로마자
덤프버전 :
분류
1. 개요[편집]
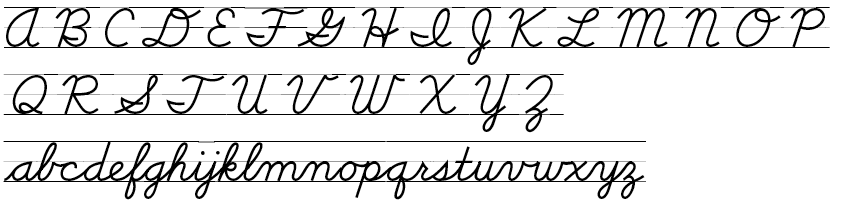
고대 로마에서 라틴어 표기에 사용되었던 문자를 바탕으로 하는 문자. 라틴 문자라고도 한다.
한국에서 가장 흔하게 접하는 로마자 사용 언어가 영어인 관계로 흔히 영문(英文)이라고 부르는 경우가 많다. 로마자는 영어를 포함한 수많은 언어를 표기할 때 쓰이는 문자이고 '영문'은 '영어로 된 글'을 뜻하므로 근원적으로는 '로마자=영문'이 아니다. 물론 표준국어대사전에서 '영어를 표기하는 데 쓰는 문자'라고는 쓰며, 이는 맞는 설명이지만, 이것이 '로마자=영문'임을 말한다고 볼 수는 없다. 영어를 표기하는 데 로마자가 주로 쓰이지만, 로마자는 또한 (표준국어대사전의 설명처럼) 라틴어를 적는 데도 쓰이고, 프랑스어, 독일어, 이탈리아어, 네덜란드어 등을 표기할 때도 쓰이기 때문이다. 더군다나 '로마자'는 문자의 개념이요 '영문'은 글로 적힌 언어의 개념이므로 이미 여기서부터 뜻이 다르다.
한편 로마자를 알파벳이라고 부르는 것은 얘기가 좀 달라지는데, 알파벳은 문자 체계 또는 음소문자를 가리키는 말이라 틀린 말은 아니지만 약간 부족한 표현이다. '알파벳'이라고 할 수 있는 문자가 로마자만 있는 것은 아니기 때문이다. 당장 한글도 알파벳의 일종이다.[2] 굳이 쓰자면 라틴 알파벳이라는 표현이 더 구체적인 표현이다.
영어를 로마자로 표기한다면 '영어 알파벳'이라고 쓰면 된다. 그러나 영어 외의 언어를 표기할 때 로마자를 쓴다면 그에 맞게 이름을 붙인다.[3] 말하자면 로마자는 '영어 알파벳'이기도 하고 '프랑스어 알파벳'이기도 하고 '스페인어 알파벳'이기도 하다.[4] 한국 표준국어대사전에서는 로마자와 라틴 문자 모두 표제어로 들어가 있지만, 국어의 로마자 표기법 등 실제 용례에서는 로마자의 비중이 압도적으로 높다.
2. 사용 범위[편집]
현재 세계에서 가장 광범위하게 쓰이는 문자로 현재 지구의 보편문자라고 볼 수 있다. 로마자를 사용하는 지역으로는 남유럽[5]과 서유럽, 북유럽, 동유럽 일부[6], 사하라 이남 아프리카[7], 아메리카, 오세아니아에서 사용하며, 또한 아제르바이잔, 투르크메니스탄, 우즈베키스탄, 동남아시아[8] 일부 국가에서 사용한다.
심지어 로마자를 주 문자를 사용하지 않는 지역에서조차 보조 문자로서 적극적으로 사용되고 있다. 당장 한글을 쓰는 한국어도 그러하다. 예컨대 한국의 대표적인 방송국인 KBS, SBS, MBC 등을 '케이비에스', '에스비에스', '엠비시'로 쓰지 않고 로마자로 쓰고 있다.[9][10] 이러한 줄임말이 아니더라도 오히려 한글로 충분히 표기할 수 있는데도 굳이 로마자를 쓰는 경우가 많아서 비판의 대상이 되기도 할 정도로 많이 쓰인다. 특히 1990년대 이후 국내 주요 기업들도 한자어 기반의 기존 사명을 로마자 알파벳으로 바꾸는 사례가 매우 많다. 대표적 예시로는 선경 → SK, 럭키금성 → LG, 한국통신 → KT, 제일제당 → CJ 등이 있다. 은행권 역시 NH농협은행, KB국민은행, MG새마을금고, KDB산업은행, IBK기업은행, Sh수협은행처럼 기존 사명 앞에 로마자를 사용하는 경우가 많아졌다.
인터넷 은어나 각종 줄임말로 로마자를 쓰는 경우는 로마자를 쓰지 않는 언어에서도 흔하며, 생소한 언어를 사용하는 이유 등으로 고유 문자의 전산화가 어려운 경우 로마자로 쓰인 문장을 댓글이나 인스턴트 메신저로 사용하는 일도 있다. 동남아시아의 일부 언어(미얀마어, 크메르어 등)나, 아랍어 방언 같은 언어에서 이런 현상을 관찰할 수 있다.
전통적으로 영어, 스페인어, 프랑스어와 같은 유럽 언어들을 표기하는 수단이었으며, 근대에 이들의 문화가 전세계로 퍼지면서 각국의 사람들이 자의든 타의든 필연적으로 접하게 되는 문자가 되었다.
튀르크어족의 경우 점점 로마자로 갈아타는 추세이다. 현재 로마자를 사용하는 튀르크어족 언어들은 튀르키예어[11], 아제르바이잔어, 투르크멘어, 우즈베크어가 있고[12], 카자흐어도 2025년부터 로마자로 전환할 예정이다.[13] 키르기스어도 키르기스스탄 정부에서 카자흐스탄의 방식을 따라가겠다고 밝혔다. 다만 위구르어와 남아제르바이잔 아제리어 표기에는 아랍 문자가 주로 쓰인다. 1920년대에 소련시절에 기존의 아랍문자를 라틴문자로 개편하려다가 1930년대에 키릴문자로 갈아탔는데 이걸 다시 원복하는 셈이다.
옆나라 불가리아의 영향으로 루마니아어도 키릴 문자를 사용하다가 1860년 민족주의와 라틴 복고주의[14]의 영향으로 로마자로 갈아탔다. 소련에 복속당한 몰도바에서는 예외적으로 키릴 문자로 재전환[15]했으나, 독립 직전인 1989년 루마니아어 로마자로 전환했다.[16] 다만 친러계 지역인 트란스니스트리아에서는 여전히 몰도바어를 키릴 문자로 표기하고 있다.
2021년 최근 우크라이나도 기존에 쓰고 있는 키릴 문자를 버리고 라틴 문자로 전환하려는 움직임이 일부 있고, 러시아가 강력히 반발하고 있을 뿐만 아니라 현지에서도 소련시절에 라틴문자로 전환하려다가 실패한것을 왜 유럽과 가까이 한다고 정통성을 배격하면서까지 또 하냐며 헛소리 취급이다. 사실 우크라이나어의 로마자 전환은 다른 구 소련권 국가들의 로마자 전환과는 다른데, 정교회와 키릴 문자를 처음으로 받아들인 고대 국가가 바로 현대 우크라이나에 있는 키예프 루스이기 때문이다.
3. 각 언어의 로마자[편집]
흔히 로마자라고 하면 주로 영어에서 쓰는 A부터 Z까지를 떠올리지만, 자국 언어의 특수한 발음을 나타내기 위해서 또는 동철이의어를 구분하기 위해서 만들어진 확장 로마자들도 상당히 많다. 라틴 문자를 표기 문자로 쓰는 언어들이 매우 많고 문자 자체의 역사도 상당히 오래되어 같은 글자라도 언어마다 발음과 명칭이 제각각이니 라틴 문자를 알고 있어도 언어를 배울 때마다 발음과 명칭을 새로 배워야 한다.
반대로 안 쓰는 알파벳을 빼기도 한다. 이런 연유로 영어의 알파벳 개수는 26자지만 키리바시어에선 13개 알파벳만을 사용하고, 슬로바키아어의 알파벳은 46자다. 그리고 베트남어에서는 기본 알파벳 29자에다가 모음에 붙는 성조 기호 5가지 때문에 89개나 되는 글자를 사용한다. 각 언어의 고유어에 안 쓰는 로마자는 아래와 같다.
- B: 핀란드어, 마오리어, 하와이어, 사모아어
- C: 우랄어족(헝가리어 제외), 북게르만어군(스웨덴어 제외)
- F: 우랄어족(헝가리어 제외), 베트남어
- J: 이탈리아어, 게일어군, 베트남어
- K: 로망스어군, 게일어군
- Q: 게일어군, 북게르만어군, 슬라브어파, 발트어파, 우랄어족, 루마니아어, 터키어
- V: 게일어군, 폴란드어, 투르크멘어
- W: 아일랜드어, 북게르만어군, 슬라브어파(폴란드어 제외), 튀르크어족(투르크멘어 제외), 베트남어, 알바니아어, 이탈리아어, 일부 유럽 언어
- X: 북게르만어군(스웨덴어, 아이슬란드어 제외), 이탈리아어, 슬라브어파(체코어, 슬로바키아어 제외), 발트어파, 우랄어족, 게일어군, 터키어
- Y: 네덜란드어[17], 이탈리아어, 포르투갈어, 몰타어, 아일랜드어, 루마니아어, 세르보크로아트어, 라트비아어, 에스토니아어
- Z: 북게르만어군, 게일어군, 베트남어, 우랄어족(헝가리어 제외)
- 다중 문자에만 들어가는 로마자
- C: 독일어(ch, ck, sch, tsch), 스웨덴어(ck)
- G: 핀란드어(ng)
- Q: 서게르만어군, 베트남어, 로망스어군(루마니아어 제외)(qu)[18]
- Y: 헝가리어(gy, ly, ny, ty)
- diacritic이 붙은 형태로만 쓰는 로마자
- C: 몰타어(Ċ), 투르크멘어(Ç)
고전 라틴어 알파벳의 이름과 음가는 다음과 같다.
한편 비교적 친숙한 영어 알파벳은 다음과 같다. 알파벳 이름은 지역에 따라 달라지는 경우가 종종 있다.
한국에서는 영어식의 로마자 이름을 쓴다. 그러나 영어식과는 다른 특징도 보이는데, Z는 일반적으로 네덜란드어식인 '제트'를 쓰며, 표준어에선 두드러지지 않지만, 동남 방언에선 E와 O에 /ʔ/ 발음이 섞여 있다.[23]
대부분의 한국어 화자들은 R을 '알'로 읽지만, 실제로는 이런 발음 및 그에 따른 한글 표기가 어문규범에 어긋나는 것이었던 적이 있다. 당시에는 '아르'로만 읽도록[24] 규정해 두었기 때문에, 절대 다수가 R은, R이 등의 표기를 쓰지만 R는, R가 등으로 써야 했었다. 하지만 국립국어원이 2023년 1월 19일부로 '알'도 '아르'와 마찬가지로 복수 표준인 것으로 변경하면서(기사), 현재는 양쪽 중 어느 표기를 사용해도 무방하게 됐다.[25]
4. 역사[편집]
4.1. 기원[편집]
이름처럼 고대 로마, 즉 라틴어에서 이 문자를 맨 처음 사용했다. 하지만 문자 체계 자체가 라틴어에서 나온 것은 아니고, 이 비슷한 문자 체계의 조상을 거슬러 올라가다 보면 순서대로 에트루리아 문자, 그리스 문자와 페니키아 문자, 이집트 상형문자까지 거슬러 올라간다. 하지만 이 문자가 지금의 형태로 정립되고 나서는 이 문자를 맨 처음 사용한 언어가 라틴어였기 때문에 라틴 문자, 혹은 로마자라고 부르는 것. 직접적인 기원은 에트루리아 문자이며, 이 문자는 에트루리아인들이 그리스 문자, 정확히는 그리스 서부에서 쓰이던 그리스 문자를 받아들여 변형한 것이었다. 이후 그리스 문자는 그리스 동부에서 쓰이던 것으로 표준화되었기에, 그리스 문자와 로마자의 모양새는 조금 달라졌다.
기원전 7세기쯤의 로마자는 현재 우리가 보고 있는 글자꼴과 매우 달랐으며 문자 배열도 동시기 그리스 문자와 별 차이가 없었다. C의 경우 원래는 그리스어 Γ에서 유래한 것이기 때문에 현재의 G를 나타냈었고, 현재는 맨 끝 번째 문자로 분류되는 Z가 당시에는 G가 올 위치에 있었다. 그러다 수많은 변화를 급격하게 거쳐 기원전 1세기쯤 현재와 같은 배열을 가지게 되었으며, 동시에 '고 이탈리아 문자'라고도 불리는 그리스-에트루리아 글자꼴에서 탈피하여 우리가 현재 보고 있는 것과 비슷한 대문자 글씨체(CAPITALIS MONVMENTALIS)로 정착되었다.
4.2. 발전[편집]
고대 로마(기원후 1세기) 때 쓰이던 로마자는 지금과 다른 점이 있었다. 아래는 그 예시.
- 반모음 J가 없고 반모음 I 발음도 I로 표기하였으나, 나중에 I를 아래로 길게 늘인 J로 반모음으로서의 쓰임을 표기하게 되었다. 즉 단모음 I와 반모음 J가 구별되지 않는다.[26]
- U를 V로 적는다. 그러니까 IESU는 IESV. U는 기원후 3세기 무렵 등장했다.[27] 즉 단모음 U[u]와 반모음 V[w]가 구별되지 않는다. W가 V 두 개를 합친 건데 영국 및 미국에서 double-U라 하고 타 유럽 국가(독일, 프랑스 등)에서는 도피아 부, 두블르 베, 베 등으로 부르는 이유이다. 대표적인 예가 스페인 제국의 표어인 PLVS VLTRA. 명품 브랜드 불가리(BVLGARI)도 이탈리아식으로 작명한 것이다.
- 소문자가 없고 대문자만 있다. 정확히는 로마 필기체라고 소문자의 원형이 된 필기체가 존재했으나 공식 문서에서는 철저하게 대문자만 쓰였다. 로마제국 말기에 양피지나 파피루스 필사본의 가독성을 높이기 위하여 로마 필기체에서 발전이 된 언셜체가 유행했는데 여기에서 소문자 체계가 천천히 단계적으로 발전하여 1300년대 이후부터 현재와 같은 소문자 체계가 정립되었다.
- 띄어쓰기가 없었다. 초기의 문자들이 그랬듯이 구어를 소리나는 그대로 기록했고, 독자는 이걸 소리내 읽어서 해석해야 했다. 판테온#로마의 건축물 정문의 명문과 같이, 일부 경우에는 단어 사이에 해석을 돕기 위한 가운뎃점을 넣기도 했다. 띄어쓰기가 도입된 건 600~800년경.
- 현대 서게르만어군[28]에서 많이 쓰이는 W가 없다. 실제로 프랑스어, 스페인어 등 라틴어에서 파생한 로망스어군 언어, 덴마크어와 스웨덴어, 노르웨이어 등 북게르만어군 언어, 폴란드어를 제외한 슬라브어파 언어[29] 등은 외래어가 아닌 이상 W를 쓰지 않는다. 글자 이름(더블유)에서 보듯 W는 후대에 U를 2개 연이어 쓰는 게 귀찮아서 만든 문자이기 때문. 이와 비슷하게 독일어에서는 S를 2번 연달아 쓴 ſs가 ß(에스체트)가 되었고, 네덜란드어의 IJ는 아프리칸스어에서 Y가 되었다.
4.3. 전파[편집]
고대 로마의 영역이 지중해 전역으로 확장하면서 라틴어와 로마자도 같이 확산되었다. 고대 말과 중세 초기에 라틴어에서 갈라진 로망스어군 언어들의 표기에도 당연히 로마자가 쓰였다.
한편 같은 유럽 내에서 고대 게르만족은 룬 문자를 가지고 있었고, 고중세 아일랜드어 표기에는 오검 문자를 썼다.[30] 중세에 유럽으로 이주한 헝가리는 로바시 문자를 썼다.[31] 하지만 이들 문자는 기독교의 전파와 함께 로마자로 대체되었다.
로마자가 서유럽에 뿌리내린 이후 서유럽인들은 2000년 동안 말 그대로 지구 각지를 정복하며 자신들이 쓰던 문자도 전파하고 다녔고 이들에게 정복당한 민족들은 식민 본국에 의해 강제적이나 자발적으로 로마자를 표기 수단으로 채택하여 현재는 명실공히 사용자 수 1위의 문자가 되었다. 그 예로 베트남어, 말레이어, 스와힐리어 등을 들 수 있다.
제국주의 도래 이후에도 기존에 사용하던 문자가 있었음에도 로마자로 대체한 경우는 대표적으로 중앙아메리카 국가들과 베트남, 말레이시아, 인도네시아, 필리핀이 있다. 이들 국가의 고유 문자들은 습득이 매우 어려워서 문맹 퇴치에 별로 도움이 되지 않았으므로, 민족주의자들 사이에서도 로마자를 도입하는 것이 차라리 낫다는 여론이 지배적이었기 때문이다.
튀르크어족 언어들의 경우 1920년대에 소련과 튀르키예 공화국에서 로마자 보급을 시도하였다. 소련에서는 1926년에 자국 내 튀르크계 민족 언어에 로마자를 보급했고, 튀르키예에서는 1928년에 본격적으로 튀르키예어의 로마자 도입이 실시되었다. 소련에서 영토 내 튀르크계 민족들이 쓰는 튀르크어족 언어들에 로마자를 도입하였는데, 이것이 튀르키예에도 자극을 주어 튀르키예어의 로마자 보급을 도왔고,[참고] 튀르키예 역시 소련의 로마자 보급에 영향을 주었다(참고 자료). 튀르키예어의 로마자 표기는 현재까지 그대로 계속 사용되고 있다. 반면 소련에서는 1940년대 이오시프 스탈린 집권 시기에 튀르크어 표기가 키릴 문자로 대체되었고, 1991년 소련 붕괴 이후 아제르바이잔어(남아제르바이잔 제외), 투르크멘어, 우즈베크어에는 로마자 표기를 재도입하였지만 카자흐어, 키르기스어, 기타 러시아 영토 내 튀르크계 소수민족들의 언어에는 여전히 키릴 문자가 쓰인다.
중국은 중국어 표기를 위해 병음이라는 로마자 표기법을 쓰고, 일본은 컴퓨터에서 일본어를 입력할 때도 대부분 로마자를 쓴다. 키릴 문자권만 해도 특정한 경우에 로마자를 쓰니 어찌 보면 로마 제국이 문자로 세계정복에 성공했다고 해도 과언이 아니다. 전 세계에서 통용되는 국제 신분증인 여권에도 이름을 반드시 로마자로 적어 넣어야 한다. 북한마저도 영어를 '영국말', '국제 공용어', 미국 영어의 경우 '알아야 하는 적들의 말' 정도로 우기는 상황이라 로마자의 확산은 피하지 못했다.[32]
로마자의 세계적 영향력을 잘 보여주는 것이 교과서와 각종 매체에서의 로마자 표기이다. 이에서는 로마자를 쓰지 않는 지역의 인물이나 지역명 등에도 그 지역 문자의 표기를 무시하고 한글 표기와 함께 로마자 표기를 적는다. 과거부터 로마자는 외래 지역명이나 외래 단어에 대한 표기가 오래 전부터 확립되어 있었고, 로마자와 한자 외의 외래 문자는 한국에서 익숙하지 않고 외래어 한글 표기가 비교적 일관성을 띄게 된 건 몇십 년이 채 되지 않는다. 따라서 대부분의 외국어는 편의 상 로마자로 적는 게 당연한 귀결이다. 만약 원 문자 존중으로 나가면 아랍인은 아랍 문자로, 태국인은 태국 문자로, 인도 사람은 데바나가리 문자로, 미얀마 사람은 버마 문자로, 에티오피아 사람은 그으즈 문자로, 메소포타미아인은 쐐기 문자로, 이집트인은 상형문자로, 옛 베트남 사람은 쯔놈[33]으로. 이런 식으로 다양하게 적어야 될 텐데 알아볼 사람이 거의 없을 것이다.
한편 한반도에서 공식적으로 로마자를 접한 시기는 1797년에 이양선인 영국 해군 브로턴의 프로비던스 호가 조선을 방문했던 시기인데 이때 로마자를 처음 접한 조선 관리는 "붓을 주어 쓰게 하였더니 모양새가 구름과 산과 같은 그림을 그려 알 수 없었습니다."라고 언급했다. 또한 비공식적으로 로마자를 접한 시기는 헨드릭 하멜이 조선에 상륙했던 시기인데 제주목사 이원진이 의사소통을 시도하자 "말이 통하지 않고 문자도 다릅니다."라고 보고했다는 조선왕조실록의 기록이 있다.
5. 로마 숫자[편집]
 자세한 내용은 로마 숫자 문서를 참고하십시오.
자세한 내용은 로마 숫자 문서를 참고하십시오. 6. 과학·수학에서의 활용[편집]
자세한 내용은 과학/기호 문서를 참고하십시오. 7. 오해[편집]
7.1. 알파벳(음소문자)?[편집]
영어에서는 Latin alphabet이라고 잘 부르고 한국어에선 '로마자'라고 자주 부른다. 영어로 Roman alphabet이라고 부르는 경우나 한국어로 라틴 문자라고 부르는 경우는 둘 다 잘 없다.
보통 알파벳이라고 알고 있는 문자. '알파벳'은 자음과 모음을 각각 별도의 글자로 분리해서 쓰는 문자 체계[34] 전체를 가리키는 말이지 로마자 하나만을 가리키는 것이 아니다. 그래서 러시아에서 쓰는 키릴 문자나 그리스에서 쓰는 그리스 문자도 알파벳이고[35], 한글도 일종의 알파벳(음소문자)이다.
7.2. 로마자 = 영어?[편집]
일반적으로 '로마자'와 '영어'를 개념적으로 혼동하는 사람이 많지만 그렇지 않다. 대표적인 경우가 '이름을 영어로 적어라'와 같은 경우. 그러나 '한민수'라는 이름을 Han Minsu라고 적는다고 해서 영어인 것은 아니고, 한국어로 된 이름을 로마자로 표기한 것일 뿐이다. 그러므로 좀 더 정확한 표현은 '이름을 로마자로 적어라'이다. 반대로 James를 '제임스'라고 적는다고 해서 영어 이름이 한국어 이름으로 바뀌는 것도 아니다. 무조건 로마자 = 영어라는 식이라면 반대로 '한자로 쓴다'는 것도 '중국어로 쓴다'가 되어야 할 것이다.
로마자는 문자이고, 영어는 언어다. 이는 다른 문자, 다른 언어도 마찬가지이다. 언어는 의사소통을 할 때 쓰는 수단이고, 문자는 그 언어를 표기하기 위한 기호이다. 우리가 가장 쉽게 접할 수 있는 로마자로 된 언어가 영어이기 때문에 개념 혼동 현상이 일어나는 경우가 많다. 설상가상으로 일반적으로 한국인에게는 문자와 언어가 사실상 일대일 대응하기 때문에 더더욱 그런 문제가 발생하기 쉽다. 한글로 표기하는 언어는 한국어뿐이고 한국어를 표기하는데 쓰이는 문자도 한글뿐이기 때문. 이러한 이유 때문인지 로마자로 적힌 단어나 문장만 보고 이를 영어라고 속단하는 한국인들이 상당히 많다. 그나마 5~60년대까지는 영어라고도 안 했다. 미국말이라고들 했지. 그나마 영어에서 볼 수 없는 자소 배열이 있거나(예: Hrvatska, Bydgoszcz), 확장 라틴 문자(예: 스페인어의 Ñ, 독일어의 ß 등등)도 있으면 "이거 어느 나라 말이야?"라고 하니 좀 낫다.
로마자(라틴 문자) 표기와 영어 표기의 차이는 Hanguk과 Korea를 예로 들면 이해가 굉장히 쉬워진다. Hanguk은 한국어 '한국'의 '로마자 표기'이고, Korea는 한국어 '한국'에 대응되는 '영어 단어' 내지는 '영어 표기'이다. 결론적으로 Hanguk이란 표기는 한국어가 맞다! 단지 쓰는 문자가 다른 것뿐이지. 남아프리카 공화국도 '로마자 표기'라면 Namapeurika Gonghwaguk이 맞기는 하다.[36] '영어 표기'라면 완전히 틀렸지만.[37]
비슷한 개념 혼동 현상이 한국어와 한글 사이에서도 일어난다. 흔히 한국어를 한글로만 표기하기 때문에 한국어와 한글이 같은 개념인 줄 아는 사람이 많지만, 한국어는 언어고 한글은 그 언어를 표기하기 위한 문자 체계다.
물론 여기에 대해서는 어차피 언중 대다수가 로마자와 영어, 한글과 한국어를 명확하게 구분하지 않는 게 현실이니까 언중의 현실 언어 사용을 인정하여 '영어'를 로마자를 지칭하는 데에도 사용하는 말로, '한글'을 한국어를 지칭하는 데에도 사용하는 말로 인정하자는 의견도 있다. 다만 이와 같이 규정할 경우 상술한 원래 의미와 용법이 충돌하여 혼란이 생길 수 있으므로 현행대로 구분하는 게 보다 바람직하다는 것이 중론이다.
반대로 '일반적인 로마자 사용 언어에서 나타나는 보편적인 현상'이 아닌 '영어권에서의 로마자 표기 습관[38]'에 대해 이야기할 때 '영문/영어 표기'라 하는 경우도 있는데, 그것을 '로마자 표기'로 과도 교정하는 경우도 볼 수 있다. 이때는 영어라는 특정 언어에서 일어나는 현상을 가리키는 것이기 때문에 '영문/영어 표기'가 더 타당한 표현이지만, 이를 감안하여 '영어 표기'라고 써놓은 것을 수정자가 작성자가 영어와 로마자를 구분 못 하는 것으로 생각하고 '로마자 표기'로 고쳐놓는 사례도 있다.[39]
8. 관련 문서[편집]
 이 문서의 내용 중 전체 또는 일부는 2023-11-25 19:09:14에 나무위키 로마자 문서에서 가져왔습니다.
이 문서의 내용 중 전체 또는 일부는 2023-11-25 19:09:14에 나무위키 로마자 문서에서 가져왔습니다.[1] 알파벳의 어원이 그리스 문자의 알파 베타에서 따온 것이라면, 라틴어에서도 알파벳이 아 A 베 Be 케 Ce 데 De에서 시작하여 옆과 같은 이름이 나왔다.[2] 한글을 영어로 번역하면 KOREAN ALPHABET이 되기도 하고 심지어 '알파벳'이라는 단어의 근원이 된 '알파'와 '베타'는 그리스 문자이다. [3] 그렇기 때문에 독일어 등에서 쓰이는 '확장 로마자'는 '영문자'도 아니고 '영어 알파벳'도 아니다. '확장 로마자'는 영어에서는 샬럿 브론테의 사례처럼 인명을 포함한 고유명사에서 쓰이는 경우가 있기는 하지만 극소수에 불과하다. 그냥 영어에서는 거의 쓰이지 않는다고 보면 된다. 로마자/확장 문자 참고.[4] 마찬가지로 한글은 '한국어 알파벳'이라고 할 수 있고 그리스 문자는 '그리스어 알파벳'이라고 할 수 있다.[5] 그리스 문자를 사용하는 그리스 제외.[6] 에스토니아, 라트비아, 리투아니아, 체코, 폴란드, 헝가리, 슬로바키아, 슬로베니아, 크로아티아, 알바니아, 보스니아 헤르체고비나, 코소보, 세르비아, 북마케도니아, 루마니아, 몰도바[7] 중동으로 분류되는 북아프리카와 아프리카에서 유일하게 독자적인 문자가 있는 에티오피아는 제외[8] 베트남, 말레이시아, 싱가포르, 브루나이, 인도네시아, 동티모르, 필리핀.[9] 다만, 한글 기업명 등록과 같은 일부 경우에서는 로마자를 인정하지 않아서 영문 약칭으로 된 회사들도 한글로 등재해야 한다. 대표적으로 SK텔레콤의 경우, 한글 기업명 등록 명칭이 '에스케이텔레콤 주식회사'이다.[10] 예외적으로 한겨레는 알파벳도 한글로 옮겨 적고 있다. 한국어 명칭이 존재하는 KBS와 MBC는 각각 '한국방송'과 '문화방송'으로 적고, SBS의 경우에는 '에스비에스'로 적는다. ('서울방송'은 2000년 이후 쓰이지 않는 옛 사명이다.) 해외 기업의 경우에는 해당국 발음을 따라 적는다. 대표적으로 BMW는 국내 법인명이 '비엠더블유'임에도 독일어대로 '베엠베'라고 적으며, 핀란드 공영방송 YLE를 '위엘에', 노르웨이 공영방송 NRK를 '엔에르코'로 표기한다.[11] 튀르키예가 로마를 멸망시킨 오스만 제국의 후예라는 걸 생각해 보면 아이러니하다.[12] 다만 우즈베키스탄은 실질적으로는 키릴 문자와 혼용되고 있다. 우즈베크어 문서 참조.[13] 이미 국장은 2018년에 키릴 문자에서 로마자로 바꾸었다.[14] 루마니아 자체가 로마인의 땅이란 뜻이다.[15] 이전에 루마니아가 사용하던 키릴 문자 체계와는 다소 차이가 있다.[16] 소련 시기부터 독립 이후로도 한동안은 언어 자체도 '몰도바어'로 규정되어 왔으나, 2013년 몰도바 헌법재판소에서는 몰도바의 국어를 '루마니아어'로 규정했다.[17] 그러나 ij의 대체 철자로 종종 쓰이고, 아프리칸스어에서는 ij가 그냥 y로 바뀌었다.[18] 프랑스어의 경우 coq, cinq 등의 예외가 있다.[19] 영어, 로망스 계열 언어 등과 다르게 뒤에 어떤 모음이 와도 항상 /k/로 발음한다.[20] 뒤의 모음이 u일 때만 쓰인다.[21] c와 음가가 같아서 c의 사용에 밀려 라틴어에서는 거의 쓰지 않는다. 원래 /k/ 음가를 표기할 때, a 앞에는 k, e·i 앞에는 c, o·u 앞에는 q를 썼으나 나중에는 c로 합쳐졌다.[22] 독일어의 ü 음가와 같다. 입술을 ㅜ 모양으로 하고 ㅣ를 발음하는 방법이었다. 지금은 그냥 ㅣ로 읽는다. i graeca는 그리스 i라는 뜻으로서 그리스어 계얼의 차용어에서 입실론(Υ)을 표기할 때 사용되었다. 원래 라틴어에는 없는 음가라서 이를 아는 사람은 /y/로 발음하였으나 그렇지 않은 사람은 /i/로 발음하였다.[23] E - /ʔi/, O - /ʔo/이다. 숫자 2, 5와 구별하기 위해서일지도 모른다. (독일어도 형태소 첫 부분에 모음이 오면 /ʔ/ 발음을 넣는 경향이 있다.) 로마자와 숫자가 섞여 있는 상황이 제법 많다는 걸 감안하면...[24] 받침 ㄹ은 L 발음이라는 점 등을 이유로 볼 수 있다. 실제로 L은 공식적으로나 현실적으로나 '엘'이라는 이름만 쓰이지 '에르'라고는 전혀 말하지 않는다는 점에서 R과는 상황이 대조적이다.[25] 이에 따라 수능 모의평가 등의 공식적인 문서에서도 조사를 R이라처럼 붙이기 시작했으며, 현실적인 표기가 쓰이는 곳이 점점 늘어날 것으로 보인다.[26] 따라서 영어 JESUS(지져스)의 본래 발음은 IESUS(이에수스), 즉 예수인 셈.[27] 스페인의 국가 표어에 그 흔적이 남아 있다. PLVS VLTRA라 적혀 있는데, 지금으로 하자면 PLUS ULTRA. 플브스 블트라가 아니다.[28] 영어, 네덜란드어, 독일어, 아프리칸스어, 이디시어 등[29] 그 대신에 폴란드어는 V를 쓰지 않는다.[30] 다만 이 두 문자도 상기한 로마자의 극초기 형태에서 파생되었단 것이 정설이다.[31] 돌궐문자에서 파생되었다고 추정된다.[참고] Zürcher, Erik Jan. Turkey: a modern history, p. 188. I.B.Tauris, 2004. ISBN 978-1-85043-399-6[32] 북한 표준어 규범인 문화어의 규범으로는 '조선어의 라틴문자 표기법'에서 보듯 그냥 '라틴문자'라고 한다.[33] 한자 표기를 특정할 수 있는 옛날 인물은 지금도 한국식 발음으로 읽곤 한다. 호찌민을 호지명이라 읽는 식.[34] 굳이 이런 분류를 별도로 만들어 이름까지 붙여주는 이유는 자음에 내재 모음을 찍는 아부기다, 자음만 표기하는 아브자드나 음절 단위로 표기되는 음절문자 등 다른 문자 체계도 존재하기 때문이다.[35] 오히려 알파벳이라는 이름이 그리스 문자의 앞 순서 글자인 알파(α)와 베타(β)에서 유래했다.[36] 링크된 기사에서도 Namapeurika Gonghwaguk이라고 쓴 것을 '소리나는 대로 영어로 표기한 것'이라고 말하는 오류를 범하고 있다.[37] 비슷한 예시로 키릴 문자로 표기하는 러시아어의 로마자 표기도 있다. (예시: Fyodor Dostoevsky)[38] 체계를 갖춘 비로마자권의 로마자 표기법에 의한 철자를 영문 표기에서 따라가지 않는 경우도 포함한다.[39] 정확히 구분한 예시: "경희대학교의 영문 표기는 Kyunghee University인데, 이것은 국어의 로마자 표기법을 따르지 않은 것이다."