 판정한다.
- 증분적합지수(incremental fit index)
이 적합지수는 '아무것도 설명하지 않는' 텅 빈 모형에 비하여 얼마나 더 많은 것을 설명할 수 있는지를 평가한다. 분석가가 갖고 있는 모형에서 변인만 남기고 화살표만 싹 지워버리면 귀무모형(null model)이 되는데, 여기서 분석가가 이러이러하게 화살표를 그었던 것이 정말 의미가 있는 행동이었는지 따져보는 적합지수다. 쉽게 말하자면 모형 속에 있는 화살표들이 갖는 가치를 평가한다고도 표현할 수 있겠다.
- 표준적합지수(이하 NFI; normed fit index)
가장 단순하고 직관적인 증분적합지수. 귀무모형과 비교했을 때 새롭게 화살표를 그음으로써 데이터와의 불일치(discrepancy)가 얼마나 많이 향상되었는지를 0에서 1 사이의 값으로 표현한다. 예를 들어 0.9의 수치가 떴다면, 이는 분석가가 화살표를 그었기 때문에 불일치가 90% 정도 감소하는 향상을 이루어냈음을 의미한다. NFI는 1에 가까운 큰 수가 얻어질 때 모형이 적합하다고 판정한다.
- 비표준적합지수(이하 NNFI; non-normed fit index)
위에서 소개한 NFI는 다소 편의(bias)가 나타날 수 있다는 문제제기를 받았으며, 그 때문에 분모와 분자를 각각 자유도로 나누고, 분모에서 추가로 1을 차감하는 등의 변형을 거쳤다. 그 논리는 위에서 살펴보았던 Tucker-Lewis 지표와도 유사하다. NNFI 또한 1에 가까운 큰 수일 때 모형이 적합하다고 판정한다.
- 상대적합지수(RFI; relative fit index)
여기서는 귀무모형의 자유도와 가설적 모형의 자유도 사이의 일치 여부를 비교한다. 그 값은 0에서 1 사이로 나타나게 되며, 역시나 1에 가까운 큰 수일 때 모형이 적합하다고 판정한다.
- 비교적합지수(CFI; comparative fit index)
RFI를 바탕으로 하여 좀 더 많은 고려사항들을 반영한 적합지수. RFI와 똑같이 1에 가까운 큰 수일 때 모형이 적합하다고 판정한다.
- 검약적합지수(parsimonious fit index)
번역하기에 따라서는 '간명적합지수' 라고 부르기도 한다. 한 마디로 오컴의 면도날을 분석가가 갖고 있는 모형에 적용해 보는 것이다. 모형이 복잡할수록 각종 통계치들은 한없이 좋아지긴 하지만 그 반작용으로 모형이 심히 지저분(…)해지는데, 이 때문에 모형이 너무 복잡해지지 않도록 막아주는 정보를 제공한다.
- 검약적합선도(이하 PGFI; parsimonious GFI)
귀무모형과 가설적 모형의 자유도의 비율을 비교하여 0에서 1 사이의 값으로 나타낸다. 결과 수치가 클수록 비율이 크다는 것을 의미하며, 그만큼 단순한 모형이라고 판정하게 된다. PGFI는 1에 가까운 큰 수일 때 모형이 적합하다고 판정한다.
- 검약표준적합도(PNFI; parsimonious NFI)
그 논리는 PGFI와 동일하지만, GFI가 아니라 NFI에 결합시킨 지수이다. 1에 가까운 큰 수일 때 모형이 적합하다고 판정한다.
- Akaike 정보량 규준(이하 AIC; Akaike information criterion)
일본의 통계학자 아카이케 히로투구(赤池弘次; H.Akaike)의 이름에서 따왔다. 머신 러닝이나 정보과학, 정보통계학, 데이터과학 등에서 사용하던 개념을 빌려온 것인데, 모형이 갖고 있는 정보량 규준에 비교하여 그 복잡성이 클수록 값이 함께 커지게 되어 있다. AIC의 경우 값이 작을수록 모형이 적합하다고 판정하는데, 마땅한 판단기준이 딱히 없어서 잘 쓰이지는 않는다.
2.2.4. 모형의 수정 및 모형 간의 경쟁[편집]
model modification
위의 적합지수를 통해서 어쨌거나 자신이 갖고 있는 모형이 어딘가 살짝 손볼 만한 곳이 있음을 확인했다고 하자. 분석가는 이제 자신의 모형을 고치기 위해서 일종의 '정' 과 '끌' 이 필요하다. 그리고 그 역할을 해 주는 통계적인 도구가 바로 수정지수(이하 MI; modification index) 및 T-값이다. 일반적으로 모형을 기존보다 더 복잡하게 변화시켜야 할 경우에는 MI가 쓰이고, 더 검약적으로 만들어야 할 경우에는 T-값이 쓰인다. 이들을 통해 분석가는 자신의 모형의 적합도를 개선시켜서 포화모형에 가깝게 만들어 가게 된다.
그런데 어떻게 모형을 '고친다' 는 것일까? 앞에서 언급했듯이, 분석가는 당장 자신이 할 수 있는 방법으로서는 모형 내의 자유모수들을 고정모수로 하나씩 묶어 놓거나, 고정모수들을 하나씩 풀어보는 식으로 모형을 다듬는다. 여기서, 하나 이상의 모수에 대해서 기존에는 없었던 제약을 가하여 해당 모수를 추정하지 않도록 수정하는 방식을 모형 삭감(model trimming) 또는 후방탐색(backward search)이라고 한다. 반대로, 기존에는 0으로 고정되어 있었던 모수의 제약을 풀어줌으로써 자유롭게 추정할 수 있도록 수정하는 방식을 모형 증축(model building) 또는 전방탐색(forward search)이라고 한다. 제약을 가할수록 모형을 '깎는' 것이라면, 제약을 풀수록 모형을 '덧붙이는' 것이라는 얘기다.
고정모수를 자유모수로 만든다는 건 모형에서 설명이 필요한 부분을 추가시킨다는 의미로 생각하면 편하다. 위에서 보았던 요인의 회전을 떠올려 보자. 직각회전은 마치 요인 간 상관이 없는 것처럼 가정한다. 여기서 요인 간 상관은 0으로 고정되어 있으며, 따로 뭐 설명할 건덕지(?)가 없다. 하지만 사각회전으로 만든 모형은 직각회전으로 만든 모형보다 더 복잡하다. 추가로 요인 간 상관을 인정하기 때문에, 그 부분에 채워넣을 숫자 하나가 더 필요하기 때문이다. 즉, 사각회전에 기초한 모형은 요인 간 상관이 자유모수이며, 그 부분까지 뭔가 설명해 내야 하는 '더 복잡한' 모형이 된다.
여기서 MI는 카이자승 값의 변화량을 의미하는데, 고정모수가 자유모수로 바뀔 때 (모형이 복잡해질 때) 감소하게 된다. 또한 T-값은 자유모수를 고정모수로 바꾸는 과정에서 그 모수의 추정값을 추정값의 표준오차로 나눈 값'이다. 직관적으로 설명하자면, 기존의 모형에서 화살표가 있어야 함에도 불구하고 어째서인지 빠져 있는 관계가 있다면, 그 변인에서 MI의 수치가 높아지게 된다. 대개 MI>4.0 정도로 클 경우, 이론적 배경에 비추어 괜찮다고 판단될 때 새로 화살표를 덧그리는 것을 고려할 수 있다. 어디까지나 '고려' 하는 정도다. 숫자 맞추기 식으로 재밌다며 화살표를 마구 그어대다 보면 모형도 이상해지고 이론적 조망과도 거리가 멀어진다! 가끔씩은 오차항끼리 화살표를 그으라고 MI가 나타나는 경우도 있지만, 무시하자(…). 오차항 간의 상관은 0으로 가정한다는 얘기는 위의 '기본 전제' 에서부터 미리 못박아 놓은 것이다.
이처럼 MI 또한 별 생각 없는 분석가들에 의해서 오용되기 십상이다. 머리를 비우고 화살표를 긋다 보면 MI가 높은 것들만 찾으면서 반사적으로 쓱쓱 그어가게 되지만, 모형의 확립은 반드시 이론의 가이드를 받아야 하는 중차대한 일이다. MI가 가장 큰 쪽과 조금 덜 큰 쪽 중에서 이론의 예측은 후자 쪽에 가깝다면, 그때는 화살표를 후자 쪽으로 그어야 한다. 방법론 연구자들이 늘 강조하는 것이 "화살표는 절대 함부로 긋는 게 아니다" 이며, 이건 설령 SEM이 아니더라도 잠정적 모형(tentative model)을 만들 때조차 듣게 되는 잔소리다. 사회과학 분야에서는 통계를 가르치더라도 이런 실질적(substantive)인 측면을 늘 신경쓰라고 조언한다. 하지만 현실적으로 대개의
여기까지 모형을 수정하는 과정을 살펴보았는데, 사실 분석가 입장에서는 하나의 모형을 수정한다는 것이 표현만 그럴 뿐이지 실제로는 서로 조금씩 다른 두 모형을 서로 견주어 본다는 의미이기도 하다. 이를 다시 생각하면, 동일한 데이터를 놓고서 상이한 두 경쟁적 모형들(competing models) 중에서 어느 쪽의 모형이 더 적합한지를 살펴볼 수 있다는 말도 된다. 위에서 살펴본 '화살표를 더하고 빼기' 의 과정은, 두 모형이 '더 단순한 쪽이 더 복잡한 쪽의 부분집합이 되는' 논리적 관계에 놓이게 한다. 이런 경우를 내포모형(nested model)의 관계라고 한다. 하지만 때때로는 아예 잠재변인 수준에서 서로 다른 모양을 하고 있는 모형들을 비교할 수도 있다. 이때에는 두 모형이 위계적 내지 내포적 관계를 형성하지 않으므로, 이는 따로 비내포모형(non-nested model)의 관계라고 한다. 내포모형 관계에서는 평범하게(?) 카이자승 값과 같은 절대적합지수를 사용하면 되지만, 비내포모형 관계에서는 검약적합지수 정도를 활용할 수 있다.
2.2.5. 다중집단 확인적 요인분석[편집]
Multigroup CFA (multiple-group CFA)
앞의 김 씨의 사례를 다시 떠올려 보자. 김 씨는 '나무위키답다' 는 말을 했던 화자가 당초 남성이었음이 기억났다. 하지만 뒤늦게 자신의 데이터를 확인해 보니, 응답자의 무려 90%가 전부 여성으로 이루어져 있었다. 그렇다면 여성들을 대상으로 '나무위키다움' 에 대해 설문을 실시한 결과를 가지고 과연 이 남성 화자의 의도를 제대로 반영할 수 있을까? 요컨대, 여성들의 경우 '비신뢰성' 이 제1요인이 되었긴 하지만, 만약에 남성들을 응답자의 90%로 채워서 다시 설문을 실시한다면, 그때는 '비신뢰성' 이 제2요인 정도로 내려가게 되지는 않을까?
다중집단 CFA는 여러 집단들 사이에서 동일한 CFA를 수행하여, 두 집단에서 얻어진 요인모형이 서로 동일한지, 아니면 유의하게 달라지는지를 확인하는 요인분석이다. 다시 말해, 집단 간의 차이가 갖는 조절효과(moderating effect)가 의심될 경우에 활용할 수 있다. 그 논리는 언뜻 골치아플 것 같지만, 의외로 기존의 모형 간 적합도 검정의 응용이라고 할 수 있다. 즉, 적합도 검정은 모형을 살짝 다듬었을 때 다듬기 이전과 다듬은 이후를 모형 간에 비교한다는 것인데, 그렇게 본다면 두 데이터 세트 간에 비교하는 경우에도 이를 응용할 수 있다. 어차피 똑같이, 영가설은 "두 모형이 갖는 카이자승 값은 유의한 차이가 없다" 로, 대립가설은 "두 모형이 갖는 카이자승 값은 유의한 차이가 있다" 로 설정하고, p<.05 이면 두 모형이 다르다고 판단하고, p>.05 이면 두 모형이 같다고 판단하면 되기 때문이다. (위의 모형 간 경쟁은 동일한 데이터에 상이한 모형이라면, 다중집단 CFA는 상이한 데이터에 동일한 모형이라고 할 수 있다.)
하지만 여기서는 상이한 데이터에서 유래한 모형이 서로 "동일하다" 고 말하기에는 조금 더 조심스러워야 한다. 두 모형이 동일하다고 말하기까지, 방법론 연구자들은 대략 다섯 단계의 기준에 비추어 볼 것을 권장한다. AMOS에서도 지원되기는 하는데, 대신 여기서는 3단계가 빠져 있다.
- 1단계 - 요인구조의 동일성
상이한 데이터로부터 요인모형이 도출되었지만, 결과적으로 그 구조적 형태에서 동일해야 한다. 여기서 긍정적이라면, 다음 단계로 넘어간다.
- 2단계 - 요인계수의 동일성
상이한 데이터로부터 얻어진 요인모형이 구조적 형태뿐만 아니라 요인의 각 계수들까지 서로 동일해야 한다. 이를 위해서 서로 동일하다는 제약을 걸었을 때와 그런 제약이 없을 때 카이자승 값이 얼마나 달라지는가를 검정한다. 동일성 판단에서 가장 결정적으로 희비가 갈리는 부분이기도 하다. (위의 김 씨가 염려했던 것도 바로 이 단계와 관련되어 있다.) 여기서 긍정적이라면, 다음 단계로 넘어간다.
- 3단계 - 공분산 동일성
이제 두 요인모형은 요인 간의 상관까지도 서로 동일해야 한다. 이 역시 요인 간 상관의 크기가 서로 동일하다는 제약이 있을 때와 그런 제약이 없을 때의 카이자승 값의 차이를 검정한다. 여기서 긍정적이라면, 다음 단계로 넘어간다. 상기했듯이 AMOS에서 이 단계는 따로 출력되지 않으므로, 분석가가 별도로 계산을 명령해야 한다.
- 4단계 - 요인계수/공분산 동시 동일성
이제 두 요인모형은 심지어 2단계와 3단계의 제약을 동시에 걸었을 때와 동시에 풀었을 때 카이자승 값의 차이를 보게 된다. 사실, 앞에서 줄곧 동일하다는 결과를 얻었다면 여기서도 대개 동일할 가능성이 높다. 여기서 긍정적이라면, 마지막 단계로 넘어간다.
- 5단계 - 요인계수/공분산/오차분산 동시 동일성
대망의 마지막 단계다. 여기서는 심지어 앞의 모든 제약 + 오차분산의 제약을 동시에 걸었을 때와 동시에 풀었을 때 카이자승 값의 차이를 보게 된다. 이전에 줄곧 동일하다는 결론을 얻었으며 모형도 겸사겸사 검약적이고 데이터도 정밀하다면, 여기서도 대개 동일할 가능성이 높다. 여기서 긍정적이라면, 마침내 두 요인모형이 동일하다는 결론을 도출한다.
보통은 요인구조의 동일성에서 요인계수의 동일성으로 제약을 하나 가할 때 자유도의 변화에 비해서 카이자승 값이 얼마나 변화하는지를 보게 되는데, 이를 위해서는 카이자승 테이블이 별도로 필요하다. 예컨대, 만일 (p=.05 기준일 때) 카이자승 값이 30.00 증가하면서 자유도가 6만큼 증가했다면, 테이블에서 이를 찾아보면 카이자승 임계치(critical value)가 12.59 로 나타남을 볼 수 있다. 따라서 30.00 변화량은 12.59 보다 명백히 더 크기 때문에, 두 집단 사이에 유의한 차이가 있다고 판단할 수 있다. 측정 동일성이 사전에 확보되지 않았을 때에는 다중집단 CFA를 그대로 강행해서는 안 되며, 사실대로 밝히고 분석을 중단하는 편이 훨씬 신뢰를 줄 수 있다.
다중집단 CFA에 있어서 결과의 보고(reporting)는 보통 비표준화 계수를 활용하게 된다. 표준화 계수는 분산이 모두 최대 1.0의 동일한 크기로 나타난다는 점에서 회귀분석의 베타 값과 유사한데, 이런 통계량은 외생변인이 내생변인에 끼치는 상대적인 영향력을 '표본 내에서' 파악하기에는 적절하지만, '표본 간에' 비교하는 것은 불가능하다. 따라서 다중집단 CFA에서 표준화 계수를 활용하는 것은 추천되지 않는다. 다행히 비표준화 계수는 표본에 따라서 계수의 값이 달라지는 문제가 나타나지 않으므로, '표본 간에' 계수의 크기를 비교하기를 원한다면 비표준화 계수를 활용하는 것이 좋다.
2.2.6. AMOS에서의 CFA[편집]
사실 CFA의 용도로 처음 쓰였던 통계 패키지는 AMOS가 아니라 LISREL이었다. 당장 CFA의 가능성을 구체화한 저 스웨덴의 심리통계학자 칼 예레스코그(K.G.Jöreskog) 본인이 직접 LISREL을 만들고 매뉴얼도 찍어내고 엄청나게 세일즈를 했기 때문. 그러나 LISREL의 가장 큰 문제점은 바로 진입장벽에 있었다. 일단 모형 속의 모든 문자는 그리스 문자로 통일되었으며, 명령어를 코딩할 때에는 반드시 행렬의 형태로 코딩해야 했다. 이러다 보니
현대의 각 학문분야마다 가장 대세가 된 CFA용 소프트웨어는 이제 거의 AMOS로 굳어졌다. 그 이름은 "Analysis of Moment Structure" 의 약자이며, 제임스 아버클(J.L.Arbuckle)과 워너 워스케(W.Wothke)에 의해 개발되었으며[35] 이후로는 IBM과 제휴하여 서비스 중이다. 마치 SPSS가 그렇듯이, 이것도 유저 인터페이스에 있어서라면 시각적으로 직관적이고 활용하기가 매우 쉽다. 즉, 진입장벽이 매우 낮은 프로그램이며, 평범한 대학원생들도 두어 시간 특강을 듣고 나면 간단한 모형을 만들 수 있을 정도이다. 게다가 SPSS와 동시에 버전업을 할 수 있으며, 심지어 두 프로그램 간에 연동도 된다!
사용하기 쉽다는 점 때문에
물론 AMOS에는 단점도 분명히 있다. 일단 앞에서 언급했듯이 조형지표모형을 제대로 다루지 못한다. 그래서 그런 모형에 한해서는 SmartPLS나 RAMONA 같은 다른 소프트웨어들에게 밀린다. 또 원천자료(raw data)를 직접 입력해야만 분석이 가능하다는 점은 양날의 검이 될 수 있는데, LISREL의 경우 원천자료가 없어도 행렬자료만 있으면 분석이 가능하다는 점과 잘 대비된다. 더불어 SPSS처럼 은근히 초보 분석가들을 골탕먹이는 지점들이 좀 있다. 예컨대 외생변인에 구조오차를 연결하는 실수를 해도 AMOS는 시스템 자체적으로 이를 막거나 경고를 보내지 않으며, 내생변인에 오차항을 붙여주지 않고 분석을 강행해도 이를 그냥 허용해 준다. 마지막으로, 변인 이름을 지정할 때 심지어 한글까지도 인식할 수 있는 주제에, 정작 띄어쓰기는 인식하지 못한다(…).
위에서도 언급했지만 아직까지도 연구 현장에서 높으신 분들은 LISREL이 무조건 진리(…)라는 숭고한 가르침을 받으며 연구해 왔기에, 간혹가다 후학이 AMOS를 쓴다고 했을 때 코웃음을 치거나 무조건 LISREL로 갈아타라고 요구하는 경향이 다소 잔존해 있다고 한다. 사실 이분들이 통계를 배울 때만 하더라도 LISREL이 실제로 최고존엄이기 때문인 것도 하나의 이유지만, AMOS는 처음부터 강력한 다크호스로 등장했다기보다는 꾸준히 업데이트를 거치면서 개선되어 온 소프트웨어였다는 점도 다른 이유이다. 이 때문에 실제로 초창기 버전의 AMOS는 한계가 굉장히 많고 LISREL보다 여러 모로 뒤처졌지만, 현대의 최신 버전의 AMOS는 LISREL과 비교해서 전혀 손색이 없는 강력함을 자랑한다. 그렇기 때문에 LISREL과 AMOS 간의 최강논쟁은 더는 의미가 없다고 봐도 될 것이다.
실질적인 이용 팁을 몇 가지 언급할 수 있을 것이다. 먼저 AMOS 상에서 모형분석 결과를 보고하는 경우다. 우선 위반추정량(offending estimate)이 있는지 걸러내려면, 헤이우드 사례가 있는지, 1.0을 초과하는 표준화 계수가 있는지, 계수의 표준오차가 큰 것이 있는지, 오차분산이 0에 가까운 것이 있는지 확인해야 한다. AMOS에서 말하는 임계비(CR; critical ratio)는 모수의 값을 표준오차 추정치로 나눈 것인데, 검정을 위한 임계치로 쓰일 수 있다. 또 요인 점수의 가중치를 찾기 위해서는 Properties ▶ Output ▶ Factor score weights 로 들어가면 된다.
다음으로 AMOS에서의 모형 추정을 조금 언급하자면, AMOS는 미지의 모수행렬에 들어갈 원소들을 표본행렬 속의 실제 관측된 데이터에 최대한 일치시키기 위하여 반복추정법(iterated estimation)을 실시한다. AMOS는 그 기준으로서 우리가 이미 접해봤던 ML을 비롯하여 일반최소제곱법(GLS; generalized least squares), 비가중최소제곱법(ULS; unweighted least squares), 척도자유최소제곱법(scale-free least squares), 점근분포자유법(ADF; asymptotically distribution-free) 등등의 현란한(…) 테크닉들을 갖고 있다. 이를 둘로 구분하자면, ML과 GLS, ADF는 각각의 회귀식을 따로 추정하는 게 아니라 모형 속의 모든 계수들을 한꺼번에 추정하는 완전정보기법(full information technique)에 속하며, 이 때문에 한 모수에 변화가 생기면 다른 모수들도 영향을 받기 쉽고, 설정오차에 더 민감하다. 만약 이런 문제를 피하고 싶다면 부분정보기법(partial information technique)에 해당하는 ULS를 골라서 명령하면 된다.
3. 방법론 간의 비교[편집]
3.1. EFA vs. CFA[편집]
이제 이쯤되면 EFA가 뭐였는지, EFA와 CFA가 서로 같은 부분이 있긴 한 건지 싶은 생각이 들지도 모른다. 여기서 추가로 CFA와 SEM이 서로 어떤 차이가 있느냐고 묻는다면 상황은 더욱 난감해진다. 따라서 여기서 한번 더 양쪽 간의 관계를 정리하도록 하겠다.
이제 이번에는 CFA와 SEM의 차이점을 몇 가지 정리하면 다음과 같다. 현실적으로 CFA를 시행하려면 SEM을 동원하게 되기 때문에, 왼쪽에서 오른쪽으로 분석의 인식이 전환된다고 생각하면 될 듯하다.
3.2. 요인분석 vs. 회귀분석[편집]
저 위에서는 잠깐, "독립변인과 종속변인 같은 개념이 불필요하다" 고 언급하긴 했는데, 사실 엄밀히 말하자면 이것도 약간 애매한 문제이긴 하다. 요인분석의 가장 기본적인 아이디어가
1) 우리가 모르는, 혹은 어렴풋이 감은 잡고 있지만 정확한 관측이 불가능한 변수들이 있다고 가정하고, 이를 요인이라고 한다.
2) 이 때, 우리에게 관측되는 변수들이 이 요인들로 인해 만들어진 결과물이라고 가정한다면, 우리의 눈에 관측되는 변수들을 종속변수로 하고, 요인들을 독립변수로 하는 가상의 다변량 회귀모형을 설정할 수 있다.
3) 이 가상의 회귀모형을 적절히 사용하면 우리들의 눈에 보이지 않는, 세상의 이면에 존재하는 핵심변수들을 찾아낼 수 있을 것이다.
로부터 시작하기 때문이다. 따라서 엄밀히 말하면 "독립변인과 종속변인 같은 개념이 불필요하다"는 서술은 틀린 표현이다. 그러나 통계학과처럼 확률론, 수리통계학, 선형대수학, 회귀분석 등을 다 수강한 뒤에 요인분석을 배우는 경우에야 요인분석에서 사용되는 가상의 회귀식을 다룰 수 있다. 그나마도 초기에 전체적인 감을 잡을 때에나 유용하지, 요인 분석 후반부에서 배우는 복잡한 내용들을 정확히 이해하지 못하는 경우가 태반이다. 요인 분석 후반부부터는 식을 보고 '대충 이런 아이디어구나'하고 넘어가는 경우가 태반이다.
기본적인 회귀식의 논리에 따르면 단일요인 모형에서 각 지표변인은 Z=aF+e 형태의 회귀식을 출력하며, 다요인 모형에서는 Z=aF1+aF2+...+aFN+e 형태의 회귀식을 출력한다. 즉, 한 지표변인은 공통요인의 요인적재량에 더하여 고유요인의 적재량으로[36] 설명된다.
그러나 차이점도 있는데, 여기서 회귀분석의 경우 보통은 a 값에 대한 측정이 가능하지만, 요인분석은 a 값에 대한 직접적 측정이 불가능하다는 것이 다르다. 어찌보면 측정이 불가능한, 숨겨진 핵심변수들이 있다고 가정하고 이를 요인이라고 정의한 것이기 때문에 요인에 해당하는 F의 값이 여러 개가 나오고, 거기에 따라서 a 역시 여러 값이 나오는 것이 특별한 일은 아니다. 이것이 요인의 비유일성(nonuniqueness)이라고 하는 아주 중요한 개념이다. 여러 형태의 요인과 적재량이 존재할 수 있다는 것이 증명되었기 때문에, 찾아낸 요인을 연구자가 해석하기 쉬운 형태로 적절히 변환할 수 있다는 이론적 근거가 되기 때문이다. 다시 말해 직교니 사각이니 하는 회전을 시도해도 된다는 이론적 근거가 된다. 이 때부터는 관심사가 초기에 나온 값을 우리가 원하는 형태로 바꿔주는 행렬을 찾는 것으로 바뀐다.
보이지 않는 요인을 독립변수로 하는 회귀식을 가정한다는 점이 '해석이 용이한 형태로의 변환 가능성'이라는 편리함도 주지만, 이 점 때문에 EFA를 영 마음에 들어하지 않는 연구자들도 있다. 실제로 존재하는지 존재하지 않는지 검증이 되지 않은, 때로는 검증을 할 수도 없는 변수가 있다고 가정해 놓고 분석 결과를 보고한다고 생각해 보자. 깐깐한 이론통계학자나 연구자들이 보기에는 마음에 들지 않을 수 있다. 다른 분야에 비유하자면, 수학 전공자들에게는 해(solution)가 있는지 없는지 존재성(existence)의 문제도 증명되지 않은 어려운 방정식이 있는데, 공대 연구실에서 '내가 몇가지 가정을 세우고 논리를 전개해보니까, 이 방정식은 여러 가지의 해가 존재할 수 있다, 따라서 나는 내가 사용하기 편리한 해를 수치적으로 구해서 사용했다'라고 말하는 격이다. 이 정도로 깐깐한 사람들은 요인 분석보다는 PCA를 선호한다. PCA는 이미 관측된 변수들의 선형결합으로 새로운 변수를 만들고 이 새로운 변수에 '주성분'이라는 이름을 붙인 후 해석을 가미하기 때문이다. 물론 PCA와 요인분석은 아래에 소개하듯 시작점이 다르기 때문에 다른 점이 많다.
각 지표변인을 회귀식으로 설명할 수 있다는 점은, 어쩌면 EFA에서 (그리고 CFA의 기초가 되는 경로분석에서) 계속 가정되는 인과성(causality)에 대한 기본 전제와도 관련이 있을 것이다. 회귀분석은 두 변인 간의 상관관계를 수학적으로 전부 뜯어서 해체하는데, 그 결과 직접효과(direct effect), 간접효과(indirect effect), 의사효과(spurious effect), 환류(feedback) 등을 전부 분해하는 것이 가능해진다. 이렇게 분해된 계숫값들은 학계에서 관행적으로 인과관계를 판단해도 될 정도로 엄밀하고 정교하다고 인정 받아 왔다. 그렇다면 경로분석과 SEM, 그리고 요인분석이 인과성을 전제하는 것 역시 최소한의 근거로 뒷받침되는 셈이다. 물론 이에 대한 비판이 없는 건 아니지만, 회귀분석이 워낙에 논리적으로 막강한 분석이다 보니, 웬만큼 모형이 설득력 있다 싶으면 인과성도 함께 인정해 주는 분위기가 있다.
3.3. 요인분석 vs. 경로분석[편집]
먼저 경로분석(path analysis)에 대한 설명이 필요할 것이다. 경로분석은 유전학자 시월 라이트(S.G.Wright)가 1918년에 기니피그 연구에서 제시했던 논리에 바탕을 두고 있다.[37] 그러나 그의 경로모형에서는 구체적 수치 없이 그저 (+), (-) 같은 기호만을 활용할 수밖에 없었다. 그러다가 1960년대 들어서, 위에서 소개했던 칼 예레스코그 같은 통계학자들이 여기에다 잠재변인 개념을 추가하면서 비로소 현대적인 형태를 갖추게 되었다. 그 요점은 경로분석에 잠재변인을 통합하는 것이었다.
당초의 경로분석은 쓸모가 아주 없지는 않았다. 지표변인들을 엄밀하게 정의함으로써 정제되고 순수한 변인을 뽑아내야 한다는 압력이 약했던 농학 분야에서는 상당한 인기를 끌었다. 하지만 사회과학 분야에서는 학문적인 처지가 서로 달랐고, 여기서는 자료의 신뢰도(reliability) 문제로 골치를 썩고 있었기 때문에 공통요인과 고유요인을 구분해야 한다는 아이디어가 일찍 떠오르게 되었다. 이 와중에 경로분석을 발견한 연구자들은 그것이 요인분석 결과로 도출된 요인들 사이의 관계를 확인하기 좋다는 것을 깨달았다. 기존의 요인분석은 요인 간 상관만을 확인할 수 있을 뿐, 요인 간의 인과관계나 다른 예측(prediction)을 할 수는 없다는 한계가 있기 때문이었다.
경로분석은 특정 개념이 단일문항(single-item)으로 고스란히 측정되었을 때에는 문제가 없지만, 측정오차를 반영하지 않기 때문에 다수의 문항을 동원하여 그 평균이나 총점을 도출하는 연구에서는 한계를 지닐 수밖에 없었다. 따라서, 잔차에 측정오차가 포함된다고 쿨하게(?) 인정하는 CFA와 결합한다면 양측의 방법론적인 한계점들이 상쇄될 수 있을 것이었다. 위에서도 설명했듯이, 그래서 양쪽이 파이널 퓨전을 일으켜서 탄생한 것이 다름아닌 SEM인 것. 만일 경로분석에서 굳이 측정오차를 알고 싶다면, 관측변인의 분산의 크기와 신뢰도 계수를 활용해서 직접 계산해야 한다.
경로분석은 언뜻 단순한 분석처럼 보일지도 모르지만, 어차피 모든 방법론은 깊이 파고들면 어렵다. 실제로 경로분석은 그 기본 전제로 보자면 회귀분석보다 더 엄격하다. 그렇다 보니 여러 상황에서 범용적으로 쓰기가 좀 어렵다. 일단 독립변인과 종속변인 사이의 관계는 선형적(linear)이고 가법적(additive)인 관계이며, 모형 속 방향은 일방향적이며 역방향이 성립하지 않고, 측정오차를 0이라고 전제하며, 모든 구조오차는 등분산성(homoskedasticity)이 존재하며 그 기대값이 0이면서 정규성을 따르고, 구조오차 간의 상관도 0으로 전제한다. 게다가 모든 변인들은 등간 혹은 비율 수준의 연속형 변인이고, 변인 간의 인과적 순서(causal order)가 존재하며, 독립변인 간 다중공선성 역시 0으로 전제한다. 보다시피 워낙에 전제들이 많다 보니 어딘가 삐끗해서 전제를 어기는 순간 역풍 맞기 쉬울 것 같은 분석방법이다(…).
하지만 경로분석은 분명히 오늘날의 CFA나 SEM과 같은 후배 방법론들에 중요한 영향을 끼쳤다. 일단 오늘날 확고하게 자리잡은 매개효과(mediation effect) 개념을 최초로 검정하기 위한, 저 유명한 Sobel의 방법이 바로 경로분석에서 나왔고,[38] 최적의 경로모형을 탐색하는 절차인 경로 특정(path specification) 역시 경로분석 연구자들에게 빚을 지고 있다. 그리고 서로 다른 두 경로가 있을 때 어느 경로가 더 높은 가중치를 갖는지 같은 연구 질문도 경로분석으로 해결할 수 있다. 경로모형의 탐색이나 경로 간 효과분석은 모두 현대의 AMOS에서도 전부 지원되는 기능들이다.
3.4. 요인분석 vs. 주성분분석[편집]
아마도 가장 많은 혼동이 발생하는 문제는 PCA와의 방법론적 관계일 것이다. 요인분석은 PCA와 어떻게 다른가? 결론적으로 말하자면, 활용 목적이 서로 굉장히 유사하긴 하지만, 그 기초 논리가 명백히 다른 것도 사실이다. 주성분분석에 보통 주의를 기울이는 분야들에서는 걱정할 필요가 없지만, 요인분석을 중시하는 분야들에서는 주의가 필요하다. 마치 한국인들이 이것저것 '일제의 잔재' 를 의심하게 되는 것처럼, 초기 요인분석가들이 아무 생각없이 PCA를 뒤섞어 쓰던 시절이 있었기 때문에, 현대의 요인분석가들도 'PCA의 잔재' 같은 것이 있는지 조심해야 하는 형편이다. 그러나 두 기법은 명백히 다른 논리에서 시작하였다.
먼저 PCA를 설명하자면, 그 연구의 역사는 요인분석보다 더 오래되었다. 이쪽은 통계학자 칼 피어슨(K.Pearson)이 최초로 개발한 것에서 출발한다. 그 논리는, 주어진 데이터를 (보통 2차원의) 좌표계로 직교 변환하여, 데이터의 가장 큰 분산이 좌표계 첫째 차원으로 설명되게 하고, 그 다음으로 큰 분산은 첫째 차원과 직교하는 둘째 차원으로 설명되게 하고, 이후의 차원들도 똑같은 방식을 따라가게 하는 데 있다. 여기서 각각의 차원을 주성분(principal component)이라고 하는데, 주성분의 수는 데이터가 갖고 있는 차원성(dimensionality)보다 작거나 같다. PCA는 데이터의 차원성을 축소하기 때문에, 데이터 자체의 손실 및 변형이 발생하게 된다. 기존 변수들의 설명력을 100% 가져오려면 모든 주성분을 다 사용해야 한다. 이렇게 되면 사용하는 주성분의 수가 기존 변수들의 수와 같아지기 때문에 변수 축약이라는 PCA의 목적에 맞지 않게 된다. PCA에서 실질적인 의미를 부여받을 때는, 보통 제1주성분 위주로 해석하면서 제2주성분을 보조로 활용하고, 제3주성분 이후부터는 그다지 관심을 받지 않는 편이다. 물론 제 1,2 주성분을 동원했는데 전체 변수 설명력의 절반도 설명하지 못한다면 추가적인 주성분을 사용할 수 있다. 어느 주성분까지 선택할지에 대해서는 다양한 기준이 있기 때문에 자신의 다양한 기준들을 종합적으로 사용해보고, 자신의 연구목적에 맞게 선택하면 된다.
주성분에 대해 조금 더 설명하자면, 제1주성분은 상관행렬 내에서 최대의 고유값 및 그에 대응되는 벡터 값으로 구해진다. 마찬가지로, 제N주성분 역시 자연스럽게 상관행렬 내 N번째 고유값과 벡터 값으로 구해진다. 각각의 주성분에는 람다 값이 붙게 되는데, 모든 k개의 주성분들의 람다 값을 합산하면 그 데이터의 총분산을 완벽하게 설명한다. 즉, PCA를 통해 우리가 달성하는 것은 데이터의 총분산 중에서 설명된 분산의 비율을 최대한 높이는 것이다. 다시 말해, 제1~제2주성분만 가지고 총분산의 반수 이상 정도는 설명해낼 수 있어야 성공적인 PCA가 된다. 기존 변수가 수십이라면 더 많이 써도 된다. 다시 말하지만 중요한 것은 연구목적에 맞는 기준을 뽑아내는 것이다. 예를 들어 주성분을 활용해 다른 회귀모형을 구축하고, 이를 통해 종속변수를 예측하는 것이 목적이라면 더 많은 주성분을 사용할 수도 있다. 예측이 목적이라면 최대한 많은 설명력을 끌어와야 하기 때문이다.
이렇게만 보면 요인분석과의 공통점이나 차이점이 명확하지 않을 수도 있다. 물론, 두 연구방법은 서로 상당히 유사한 분석목적을 따라서 수행된다. 이는 곧, 변인 간의 선형적 결합을 가정하고, 문항 간의 상관을 행렬로 만들어서 복잡한 자료를 간단하게 정리하자는 것이다. 하지만 이런 공통점 때문에 엄연히 존재하는, 너무 많은 차이점들이 종종 간과되기도 한다. 이를 다시 표로 정리하면 다음과 같다.
이처럼 서로 다른 분석방법임에도 불구하고, 과거 사회과학계에서 관행적으로 요인분석 과정에서 PCA의 논리들을 빌려와서 썼다는 점은 부정하기 어렵다.[39] PCA는 측정된 변인들 간의 총분산을 최대한 설명하기 위해서 차원을 축소하는 것이지만, 이런 용도의 방법론을 지표변인 간의 상관을 바탕으로 요인을 추출하는 데 오용하고 있었던 것이다. 특히 연구중심대학 풍토가 강하지 않은 곳에서 요인분석으로 논문을 써 봤다는 일부 중년 어른 분들의 경우, 막상 대화를 나누어 보면 거의 '혹시나가 역시나' 급으로 다음의 체크리스트에 걸리는 걸 볼 수 있다.
- 요인분석을 하기 위해 축소상관행렬을 쓰지 않고, PCA에서처럼 상관행렬을 고스란히 썼다.
- 요인분석을 하기 위해 PCA에서나 하듯이 '주성분의 기여량' 을 구했다.
- 요인모형을 세우기 위한 근거로서 PCA의 논리인 '총분산 중의 설명된 분산' 개념을 동원했다.
- 요인추출을 하기 위해 PAF 또는 ML 등을 쓰지 않고, SPSS의 디폴트 값대로 그냥 PCA로 추출하라고 명령했다.
- PCA의 논리를 하나 이상 동원한 상태임에도 불구하고 최종 결론에서는 지표변인 간의 상관을 논의했다.
물론, 이따금씩 PCA와 요인분석의 분석 결과가 서로 엇비슷해지게 되는 경우가 이론상 있을 수 있다. 가장 우선적으로 떠올릴 만한 상황으로는, 결국 고유요인이 데이터에 끼치는 비중 자체가 무시할 수 있을 만큼 작은 상황을 가정할 수 있을 것이다. 고유요인의 비중이 작을수록 상관행렬의 저 '우하향 1 대각선' 이 갖는 의미가 줄어들기 때문이다. 주성분분석의 관점에서는 '고유요인이 주성분에 흡수된다'라고 볼 수 있다. 하지만 이런 상황은 명백히 비현실적이며, 존재한다 해도 굉장히 드물다. 앞에서도 소개했던 《Factor Analysis》 책에서는 공통성이 .70 이상이고 지표변인 수가 35개 이상일 때에는 두 분석이 수렴한다고 말했지만, 연구자의 데이터가 늘 그 정도의 공통성을 보일 거라는 보장도 없다.
현대에는 이런 경계의식이 상당히 잘 확립되어서, 이제는 예전처럼 타성적이고 관행적으로 방법론을 섞어 쓰는 일은 굉장히 줄어들었다. 웬만큼 학문적 규율이 잡혀 있는 연구중심대학의 일반대학원에서라면, 오히려 요인분석 특강이 끝나고 남는 생각이 '요인분석 그거 PCA랑 섞으면 안 된다며?' 밖에는 없을 수도 있다(…). 어쨌거나 중요한 것은, 어떤 양적 방법론을 활용하든 간에, 그 방법론을 채택한 분석가에게는 그 방법론의 논리가 곧 자신의 논리와도 같다는 것이다. 어떤 사람이 뭐라고 주장을 내세우는데 그 설득력을 뒷받침하는 근거가 그 사람 본인도 이해하지 못하는 논리라면(…), 그것은 그저 아무말 대잔치일 뿐이다. 마찬가지로, 학계에서 타인을 설득하기 위해 채택하는 방법론은 그것이 통계적 방법일지라도 결국 기초 논리가 다 있기 때문에, 설령 세세한 수학적 증명까지 할 자신은 없더라도 그 논리에 대해서는 차별성을 확신할 수 있어야 한다.
통계학과 학부과정의 다변량분석에서 사용하는 교과서는 일반적으로 주성분분석-요인분석의 순서로 내용이 배치되어있다. 이 때문에 요인분석 후반부에 주성분분석과 요인분석을 통계학적 관점에서 비교하는 내용이 있는 경우가 많으니 관심이 있으면 참고하면 좋다.
 이 문서의 내용 중 전체 또는 일부는 2023-12-10 21:20:46에 나무위키 요인 분석 문서에서 가져왔습니다.
이 문서의 내용 중 전체 또는 일부는 2023-12-10 21:20:46에 나무위키 요인 분석 문서에서 가져왔습니다.[1] 대표적으로 GDP를 사용한 대형 시계열 분석이 있다. GDP는 분기별로 산출되는 데이터이기 때문에 일, 주, 월 단위로 생성되는 경제시계열 데이터에 비해 관측치가 적다. 거기에 경제 시계열 데이터는 대부분 비슷한 움직임을 보이는 경우가 많기 때문에, 거시경제 데이터를 시계열 분석하다보면 관측자료의 설명력에 비해 추정해야하는 모수가 너무 많아지는 문제가 발생한다. 이런 경우 PCA의 결과물을 사용하는 것이 하나의 대안이 될 수 있다.[2] Spearman, C. (1904). "General intelligence": Objectively determined and measured. The American journal of psychology, 15(2), 201-292.[3] Brown, T. A. (2006). Confirmatory factor analysis for applied research. Guilford Publications.[4] Note. 여기서 각각의 수치들은 대충 이런 느낌이라는 의미에서 임의로 입력한 것이다.[5] Note. 여기서도 각각의 수치들은 느낌만 전달하기 위해 임의로 입력한 것이다. 위의 행렬을 실제로 회전했을 때 이 행렬이 나오는 것이 절대 아니다.[6] Fabrigar, L. R., & Wegener, D. T. (2012). Exploratory factor analysis. Oxford University Press.[7] 앞의 예시에서 '문항' 이라고 불렀던 하나하나를 이제부터는 지표변인이라고 부르기로 하겠다. 심리학의 경우 실제로 지표변인이 대개 설문지 문항이 되는 경우가 많지만, 당장 교육학의 경우만 봐도 각 지표변인은 국/영/수/사/과 같은 과목명이 되는 경우가 많다.[8] Wall, M. M., & Amemiya, Y. (2007). A review of nonlinear factor analysis and nonlinear structural equation modeling. In Cudeck, R., & MacCallum, R. C. (Eds.), Factor analysis at 100: Historical developments and future directions (pp. 337-362). Routledge.[9] Hair, J. F., Anderson, R. E., Tatham, R. L., & Black, W. C. (1995). Multivariate date analysis with readings. Englewood Cliff, NJ: Prentce.[10] Tabachinick, B., & Fidell, L. S. (2007). Using multivariate statistics. Chicago.[11] Gorsuch, R. L. (1983). Factor analysis (2nd Ed.). Hillsdale, NJ: Erlbaum.[12] Arrindell, W. A., & van der Ende, J. (1985). An empirical test of the utility of the observations-to-variables ratio in factor and components analysis. Applied psychological measurement, 9, 165-178.[13] MacCallum, R. C., Widaman, K. F., Zhang, S., & Hong, S. (1999). Sample size in factor analysis. Psychological methods, 4(1), 84-99.[14] Fabrigar, L. R., Wegener, D. T., MacCallum, R. C., & Strahan, E. J. (1999). Evaluating the use of exploratory factor analysis in psychological research. Psychological methods, 4(3), 272-299.[15] Arbuckle, J. L. (1996). Full information estimation in the presence of incomplete data. In G. A. Marcoulides & R. E. Schumacker (Eds.), Advanced structural equation modeling: Issues and techniques (pp. 243–277). Mahwah, NJ: Erlbaum.[16] Timm, N. H. (1970). The estimation of variance-covariance and correlation matrices from incomplete data. Psychometrika, 35, 417–437.[17] Bartlett, M. S. (1950). Tests of significance in factor analysis. British journal of mathematical and statistical psychology, 3(2), 77-85.[18] Kaiser, H. F. (1974). An index of factorial simplicity. Psychometrika, 39(1), 31-36.[19] Cattell, R. B. (1966). The scree test for the number of factors. Multivariate behavioral research, 1, 245-276.[20] Guttman, L. (1954). Some necessary conditions for common-factor analysis. Psychometrika, 19, 149-161.[21] Kaiser, H. F. (1960). The application of electronic computers to factor analysis. Educational and psychological measurement, 20, 141-151.[22] Zwick, W. R., & Velicer, W. F. (1986). Comparison of five rules for determining the number of components to retain. Psychological bulletin, 99, 432-442.[23] Cliff, N. (1988). The Eigenvalues-Greater-Than-One rule and the reliability of components. Psychological bulletin, 103, 276-279.[24] Horn, J. L. (1965). A rationale and test for the number of factors in factor analysis. Psychometrika, 30(2), 179-185.[25] Velicer, W. F. (1976). Determining the number of components from the matrix of partial correlation. Psychometrika, 41, 321-327.[26] Tucker, L. R., & Lewis, C. (1973). A reliability coefficient for maximum likelihood factor analysis. Psychometrika, 38(1), 1-10.[27] Kaiser, H. F. (1958). The Varimax criterion for analytic rotation in factor analysis. Psychometrika, 23, 187-200.[28] Harman, H. H. (1967). Modern factor analysis (2nd Ed.). Chicago: University of Chicago Press.[29] Jennrich, R. I., & Sampson, P. F. (1966). Rotation for simple loadings. Psychometrika, 31, 313-323.[30] Harris, C. W., & Kaiser, H. F. (1964). Oblique factor analytic solutions by orthogonal transformations. Psychometrika, 29, 347-362.[31] Tabachnick, B. G., & Fidell, L. S. (1989). Using multivariate statistics. San Francisco; Harper & Row.[32] Note. 바로 위의 질문을 뒤집으면 바로 이 질문이 된다. 분산의 중복설명 가능성을 인정하는 것이 더 현실적이지만, 그 경우 각각의 요인이 갖는 고유값을 명확하게 확신할 수 없어지게 된다. 분석가에게는 양날의 검인 셈.[33] Howell, R. D., Breivik, E., & Wilcox, J. B. (2007). Reconsidering formative measurement. Psychological methods, 12(2), 205-218.[34] Jöreskog, K. G. (1970). A general method for estimating a linear structural equation system. ETS Research Bulletin Series, 1970(2), i-41.[35] Arbuckle, J. L., & Wothke, W. (1999). AMOS 4.0 user's guide. Chicago, IL: SmallWaters Corporation.[36] 공통요인적재, 고유요인적재 등의 용어도 위의 다변량 회귀식을 이리저리 뜯어보다보면 자연스럽게 나오는 해석이다.[37] Wright, S. (1918). On the nature of size factors. Genetics, 3, 367-374.[38] Sobel, M. E. (1982). Asymptotic confidence intervals for indirect effects in structural equation models. Sociological methodology, 13, 290-312.[39] 김청택 (2016). 탐색적 요인분석의 오·남용 문제와 교정. 조사연구, 17(1), 1-29.