파운드리간 기술력 비교
덤프버전 :
분류
1. 개요[편집]
선단공정 상위 4개사의 기술력 비교에 대한 문서.
- 사업 관련 내용이나 팹리스 사로부터의 수주와 관련된 내용은 윗 문단에 적고 본 문단에는 기술적인 부분만 작성합니다.
- PPA의 비교는 되도록이면 동일 아키텍처를 통하여 비교합니다.
파운드리 업계에서 10nm 혹은 그 이하의 미세공정 양산에 성공한 기업은 현재 시점에서 TSMC와 삼성전자 파운드리 사업부, 인텔이 존재한다. UMC 등의 파운드리 회사들이 미세공정 양산을 위하여 연구중이지만 위에 언급된 3개의 회사를 따라잡기에는 역부족인 것으로 보여지고, 중국의 SMIC가 유일하게 잠재력이 있는 것으로 보인다.[1]
이 4사의 기술력을 비교하기 위해서는 양산 수율이 어느 시점에 본 궤도에 올랐는지와, 공정 자체의 PPA, 즉 Performance, Power, Area 측면에서의 자료가 필요하다. Area, 즉 면적과 면적의 역수인 트랜지스터 밀도는 상대적으로 쉽게 파악할 수 있으나 Performance, Power는 각 회사들이 정보를 쉽게 공개하지 않기 때문에 최대한 비슷한 조건에서의 결과를 통하여 간접적으로 추론해 내야 한다. 아래의 비교 자료들도 PPA + 양산 시점을 기준으로 서술됐다.
2. 20/22 nm[편집]
[ SPEC 기준 성능, 전력 비교 데이터(클릭시 확대) ]


TSMC의 20nm 공정은 20SoC 라는 명칭이 부여됐고, 삼성전자 S.LSI(現 파운드리 사업부)의 20nm 공정은 20LPE라는 명칭이 부여됐다.
동일한 Cortex-A57, Cortex-A53 CPU를 20SoC, 20LPE에서 양산한 결과 두 공정간의 전력 대비 성능 격차는 매우 크게 벌어진다는 사실을 알 수 있다. 삼성의 Cortex-A57은 단 1.77W를 소모하는데 비해 TSMC의 Cortex-A57은 2.8W에 육박하는 전력을 소모하고, Cortex-A53은 Perf/W가 거의 두 배 차이로 벌어지는 것을 볼 수 있다. 물론 삼성이 사용한 Cortex-A57/A53은 ARM이 제공한 RTL에서 전력, 면적 측면을 개선 시키는 추가적인 최적화가 이루어 졌기 때문에 완전히 동일한 조건에서의 수평적인 비교라고 보기는 어렵지만, ARM측의 설계 미스가 분명히 존재했던 Cortex-A57이 아닌 Cortex-A53에서의 Perf/W가 2배 이상으로 벌어지는 것을 보았을 때 20SoC에 면죄부를 주기는 어렵다.
그리고 20SoC 공정에서 양산된 Apple Silicon A8도 매우 낮은 수준의 성능 증가폭을 보여주었다는 사실도 20SoC가 상대적으로 열세였다는 간접적인 증거가 될 수 있다. Apple A6과 A7은 전 세대 대비 CPU, GPU 성능 2배 증가, A9는 전 세대 대비 CPU 성능 1.7배, GPU 성능 1.9배 였지만, 20SoC에서 양산된 Apple A8은 CPU 성능은 전작 대비 25%, GPU 성능은 전작 대비 50% 향상에 그쳤기 때문이다.
[ 면적 관련 자료(클릭시 확대) ]

다만 셀 크기, 즉 면적 측면에서는 삼성의 20LPE가 TSMC의 20SoC 보다는 덜 미세하다는 사실을 알 수 있다. 20LPM은 CPP 86nm x M2P 64nm로 셀 크기 자체를 20SoC보다 더 미세하고 자사의 14LPE에 준하는 수준으로 줄였지만, 실제로 20LPM 공정은 사용된 사례가 존재하지 않는다. 요약하자면 면적 측면에서는 20LPE > 20SoC > 20LPM > 삼성 14nm 인 셈이다.
3. 16/14 nm[편집]
TSMC의 16nm는 16FF, 16FF+와 16FFC, 그리고 16nm에서 파생된 12FFN과 같은 공정들이 존재하고, 삼성의 14nm 또한 14LPE, 14LPP, 14LPC, 14LPU와 14nm에서 파생된 삼성 11LPP와 글로벌 파운드리의 12LP, 12LP+가 존재한다. 두 회사의 14nm와 16nm간의 비교는 Apple Silicon A9가 14LPE, 16FF 공정으로 혼용 생산이 이뤄지면서 많은 사람들과 IT 웹진들의 관심을 끌었다.
[ iPhone 6s 및 iPhone 6s Plus 내의 삼성 14LPE, TSMC 16FF 쓰로틀링 비교 그래프(클릭시 확대) ]
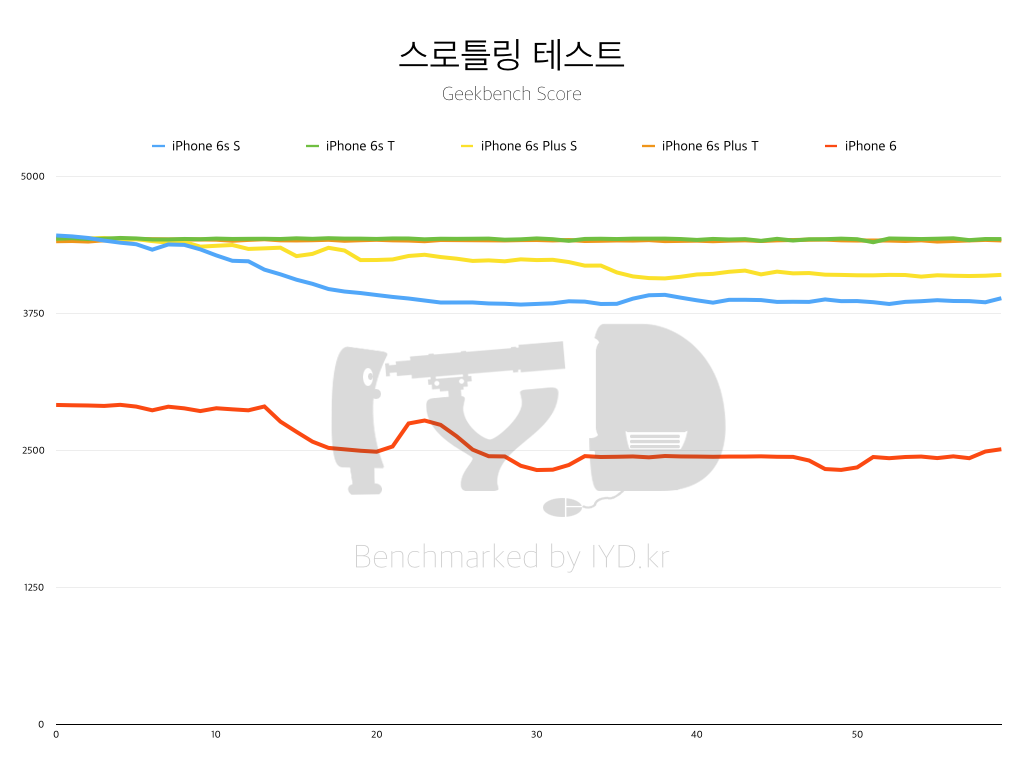
최초로 iPhone 6s와 iPhone 6s Plus가 공개됐을 때 각종 웹진에서는 두 회사에서 생산된 A9 간에 어떠한 차이가 있는지에 대하여 알아보기 위해 여러가지 테스트를 진행했다. 다른 항목에서는 삼성제 A9와 TSMC제 A9간에는 편차가 거의 존재하지 않았지만, Geekbench 3, 즉 CPU를 지속적으로 Full Load를 걸어서 혹사 시킬때 배터리 지속시간이나 성능 유지 측면에서 삼성제 A9가 더 낮은 결과를 보여줬다는 결과들이 다수 공개됐다. 이는 공정의 비교에 쓰이는 3가지 요소인 P / P / A중 첫번째 P인 성능(Performance), 즉 스피드 게인 측면에서 삼성 14LPE가 더 열등하다는 것이 아니냐는 주장이 제기됐다.
좌측의 그래프는 IYD에서 삼성제 / TSMC제 기기를 각각 2개씩 준비하여 Geekbench 3을 지속적으로 구동했을 때 쓰로틀링 특성이 어떠한 지에 대하여 측정한 결과이다. 이 결과를 참고하여 보면 TSMC제의 기기가 고클럭에서 더 유리하다는 사실을 간접적으로 추론할 수 있고, 반대로 우측의 그래프에서는 상대적으로 저클럭으로 구동이 되는 GPU를 지속적으로 혹사시켰을 때 삼성 14LPE가 더 유리하다는 사실을 간접적으로 추론할 수 있었다.
[ 클럭 특성 비교(클릭시 확대) ]

이러한 데이터들을 통하여 IYD 측(現 DrMOLA) 에서는 다음 사진과 같이 삼성의 14LPE와 TSMC 16FF간에 윗 그래프에서 보이는 것처럼 각 사의 공정마다 비교 우위를 가지는 클럭 대가 서로 다르다는 결론을 내렸다.
그러나...
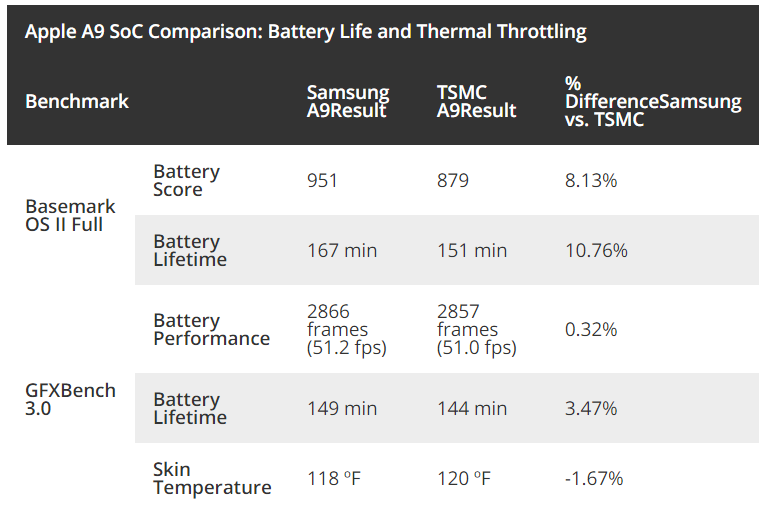
[ 쓰로틀링 비교 그래프(클릭시 확대) ]


그러나 표본수를 늘려서 비교해 본 결과 이번에는 삼성제 A9가 TSMC제 A9보다 Speed Gain 측면에서 우위를 점한다는 결과가 나오게 되고 각 사의 공정간의 우열 관계는 다시 매우 불명확해지게 됐다. 같은 iPhone 6s 내의 A9는 동일한 조건에서 TSMC가 Speed Gain이 더 높았지만, 같은 iPhone SE 내의 A9는 6S 내의 A9 쓰로틀링 테스트 결과에서 나타난 격차보다 2배 더 큰[2] 격차를 내면서 삼성제 A9가 더 앞섰기 때문이다. 일부 사이트에서는 삼성 14LPE를 폄하하기 위한 목적으로 표본 수가 적었을 때의 테스트 결과를 매직 그래프 수준으로 확대한 해당 그래프 사진 한 장만 다른 곳에 퍼 나르면서 악의적인 여론을 조성했고, IYD(現 DrMOLA) 측에서 표본 수를 늘려서 다시 테스트를 한 결과가 존재한다는 사실은 거의 알려지지 않은 측면이 존재한다.
이 문제에 대하여 Apple의 입장은 두 제조사가 생산한 Apple A9 간의 성능 차이는 없다. 라는 스탠스를 유지하고 있고, 해외 벤치마크 자료들도 삼성제 A9가 쓰로틀링 특성이 나쁘다는 결과와 TSMC제 A9가 쓰로틀링 특성이 나쁘다는 결과가 혼재되어 있다. IYD(現 DrMOLA) 측에서는 테스트 결과를 올리면서
라는 말을 덧붙였다."어쨌든. 여기서 우리는 비로소 A9 AP간의 편차가 제조사 때문이 아닐 수 있겠단 생각을 해 보게 됐습니다. 그러고 보면 해외 벤치마크 자료 중에도, 삼성의 쓰로틀링 특성이 TSMC보다 나쁘단 결론과 그 반대의 결론이 혼재해 있기도 했습니다. 나아가 실은 그 모든 '제조사간의 편차'로 여겨졌던 것들이, 각 제조사 내부에서도 일상적으로 발생하는 '개체간의 편차'가 아니었을까 하는 가정을 세워볼 수도 있게 됐습니다. 이것을 정확히 검증하려면 샘플을 적어도 100대, 1000대 정도는 확보한 후 일일이 테스트를 해 봐야겠습니다만 그럴 여건이 아니니, 일단은 '이럴 수도 있다'는 가설로만 여겨 주시기 바랍니다."
[ 삼성 파운드리 14nm와 TSMC 16nm의 면적 관련 데이터(클릭시 확대) ]



면적과 밀도(Area) 측면에서는 삼성 14LPE가 TSMC의 16FF 공정보다 더 미세하다. TSMC의 16FF는 자사의 20nm 공정과 동일한 셀 크기를 가진다. 실질적인 공정미세화가 이뤄진 것은 아니지만 FinFET 적용으로 인한 성능, 전력 개선때문에 16nm라는 명칭이 붙은 것으로 보인다. 인텔이 이걸 근거로 자사의 14nm가 진짜 14nm라고 주장하면서 그 14nm를 7년째 우려먹을 예정이다. 그에 비해 삼성의 14LPE는 20LPE보다 유의미한 면적 감소를 이뤄냈다. 수치 상으로 드러나는 CPP는 삼성이 더 미세한 모습을 보여주고 있고, 삼성의 14nm 공정은 TSMC와는 다르게 SDB가 적용되어 있기 때문에 실질적인 밀도 차이는 훨씬 크다. 같은 Apple A9를 생산하는데 삼성제 A9의 면적이 96mm² 이고, TSMC의 A9의 면적이 104mm²이라서 밀도가 그리 크게 차이나지 않는다고 생각할 수도 있겠지만, 우측 상단의 사진에서 볼 수 있는 것처럼 삼성제 A9는 9T 셀, TSMC의 A9는 7.5T 셀을 사용하고 있다는 점을 참고해야 한다.
결론적으로 삼성의 14nm 공정은 9T 셀을 쓰고도 TSMC와 비교하여 면적 측면에서 소폭 우위를 가진다. 는 결론에 도달할 수도 있고, 역으로 삼성의 14nm 공정은 9T 셀을 써야 TSMC 16nm 7.5T 셀과 스피드 게인 측면에서 그나마 비빌 수 있다. 라는 결론에 도달할 수도 있다.
본격적으로 제품화가 이뤄지기 시작한 시기는 삼성의 14LPE가 TSMC의 16FF보다 반 년 빠르다. 삼성의 14LPE는 엑시노스 7420에 최초로 적용됐고, TSMC의 16FF는 삼성의 14LPE와 14LPP와 시기적으로 중간 시점에 등장한 Apple Silicon A9에 최초로 적용됐다.
4. 10 nm[편집]
삼성전자는 10LPE, 10LPP, 10LPU 등으로 구성된 10nm 공정과 해당 공정에서 하프노드 수준의 개선을 이룬 8LPP, 8LPU로 구성된 8nm 공정 라인업을 보유하고 있다. TSMC는 10nm 세대에 CLN10FF(약칭 10FF) 이라는 단 한가지의 공정만 내놓고 최대한 빠르게 ArF 이머젼 쿼드 패터닝 방식을 통한 N7 공정으로 넘어갔다. 인텔의 10nm는 명칭 자체는 10nm긴 하지만 종합적인 면에서 삼성/TSMC의 7nm에 준하는 수준의 공정이다. 인텔이 12세대 엘더 레이크부터 사용할 인텔 10nm Enhanced SuperFin의 이름을 Intel 7으로 명명함에 따라 앞으로는 숫자가 동일해질 전망이다.
[ SPEC 2006 기준 CPU 정수 성능과 FP 연산 능력 및 효율 데이터(클릭시 확대) ]
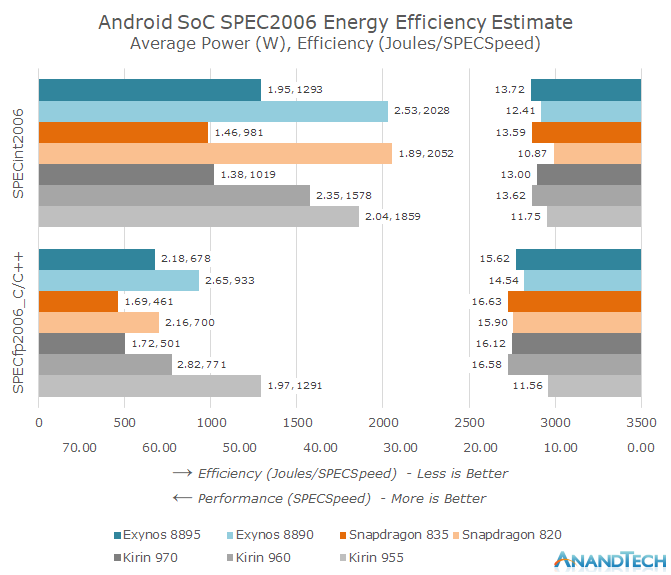
해당 표는 Anandtech에서 측정한 모바일 CPU들의 SPEC 2006 측정 자료이다. 표 좌측의 그래프는 CPU가 소모하는 전력, 그리고 전력에 시간을 곱한 총 소모 에너지 양(J)에 SPEC 2006 테스트 결과 점수를 나눠서 도출된 효율 상수이고, 우측의 그래프는 SPEC 2006을 바탕으로 CPU의 성능을 표기한 자료이다. 최대한 수평적인 비교를 위하여 동일한 Cortex-A73이 동일한 클럭(2.3GHz ~ 2.4GHz)으로 작동할 때의 성능(Perf)과 전력(Power), 그리고 효율 상수(J/SPECSpeed)을 비교해 봐야 한다. 아키텍챠가 동일하지 않다면 비교의 의미가 없고, 스윗 스팟을 넘기면 클럭의 차이에 따라서 효율도 기하급수적으로 변하기 때문이다.
표에서 필요한 데이터를 정리하여 보면 다음과 같다.
클럭이 상승하면 전압도 상승하기 때문에 전력 소모량은 기하급수적으로 상승하게 된다. 따라서 같은 CPU(Cortex-A73)에 비슷한 클럭(2.3~2.4GHz)에서의 전력, 그리고 효율 상수를 비교해 보았을 때, N10 공정과 10LPE 공정은 오차 범위 내 동급의 전력 효율을 보여준다는 사실을 알 수 있다. 두 공정에서 생산된 CPU는 모두 공통적으로 정수 연산, 부동소숫점 연산시 거의 비슷한 양의 전력을 소모한다는 것이 드러났기 때문이다.
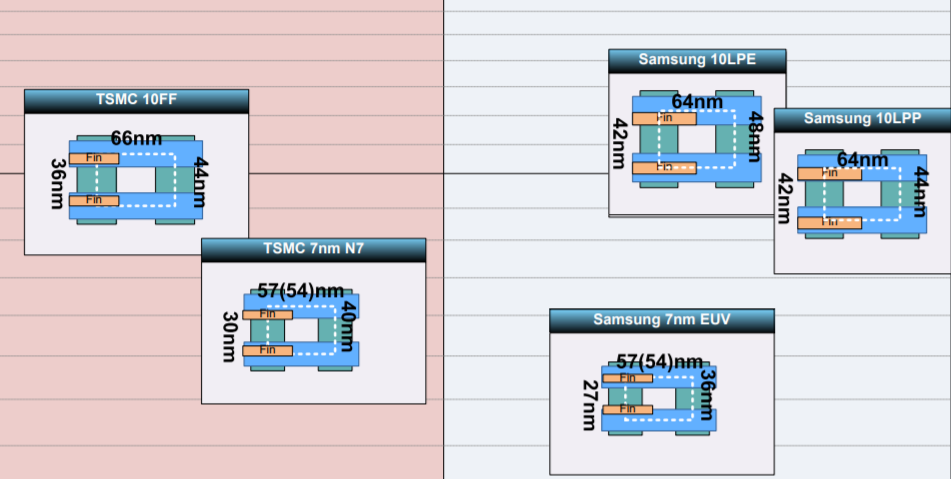
면적 측면에서는 삼성 10LPE보다 TSMC 10FF가 소폭 미세하고, CPP와 M2P를 통해 계산이 이뤄지는 ASML Standard Node 기준으로도 TSMC측의 10FF가 더 미세하다. 그리고, 삼성 10LPP는 10FF보다 소폭 더 미세하다. 그러나 10LPE / 10FF / 10LPP의 트랜지스터 밀도는 유의미한 수준의 차이를 가지지는 않는다.
One thing that I also noticed, is that in very low idle loads where there’s just some light activity on the A55 cores, the Exynos 9820 variant actually uses less power than the Snapdragon unit. The figures we’re talking about here are 20-30mW, but could possibly grow to bigger values at slightly more moderate loads. It’s possible that Qualcomm has more static leakage to deal with on the 7nm process than Samsung on 8nm, one thing that I’ve come to hear about the TSMC 7nm node.
동일한 ARM Cortex-A55로 비교해 본 결과 10nm 공정의 파생 공정인 8LPP는 7FF와 비교했을때 밀도, Full Load 시의 효율 면에서 종합적으로 열세라고 평가되지만, Idle 시의 정적 누설전력이 약 20~30mW 더 낮다는 장점을 가지고 있다.
삼성의 8LPP와 TSMC의 N7 라인업은 이름과는 달리 밀도 차이가 꽤 크지만, N7 라인업 중 N7 HPC 라인업은 8LPP와 밀도 측면에서 비슷한 수준인 것으로 평가되고 있다. 인텔의 10nm 공정 또한 HD 셀에서 HP, UHP 셀로 고성능화가 이뤄지면 이에 따른 Trade-off로 인하여 밀도 측면에서 희생이 이뤄지고, UHP 셀의 경우에는 N7 HPC와 밀도 측면에서 비슷한 수준인 것을 볼 수 있다.
시기 면에서는 본격적으로 10nm 탑재 제품의 상용화가 이뤄진 시기는 삼성 10nm가 반년 더 빠르다. 삼성 10LPE는 2016년 10월에 양산을 시작하여 2017년 4월에 출시된 갤럭시 S8의 삼성 엑시노스 8895 & 퀄컴 스냅드래곤 835를 양산하는데 사용됐고, TSMC의 N10 공정은 2017년 중반기에 출시된 아이패드 프로 2세대의 Apple A10X와 2017년 하반기에 출시된 아이폰 X의 Apple A11을 양산하는데 사용됐다.
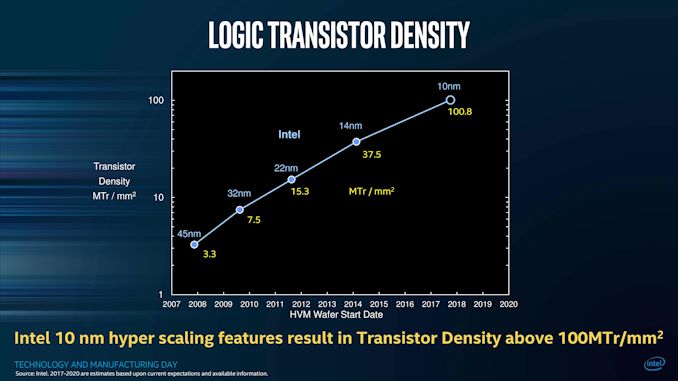


한편 인텔의 10nm 공정은 특이하게도 자사의 이전 세대 공정인 14nm와 비교할 수 있는 데이터가 존재한다. Anandtech 측에서는 14nm 공정에 생산된 카비 레이크 Core i3-8130U와 10nm 공정에서 생산된 캐논 레이크 Core i3-8121U 간의 비교 리뷰를 진행했다. 두 CPU 모두 같은 스카이레이크 아키텍처에 동일한 수준의 TDP, 베이스 클럭을 가지고 있기 때문에 비교할 수 있는 조건이 잘 갖춰진 셈이다.


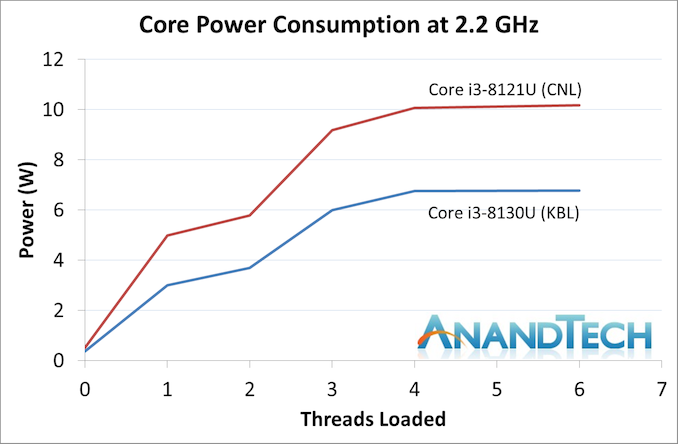
좌측 상단과 우측 상단의 그래프를 보면, 14nm 카비 레이크는 AVX2 테스트 중에 2GHz 후반대의 클럭을 유지했고, 10nm 캐논 레이크는 AVX2 테스트 중에 2GHz 초반대의 클럭을 유지하는 모습을 보여주었다. 물론 클럭 차이만큼 전력 소모도 차이가 있었는데 카비 레이크는 클럭이 유지되는 구간동안 평균 15.0W, 캐논 레이크는 12.6W의 전력을 소모했다. 하지만 카비 레이크 CPU가 전체 테스트를 더 빨리 종결했고, 그로 인하여 카비 레이크 CPU가 소모한 전력이 오히려 더 적다는 계산이 나오게 됐다.
Core i3-8121U (CNL) consumes 867 mWh
Core i3-8130U (KBL) consumes 768 mWh
한편 비교 자료의 아랫 그래프에는 CPU 내의 언코어 부분을 제하고, 두 CPU 모두 2.2GHz 클럭을 유지할 때의 전력 소모가 나왔는데 10nm 공정인 캐논 레이크는 10W를 소모하는데 반해, 14nm 공정인 카비 레이크는 단 7W만 소모한다는 결과가 도출이 됐다. 캐논 레이크를 양산하는데 쓰인 공정이 10nm HD 공정인데도 2.2GHz 구간에 14nm 공정과 비교해서 효율면에서 역전당하는 것을 보면 인텔의 10nm 공정과 소위 말하는 '하이퍼 스케일링' 이라는 전략이 너무 무모했다는 목소리가 나오는 상황.


최근 출시된 Sunny Cove CPU는 인텔 10nm 공정의 고질병을 그래도 어느정도 해소한 것으로 보인다. 아이스 레이크-U/Y는 캐논 레이크가 사용한 10nm 공정에서 밀도를 희생하여 Speed Gain을 얻은 10nm+ 공정이고, 해당 공정과 신 아키텍처를 통하여 AMD가 사용한 TSMC의 7nm HPC 공정과 유사한 전력효율을 가진다는 것을 알 수 있다. 그리고 인텔은 더 이상
시기 면에서는 본격적으로 인텔 10nm 탑재 제품의 상용화가 이뤄진 시기는 2018년 초이다. 그러나 2018년 초에 출시된 캐논 레이크는 단 2개의 코어만 활성화 할 수 있고, 내장 그래픽(IGP)은 아예 비활성화가 되어있고, 성능과 전력소모 측면에서도 도저히 정상적인 수율로 양산됐다고 보기 어려운 하자품이다. 그 이후 타사의 7nm 공정에 비견할 수 있는 아이스 레이크가 최초로 상용화 된 시기는 2019년 하반기이다.
5. 7 nm[편집]
[ SPEC 2006 기준 CPU 정수 성능과 FP 연산 능력 및 효율 데이터(클릭시 확대) ]

TSMC는 자사의 7nm 공정에 세대별로 N7(7FF), N7P(7FFP), N7+(7FF+) 라는 명칭을 부여했고, 삼성의 7nm 공정은 SF7E, SF7이 있다[4].
해당 표는 Anandtech에서 측정한 모바일 CPU들의 SPEC 2006 측정 자료이다. 표 좌측의 그래프는 CPU가 소모하는 전력, 그리고 전력에 시간을 곱한 총 소모 에너지 양을 J 단위로 표기한 자료이고, 우측의 그래프는 CPU의 성능을 표기한 자료이다. 최대한 수평적인 비교를 위하여 동일한 Cortex-A76이 동일한 클럭(2.4GHz ~ 2.6GHz)으로 작동할 때의 성능(Perf)과 전력(Power), 그리고 총 소모 에너지(J)을 비교해 봐야 한다. 테스트를 진행하는 동안 총 소모 에너지의 양은 곧 전력 대비 성능의 역수가 되기 때문에 총 소모 에너지를 통하여 전력 대비 성능을 유추할 수 있다.
표에서 필요한 데이터를 정리하여 보면 다음과 같다.
클럭이 상승하면 전압도 상승하기 때문에 전력 소모량은 기하급수적으로 상승하게 된다. 따라서 같은 CPU(Cortex-A76)에 비슷한 클럭(2GHz 중반대)에서의 전력, 그리고 에너지 소모량을 비교해 보았을 때, N7 공정과 SF7 공정은 오차 범위 내 동급의 전력 효율을 보여준다는 사실을 알 수 있다. 두 공정에서 생산된 CPU는 모두 공통적으로 정수 연산시 9000J 안밖의 에너지를 소모하고 부동소숫점 연산시 5000J의 에너지를 소모하고 있다.
한편 TSMC N7+ 공정에서 양산이 된 기린 990 5G는 정수 연산 테스트에서 7000J, 부동소숫점 테스트에서는 단 4000J을 소모했다. 기린 990 5G 내의 Cortex-A76은 2.86GHz로 작동하면서 N7이나 SF7 공정에 양산된 Cortex-A76이 2.4GHz로 작동할 때와 동일한 전력(정수 연산시 1.5W, 부동소숫점 2.0W대)을 소모한다. 이는 TSMC의 N7이 ArF 이머젼 방식의 쿼드 패터닝 공정을 거치는데에 반해 N7+는 EUV 공정에서 양산됐기 때문이다. 다만 N7+의 양산은 월 2만장 수준으로 한정되어 있는 것으로 보이고, 애플의 독점적 공급에 필요한 양산 수량은 월 6만장~7만장이기 때문에 이는 N7+가 아닌 N7P 공정을 통하여 Apple Silicon A13의 양산이 진행중이다. 한편 삼성의 7nm SF7 또한 'EUV' 공정이다. EUV(극자외선) 노광장비를 가지고 반도체웨이퍼에 설계를 하는 작업. 현재 네덜란드 ASML이 독점 생산하고 광학렌즈는 독일 자이스가 독점하고 있다. 그런데 위의 표를 보면 고클럭에서 N7+보다 10~20% 밀리면서 상당히 약한 모습을 보여주는데, 이는 공정 최적화가 덜 됐기 때문이다. 실제로 공정 최적화 과정을 거쳐서 퀄컴 스냅드래곤 768G가 출시됐고, 이 768G의 CPU 클럭은 2.8GHz 까지 상승했다.

좌측의 사진은 두 회사의 A9 프로세서 간의 차이를 나타내는 그래프이지만 7nm 에서도 동일하게 적용할 수 있다. 우측의 사진은 AP만 다른 동일한 기종의 스마트폰을 비행기 모드로 설정하여 통신칩으로 인한 편차를 제거하고, 화면을 꺼서 디스플레이로 인한 편차를 제거한 상태에서 IDLE 상태의 AP 전력소모를 비교한 결과이다. 이 결과와 위의 표 내의 자료를 참고하면, 2GHz 후반대의 클럭에서는 TSMC의 N7P, N7+가 삼성전자의 SF7 대비 상대적인 우위를 가지고 있다는 사실이 간접적으로 드러났지만, 반대로 1GHz 이하의 저클럭에서는 삼성전저의 SF7가 비교 우위를 점하고 있다는 것을 알 수 있다.


한편 면적(Area) 측면에서는 삼성의 SF7이 퀄컴 스냅드래곤 855를 양산하는데 쓰인 TSMC의 N7보다 약 5% 더 미세하다고 퀄컴 측에서 2020년 VLSI 심포지엄에서 직접 발표한 적이 있다. 그리고 SRAM 셀의 크기는 삼성의 7LPP가 가장 작은데 이 또한 삼성 파운드리에서 양산된 칩이 작은 면적을 가질 수 있는데 일조한다.
반도체 공정간의 밀도 비교 예측자료를 내놓는 Semiwiki 측에서는 삼성의 SF7의 CPP가 54nm가 아닌 57nm라고 예측하여 이로 인하여 TSMC의 7FF가 트랜지스터 밀도 측면에서 SF7를 앞설 것이다 라고 예측을 한 적이 있었지만, 실제 SF7의 밀도는 90 MTr/mm2대가 아닌 101.6 MTr/mm2로 HD 셀 기준 7FF/7FFP 보다는 소폭 높고 7FF+(EUV) 보다는 소폭 낮은 수준이다. SF7의 CPP가 54nm 라는 것은 테크인사이츠의 실측치에도 명백히 드러나 있는 사실이다.
시기적인 측면에서는 TSMC의 7nm 공정이 18년 하반기에 쓰이기 시작한 Apple A12와 19년 상반기에 쓰이기 시작한 855에 적용됐지만, 삼성은 그보다 1년 늦은 19년 하반기의 엑시노스 9825를 양산하는데에 활용됐다.
SMIC는 2022년경에 DUV를 이용한 7nm 공정 개발에 성공하였으며,[5] 2023년 8월에 화웨이가 자체 설계한 기린 9000S를 통해 제품화되었다. 다만 기린 9000S가 거의 대부분 독자 아키텍처를 사용중인 탓에 직접적인 공정의 성능 비교는 어려운 상황이다.
6. 5 nm[편집]
[ 삼성과 TSMC의 5nm 공정 비교 (클릭시 확대) ]


TSMC와 삼성은 명칭은 같은 5nm 공정으로 붙였지만 각 사의 5nm는 판이하게 다른 모습을 보여주고 있다.
삼성의 5nm 공정은 트랜지스터 밀도의 1.33x 향상, 그리고 면적 감소는 25% 이다. 그에 반해 TSMC는 5nm 공정에서 트랜지스터 밀도의 1.8x 향상, 그리고 45%의 면적 감소라는 파격적인 목표를 제시하고 있다. 따라서 삼성의 5nm는 TSMC의 5nm에 비해 면적 & 밀도 측면에서 약 30% 정도 차이가 난다고 볼 수 있고, 삼성의 5nm는 엄밀히 따지면 풀 노드가 아닌 하프 노드라고 볼 수있다. 그러나 진짜 하프노드인 TSMC N6이나 6nm SF6 공정과 비교할 만한 수준이라는 의미는 아니다. CPP와 메탈 피치, 그리고 ASML Standard Node 기준으로 삼성의 7nm와 5nm는 서로 동일하지만, 25% 면적 감소를 위해 SDB 적용, 트랙 수를 5T로 줄이고, EUV 적용 레이어 수를 훨씬 늘리는 등의 다른 기술들이 적용됐기 때문이다. TSMC도 20nm에서 16nm로 넘어갈 때 ASML Standard Node 기준으로는 두 공정이 서로 동일한 공정이었으나, 소자 측면에서 FinFET을 적용하고, 이를 통하여 소비전력을 획기적으로 낮춘 사례와 일치한다. 하프 노드긴 하지만 풀 노드에 준하는 개선이 이뤄진 공정이라고 판단해도 좋다.
삼성은 이러한 격차를 줄이기 위해 SF5E의 후속 공정인 SF5[6]와 SF4E[7], SF4[8]를 준비하고 있고,
양산 시기 면에서는, TSMC의 5nm 공정은 첫 제품이 Apple Silicon A14칩이기 때문에 2020년 하반기부터 실제 제품이 출하가 됐고, 삼성의 5nm 공정은 첫 제품이 엑시노스 1080이기 때문에 역시 동일한 2020년 하반기부터 실제 제품이 출하가 됐다. 물론 같은 2020년 하반기지만 실제 공개 및 출하 시점에서 삼성의 5nm 공정은 약 2개월 뒤쳐졌다. 물론 이는 고객사의 제품 출시 일정에 따라 달라진 것이기 때문에 본질적으로는 같은 시기라고 보는 것이 맞다.
[ SPEC 2006 기준 CPU 정수 성능과 FP 연산 능력 및 효율 데이터(클릭시 확대) ]

해당 표는 Anandtech에서 측정한 모바일 CPU들의 SPEC 2006 측정 자료이다. 표 좌측의 그래프는 CPU가 소모하는 전력, 그리고 전력에 시간을 곱한 총 소모 에너지 양을 J 단위로 표기한 자료이고, 우측의 그래프는 CPU의 성능을 표기한 자료이다. 최대한 수평적인 비교를 위하여 동일한 Cortex-A77이 동일한 클럭(3.1GHz)으로 작동할 때의 성능(Perf)과 전력(Power), 그리고 총 소모 에너지(J)을 비교해 봐야 한다. 테스트를 진행하는 동안 총 소모 에너지의 양은 곧 전력 대비 성능의 역수가 되기 때문에 총 소모 에너지를 통하여 전력 대비 성능을 유추할 수 있다.
표에서 필요한 데이터를 정리하여 보면 다음과 같다.
동일한 조건 하에서 TSMC N7P와 TSMC N5는 동일 성능, 동일 아키텍처, 동일 클럭 하에서 N5가 N7P와 비교시 평균적으로 전력 소모량이 12% 더 낮았다. 이는 TSMC가 공개한 수치와는 차이가 좀 있지만, 원래 보통 삼성이나 TSMC와 같은 기업들이 발표하는 Perf/Power/Area 에 대한 정보는 최적의 구간 기준 이라는 점을 항상 명심해야 한다.
[ SPEC 2006 기준 Cortex-A55 @ 1.80 GHz 구동시 전력소모(클릭시 확대) ]

해당 표는 Anandtech에서 측정한 모바일 CPU의 SPEC 2006 전력 측정 자료이다. 최대한 수평적인 비교를 위하여 동일한 Cortex-A55가 동일한 클럭(1.80 GHz)으로 작동할 때의 전력(Power)을 비교해 봐야 한다. 보통 Cortex-A53이나 Cortex-A55는 공정 자체의 PPA를 검증하는데 자주 사용되기 때문에 본 테스트를 통하여 공정 자체의 전력 대비 성능을 유추할 수 있다.
표에서 필요한 데이터를 정리하여 보면 다음과 같다.
한편 TSMC N7P와 삼성 SF5E는 동일 성능, 동일 아키텍처, 동일 클럭 하에서 비교시 SF5E가 Power 측면에서 1~2% 앞서는 수준으로 사실상 오차범위 내에서 동급이었던 것으로 판단이 된다. SF7 = N7 < SF5E = N7P < N5 라는 공식이 성립하는 것이다. 물론 삼성의 5nm 공정이 TSMC의 그것보다 기술적으로 10% 더 낮은 수준인 것은 사실이지만, 일부 중화권 미디어에서는 삼성의 SF5E가 TSMC의 N7P보다도 훨씬 낮은 수준의 효율을 가진다고 호도하는 경우도 많은데 이 또한 그대로 수용해서는 안된다. 중화권 사이트의 측정 자료는 대부분 실측 자료가 아니라 어플리케이션으로 예측한 자료이기 때문에 전력소모 측정 면에서 정확하다고 할 수 없기 때문이다. 본 문서에서 Anandtech 사이트의 측정 자료만 올리는 것도 그 때문이다.
2021년 1월 TSMC 7나노 공정으로 생산된 스냅드래곤 870이 발표됐는데, 삼성의 SF5E 공정에서 생산된 퀄컴의 플래그쉽 AP인 스냅드래곤 888칩셋의 발열문제로 인해, 올해는 해당 라인업이 이목을 끌었다. 다만 일각에서 나오는 삼성 SF5E에서 생산된 888의 발열 문제 때문에 N7P에서 생산됐다는 식의 주장은 어폐가 있으므로 걸러들어야 할 필요가 있다. 비교적 덜 알려져서 그런 것이지, 스냅드래곤의 8(X+1)0 라인은 8X5, 8X5+의 리비젼격 AP로 항상 존재해왔던 준플래그쉽 라인업이다. 애초에 스냅드래곤 870은 패스트커넥트 6900이 6800으로 다운그레이드 된 점을 제외하면 클럭 빼고는 차이가 없는 물리적으로 완전히 동일한 프로세서이며, 따라서 원래 TSMC의 N7P로 설계된 칩을 굳이 삼성 파운드리의 공정으로 바꿔야 할 이유가 존재하지 않는다. 스냅드래곤 860의 경우도 마찬가지로, 855를 기반으로 오버클럭이 된 물리적으로 완전히 동일한 프로세서이기 때문에 N7 공정에서 생산되는 것이다. 그런데 이를 두고 860이 N7에서 생산된다고 N7P의 공정에 문제가 있다는 주장은 어불성설이다.
7. 4 nm[편집]
2022년 삼성 갤럭시 GOS 성능 조작 사건이 알려지고 삼성 파운드리의 4nm 실제 수율이 밝혀졌다. 삼성 파운드리는 30%대의 매우 낮은 수율을 보였으며, 이 사실은여러 기사를 통해 일반인들에게도 널리 알려지게 되었다. 단순 공정 비교만으로는 성능 비교가 불가능한 상태가 되어 사실상 TSMC의 4nm가 삼성 파운드리의 4nm를 압도적으로 눌렀다. 삼성전자는 2023년경에 들어서 4nm 공정 정상화를 이루긴 했으나,[9] 이미 신뢰를 한번 잃은 상태이고 시장이 3nm로 넘어갈 준비를 하고 있는 시점인지라 4nm에서의 추가적인 대규모 수주는 결국 받지 못했다.
한편 인텔은 기존에는 7nm라고 하던 공정을 Intel 4라는 이름으로 변경했고 공식적으로 2022년 생산 준비를 마치고 2023년부터 제품을 출하할 계획이라고 한다. Intel 4는 계획에 따르면 약 200 MTr/mm2에 달하는 트랜지스터 밀도를 가질 것이라고 한다. 하지만 인텔4의 대규모 양산은 모두 목표시기를 놓쳤고, 수율마저도 예상한 것 만큼 나오지 않아 Intel 4로 양산 예정이었던 모바일 고전력/데스크탑용 메테오레이크는 취소,[10] 모바일 중저전력용 메테오레이크의 CPU 타일만 생산하게 되었다.
8. 3 nm[편집]
[ 삼성과 TSMC의 3nm 공정 비교 (클릭시 확대) ]




TSMC와 삼성이 5nm 공정에서 걷는 길이 달랐고, 3nm 공정에서도 역시 서로 다른 길을 걸을 것으로 보여진다.
면적과 밀도 측면에서 양 사에서 언론에 공개한 내용에 따르면 삼성의 3nm 공정은 2019년에는 SF7와 비교해서 45%의 면적 감소가 이뤄진다고 했으나 그 이후 2020년에 보도된 자료에 따르면, SF5E와 비교하여 면적이 35% 감소한다. 당연히 이쪽이 훨씬 더 미세하다. 이로 미루어 봤을때 밀도는 약 1.5배 증가할 것이다.
그리고 TSMC의 3nm 공정은 소자 측면에서 FinFET을 그대로 유지하면서 2nm 세대부터 GAAFET을 도입할 것이지만 삼성은 3nm SF3E/SF3에서 조기에 GAAFET(MBCFET)을 적용할 것이다. 다만 GAAFET 소자의 조기 도입이 과연 득이 될지 EUV 조기 도입때처럼 독이 될지는 좀 더 지켜봐야 알 수 있는 일이다.
최근 자료에서는 TSMC N3의 밀도 향상치가 더욱 공격적으로 제시되어 있다. TSMC 공식 소개 페이지#에서는 N3이 N5 대비 밀도 최대 70% 증가, 속도 최대 15% 증가, 전력 최대 30% 감소될 수 있다고 기재되어 있다. TSMC의 N3이 N5에 이어 또 한번 1.7배 수준의 밀도 향상을 이뤄낸다면 GAAFET을 포기하는 대신 1세대에 준하는 수준의 밀도 차이가 날 것이다. 정황상으로는 최근 자료가 더욱 타당한 것으로 보인다.
2022년 삼성전자가 6월당시 양산을 시작, 수율을 올리고 있을때 TSMC가 8월 당시 80% 이상의 수율을 보여준다던 발표[11]와는 상반되게 3분기 양산에 실패, 양산시기를 4분기 후반으로 미루며 삼성전자에게는 경쟁력을 높일 기회가 주어졌다.
Apple A17 Pro가 등장하며 TSMC 3nm 공정이 그 모습을 드러내었는데, N3B에서 생산된 A17 Pro의 트렌지스터 밀도는 약 183MTr/mm2으로, N5에서 생산된 M1의 133MTr/mm2 대비 1.37배의 밀도증가폭이다. N5 당시 목표치인 트랜지스터 밀도의 1.8x 향상이 거의 그대로[12] 총면적 감소로 이어진 것을 생각하면 N3B는 애시당초 설정한 밀도 목표치를 달성하지 못했을 가능성이 있다. N3B 공정은 수율 문제로 인해 애플의 A17 Pro, M3 시리즈에서만 활용되는 원오프상의 성격을 가진 것으로 보이며, 타 회사에 제공하기 위해 N3E에서 밀도를 잠시 낮추고 N3B 대비 성능과 전력효율을 높이다가[13] N3P[14]에서 N3B의 밀도를 다시 회복할 예정이다. 특히 3nm 공정 중 고성능 고전력 특화 공정인 N3X는 누설전류가 폭증하여 FinFET으로 강행된 3nm의 한계를 여실히 보여주는 등 TSMC 3nm는 완전히 실패해버린 모양세가 되었다.
한편 Intel 3는 2023년 하반기 제품 출하를 목표로 하였으나, 1년가량 지연된 것으로 보인다.
9. 2 nm[편집]
TSMC도 자사의 N2 공정에는 GAAFET 소자를 적용할 예정이라 밝혔으며, 인텔 또한 Intel 20A부터 RibbonFET을 적용하기로 하며 세 파운드리 사 모두 2 nm 공정에 들어서 이름은 서로 다르지만 형태는 거의 유사한 Gate-all-around FET을 적용하게 됐다.
IBM과 삼성, 글로벌 파운드리는 공통 플랫폼 연합(Common Platform Alliance)에 속하는 회사다. 2021년 5월 7일에 올라온 기사에 따르면 IBM은 2 nm 칩을 세계 최초로 개발했고, IBM은 팹리스 회사이기 때문에 삼성 파운드리가 생산을 맡았다고 한다. Wikichip에 따르면 이 2 nm 공정의 트랜지스터 밀도는 333.33 MTr/mm^2 이며 이는 TSMC의 3 nm 공정보다는 더 미세하지만 TSMC의 2 nm 공정과 비교시 밀도 측면에서는 열세일 것으로 전망이 된다. Speed Gain 측면에서는 기존의 7 nm와 비교시 45% 높고 전력소모는 1/4 수준을 달성했다고 한다.
현재 각 파운드리 사의 양산 일정은 인텔이 2024년 양산 및 제품 출하를 계획하고 있어 가장 빠르고, TSMC는 2024년 하반기에 리스크 생산에 들어가고 2025년 하반기 대량 양산을 목표로 하고 있으며, 삼성 또한 2025년 대량 양산에 들어가서 2026년 제품 출하를 목표로 하고 있다. 인텔 TSMC 삼성
x.x nm로 표기하는 TSMC/삼성 파운드리와는 다르게 인텔은 2nm 부터는 이를 옹스트롬(Å) 수준의 공정이라는 의미로 이를 Intel 20Å, Intel 18Å로 명명하였다.
10. 결론[편집]
삼성은 그동안 HKMG, 20nm, 14nm, 10nm, EUV의 적용에 있어서 항상 선두를 유지했다. 그런데 레거시 공정을 제외한 선단공정 내에서의 점유율 측면에서 지속적으로 삼성이 치고 올라오는 걸 묵과할 수가 없었던 TSMC가 7nm 세대부터 천문학적인 돈을 때려 부으면서 공격적인 R&D 전략과 CAPA
(생산능력) 확충에 나서기 시작했다.
그로 인하여 TSMC는 결국 공정미세화 기술력 측면에서 삼성전자를 상대로 역전해내는데 성공해낸다. 7nm 세대에서 공정 기술력, 초도 양산 시기, CAPA 및 고객사 유치와 공정 외적인 패키징 기술 같은 면에서 모두 우위를 점하는 데 성공한다. 삼성전자의 파운드리 사업부는 알짜 고객들의 물량을 많이 놓치면서 꽤나 고전하는 모습을 보여주고 있지만, 그래도 양 사 간의 기술 격차가 0.5세대 이상으로까지 확대하도록 놔두지는 않는 중이다. 지금도 한국 1위 기업과 대만 1위 기업은 그동안 쌓아 놓은 자금력을 바탕으로 파운드리 시장에서 매년 수십조 원의 규모에 다다르는 투자를 집행하는 중이다.
2014년 기준 TSMC가 파운드리 업계의 단독 선두를 달리고 있지만 선단공정 분야에 삼성 파운드리가 다시 도전하고 있기 때문에, 과거 40nm, 혹은 그 이전 세대 때 "이게 다 TSMC 때문이다." 라는 말이 나올 정도로 자사가 설정한 로드맵을 뒤엎고 양산 일정이 순연되면서 수율 불량이 밥 먹듯 튀어나오는 사태는 이젠 볼 수 없게 됐다. 즉 다시 말해서 "이게 다 TSMC 때문이다." 라는 말은 역사 속으로 사라진 셈이다.
2019년 기준 최신 공정에서 이제는 수율 문제 대신 CAPA 문제로 엔비디아나 퀄컴, IBM 같은 기업들이 삼성 파운드리로 넘어가는 상황이다. TSMC가 칩을 찍어주기를 기다려야 했던 상황에 비하면 낫기는 하나, 현재 삼성의 8nm이 TSMC의 N7보다 명백하게 뒤처지는 공정임을 생각하면, CAPA 면에서 아직도 "이게 다 TSMC 때문이다는 유효하다고 볼수 있다." 특히 AMD 같은 경우 리사 수가 공개적으로 인정한 것처럼 TSMC의 7nm 생산량이 매우 타이트한 상황으로, TSMC가 배정된 CAPA를 수익율이 더 높은 서버칩 등에 몰아주고 있어서 고질적인 생산량 부족은 현재 2020년까지도 지속되고 있다. 삼성은 TSMC가 못 먹고 흘린것만 주워먹기만 해도 대성공인데, 과거 글로벌 파운드리는 최신공정에서 AMD하고 맺은 납품계약만 아니였다면 주워먹기도 힘들어했기 때문이다.
5nm 세대에서는 CAPA 부족이 더욱 심화되는 상황이다. 퀄컴도 TSMC의 5nm의 잠재적인 수요자였으나, 애플이 5nm CAPA를 독점하여 스냅드래곤 888을 삼성 파운드리에게 주문을 넣어야 했다. TSMC는 7nm/7nm EUV에서는 위에 언급한대로 CAPA 부족으로 엔비디아를 놓아줘야 했지만, 그래도 혼자서 애플의 주문을 다 소화하고 퀼컴/하이실리콘/미디어텍/AMD와 같은 2티어 팹리스들의 물량도 어느정도 소화할 수 있었다. 즉, 5nm 최신공정에서 CAPA가 7nm 때보다 더 낮아진 것인데, 이는 TSMC의 5nm 웨이퍼 불량율은 낮으나 5nm의 웨이퍼당 기대한 성능의 칩에 대한 수율은 전체적으로 7nm에 비해서 좋지 못 함을 알수가 있다.
5nm 이후 TSMC의 전략을 보면 TSMC는 7 - 5 - 3 으로의 발전 과정에서 80%, 15%로 초반 5nm에서의 파격적인 변화를 노리는 중이고, 삼성은 7 - 5 - 3 으로의 발전 과정을 거치는 동안 밀도를 각각 33%, 50% 증가시키면서 상당히 완만한 단계의 개선폭을 이루려고 했다. 하지만 기술력의 한계 때문인지 둘 다 바로 3nm로 가지는 못했고 4nm를 거쳤다. 그리고 이 과정에서 결국 삼성 파운드리의 4nm의 실제 수율은 30% 대로 확인되었으며 5nm 양산 당시에도 수율이 매우 낮았던 것으로 밝혀졌다. 이를 통해 TSMC의 단독 선두는 굳혀졌으며, 선단공정에서는 높은 수율이 여전히 매우 중요함을 알 수 있다. TSMC는 삼성 파운드리를 쓰려 했던 대형 팹리스사들의 물량까지 소화를 해야 해서 어쩔 수 없이 부족한 CAPA 문제를 겪게 됐다.
선단공정 기술력과 더불어 CAPA, 그리고 빅칩 양산에 도움을 줄 수 있는 CoWoS와 같은 패키징 기술력도 마찬가지로 TSMC가 여전히 앞서는 상황이다. 세계 5대 반도체 패키징 회사들 중 4개가 대만회사다. 2위가 미국회사인데, 옛날 아남전자인 Amkor technology다. 창업주의 아들이 미국으로 이민가서 본사도 이제 미국 애리조나에 있다. 그러나 삼성전자도 퀄컴 센트릭 2400, 엔비디아 GA102, IBM POWER10, 엔비디아 Orin 등을 양산하면서 빅칩 양산에 서서히 도전하는 중이며, 삼성전자는 자사 EUV 공정에 적용하기 위한 EUV용 펠리클 기술을 연구하는 중이다.
한편 인텔은 TSMC와 삼성전자 파운드리 사업부는 각자 기술 발전을 가속시키고 있는 상황에서 이를 전혀 따라가지 못하는 상황이다. 인텔은 2013년 불도저의 실패로 인한 AMD의 부진을 'CPU 경쟁은 이제 끝났다'는 오판으로 기술개발에 소홀히하여 결국 기술 우위를 놓치고 말았다. TSMC와 삼성전자의 5나노 공정이 2020년 하반기부터 본격적인 제품 출하가 시작하는 상황에서, 그와 동급인 인텔의 7nm는 2023년까지 예정이 없었다. 그렇게 팹의 기술력 측면에서 최대 3년 격차가 벌어질 수도 있다는 암울한 전망이 현실이 되고야 말았다.
그런데 팻 겔싱어가 CEO로 취임한 이후 2021년 7월 새로운 계획을 발표한다. 공정의 이름을 변경함과 동시에 2025년까지 미세공정의 선두를 다시 되찾겠다고 선언했다. Intel 7(기존 10ESF)은 2021년 하반기에 제품 출하를 시작하고, Intel 4를 2023년 상반기 출하, Intel 3를 2023년 하반기 출하, Intel 20A와 18A를 각각 2024년, 2025년에 생산 준비를 마칠 것이라고 한다. Intel 3와 Intel 20A에 해당하는
11. 참고문서[편집]

 이 문서의 내용 중 전체 또는 일부는 2023-12-13 19:55:25에 나무위키 파운드리간 기술력 비교 문서에서 가져왔습니다.
이 문서의 내용 중 전체 또는 일부는 2023-12-13 19:55:25에 나무위키 파운드리간 기술력 비교 문서에서 가져왔습니다.