이 문서는 r20240101판에서 저장되지 않은 문서입니다.
자동으로 r20190312판 문서를 읽어왔습니다.
자동으로 r20190312판 문서를 읽어왔습니다.
NVIDIA GPU 일람
덤프버전 : r20190312

1. GPU 요약 일람
3. 데스크톱용 GPU 일람
3.1. NV4 이전 아키텍처
3.2. NV4(Fahrenheit) 아키텍처
3.3. NV10(Celsius) 아키텍처
3.4. NV20(Kelvin) 아키텍처
3.5. NV30(Rankine) 아키텍처
3.6. NV40(Curie) 아키텍처
3.7. Tesla 아키텍처
3.8. Fermi 아키텍처
3.9. Kepler 아키텍처
3.10. Maxwell 아키텍처
3.11. Pascal 아키텍처
3.12. Volta 아키텍처
3.13. Turing 아키텍쳐
3.14. 차세대 아키텍처
4. 관련 문서
NVIDIA의 GPU 목록. 칩셋의 역사도 함께 설명한다.
1. GPU 요약 일람[편집]
후술하겠지만 엔비디아의 네이밍 법칙 자체는 매우 쉬운 편이다. 하지만, 일부 제품은 리네이밍을 해서 마치 이후 세대 그래픽카드처럼 포장 되어 있는 경우가 있기 때문에 잘 알아봐야 한다. 특히 지포스 8, 9, 200 시리즈는 리네이밍 제품이 상당히 광범위하게 섞여 있고, 이후 세대 그래픽카드에도 로우엔드의 경우에는 이전 세대 리네이밍이 간혹 섞여 있기 때문에 중고 제품을 구입할 때 주의가 필요하다. 지포스 100 시리즈와 300 시리즈는 각각 9 시리즈와 200 시리즈의 OEM용 리네이밍 버전이다. 따라서 시중에는 발매되지 않았으며, 이게 중고로 돌아다닌다면 십중팔구 대기업 완제품 PC에서 떼낸 것들. 옥션이나 G마켓 등의 오픈마켓에서 올라오는 중고 그래픽카드 중 "제조사 랜덤"이 있는 경우에는 주의를 요한다. 리마킹 제품을 받게 되는 경우가 있다.
각 제품군에 따라 문서가 존재하니 자세한 정보는 해당 문서 참조.
2. 네이밍 구분 방법[3][편집]
2.1. 데스크탑용[편집]
위에 서술했듯 매우 간단하다. 하지만 일반적으로 숫자가 높을 수록 좋은 칩셋이지만, 그래픽카드라는게 공정이나 아키텍처를 비롯한 다양한 속성이 섞여있는 만큼 단순한 존재가 아니기 때문에, 일부 칩셋들은 네이밍답지 않는 결과를 보여주거나 같은 네이밍이라도 그 내부는 둘 이상의 제각각인 경우도 있으므로 네이밍 하나만 보고 속단하지 않는 것이 좋다. 또한 아무리 네이밍상 좋다고 하여도 가성비는 전혀 네이밍과 상관이 없기에 경거망동한 판단은 금물이다. 그리고 간혹 가다가 예외인 경우도 있으니 주의할것.
2.1.1. 1997~2001년[편집]
RIVA 또는 GeForce (브랜드명) (파생형 문자)
ex) RIVA TNT2 M64, GeForce 2 Ti
시리즈 브랜드명 뒤에 영문자가 덧붙이는 형식이지만 영문자만 보고 어느 모델이 상위인지 하위인지 구별하기가 상대적으로 어렵다. Ultra가 그나마 상위 모델이라는 이미지가 쉽게 떠오르지만 나머지는 스펙을 직접 확인하지 않는 한, 쉽게 떠오르지 않기 때문. 지포스 2 시리즈의 상위 모델까지 사용되었다.
2.1.2. 2001~2003년[편집]
GeForce (상위 브랜드명) (하위 브랜드명) (파생형 숫자)
ex) GeForce 2 MX 400, GeForce 4 Ti 4800
지포스 2 시리즈 하위 모델만 적용된 형식었다가 지포스 3 시리즈부터
백의 자리 숫자는 등급용으로, 천의 자리 숫자는 세대 구분용으로 통용된다.
2.1.3. 2003~2004년[편집]
GeForce (브랜드명) (네 자리 숫자) (파생형 문자)
ex) GeForce FX 5900 Ultra
통상적으로는 지포스 FX 시리즈이지만, PCIe x16 슬롯형 제품군까지 포함하면 지포스 PCX 시리즈까지 해당된다. 네 자리 숫자는 지포스 4 시리즈 상위 모델과 같은 형식을 지니며 첫째 자리 숫자는 세대 구분용, 둘째 자리 숫자는 등급용, 파생형 문자는 세부 등급용을 의미한다.
2.1.4. 2004~2009년[편집]
GeForce (네 자리 숫자) (파생형 문자)
ex) GeForce 6600GT, GeForce 9800GTX
9800GTX를 예시로 하자면 천의자리 9는 몇번째 세대인지 의미하는데 높을수록 신형이다. 8은 성능을 의미하며 높을수록 성능이 좋으나 부작용이 따르는 경우도 간혹 있다. GTX는 지포스 6 시리즈부터 정립된 등급 명칭으로 G<GS<GT<GTS<GTX<GTX+<Ultra 순으로 좋다.
2.1.5. 2008년~현재[편집]
GeForce (브랜드명) (3~4자리 숫자) (파생형 문자)
ex) GeForce GT 240, GeForce GTX 560Ti
지포스 200 시리즈 이후의 네이밍 구분 방법은 더더욱 쉬워졌다.[4] GTX 980Ti를 예로 든다면, 첫 자리의 9는 세대수를 의미하며, 높을 수록 신형이다. 8은 성능을 의미한다. 높을수록 성능이 좋다. Ti는 붙을 수도, 붙지 않을 수도 있는데 붙으면 성능이 좀 더 좋다. 그리고 GTX는 등급[5]으로,
2.2. 모바일용[편집]
2.2.1. 2000~2006년[편집]
모델명에 "Go"가 붙어있는 형태였으나 시리즈마다 "Go"가 붙어있는 위치가 변동되었다.
2.2.2. 2007~2016년[편집]
숫자 맨 끝에 "M"이 붙어있는 모델은 Mobile의 이니셜을 가리키는 모바일(주로 노트북)용 모델이다. "M"이 붙은 모델은 그저 노트북 같은 모바일 기기에 맞게 설계된 모델일 뿐 구성 자체는 데스크톱에 들어가는 GPU와 같다. 다만 전력 문제 등으로 인해 동일한 이름의 데스크톱 모델보다 한 단계 낮은 성능의 GPU, 혹은 클럭 등을 낮춰서 탑재한다. 올인원 PC용 그래픽은 M 대신 All-In-One의 머릿 문자를 따온 "A"가 붙어있다.
2.2.3. 2015년~현재[편집]
2015년 9월에 출시된 GTX 980 노트북과 지포스 10 시리즈 이후의 노트북들은 데스크탑 그래픽카드와 성능 차이가 많이 없어져서 M이 들어가지 않는다. 하지만 어느 정도 성능 격차가 있기 때문에 비공식으로는 이를 구분하기 위해 Mobile이라고 덧붙이면서 구분한다.
3. 데스크톱용 GPU 일람[편집]
OEM 전용 칩셋에는 *를 표시하거나 출시가에 -를 표시한다.
3.1. NV4 이전 아키텍처[편집]
3.1.1. NV1[편집]
3.1.2. NV2[편집]
원래 NVIDIA의 2번째 그래픽카드가 될 예정이었으나 세상에 빛을 보지 못한 물건. 세가 새턴 후속기에 장착될 예정이었지만 하위호환 기능이 제거되면서 드림캐스트에는 PowerVR 칩이 들어가게 되었다.
3.1.3. RIVA 128[편집]
3.2. NV4(Fahrenheit) 아키텍처[편집]
3.2.1. RIVA TNT[편집]
3.2.2. RIVA TNT2[편집]
3.3. NV10(Celsius) 아키텍처[편집]
GeForce라는 브랜드의 기원이 된 아키텍처의 시작이자 최초의 지포스 제품군이 시작되는 아키텍처.
3.3.1. GeForce 256[편집]
3.3.2. GeForce 2[편집]
3.4. NV20(Kelvin) 아키텍처[편집]
3.4.1. GeForce 3[편집]
3.4.2. GeForce 4[편집]
3.5. NV30(Rankine) 아키텍처[편집]
여러가지 의미로 NVIDIA 첫번째 삽질의 전설로 남은 기념비적인 아키텍처... 얼마가지 않아 공정이 바뀌었다.
2008년 5월 13일에 v175 버전을 마지막으로 드라이버 공식 지원이 중단되었다. (단, Windows XP 호환 드라이버) DirectX 9.0과 쉐이더 모델 2.0을 지원하여 WDDM에 대응된 가장 오래된 시리즈이지만, 정작 Windows Vista 호환 드라이버는 2006년 10월 17일에 ForceWare v95 버전에서 한 번 지원해준 이후로 지원이 끊겼다(...).
3.5.1. GeForce FX[편집]
3.6. NV40(Curie) 아키텍처[편집]
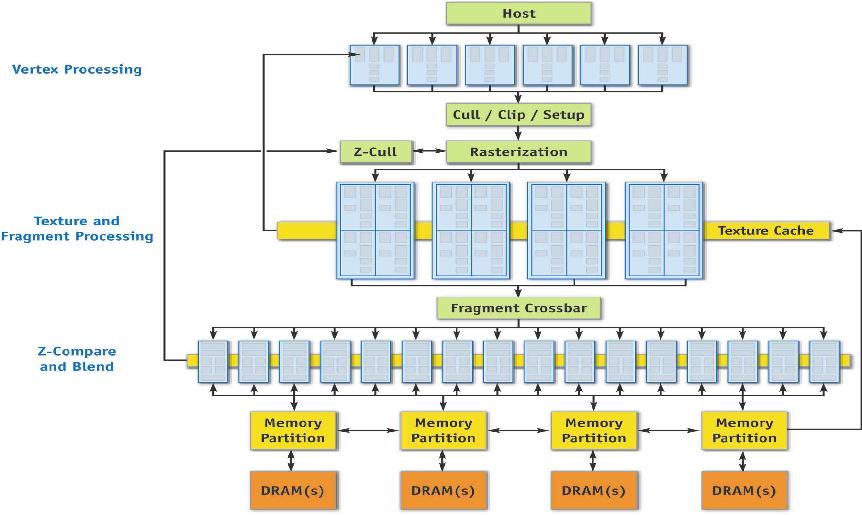
지포스 6800에 사용된 NV40 GPU의 블록 다이어그램.
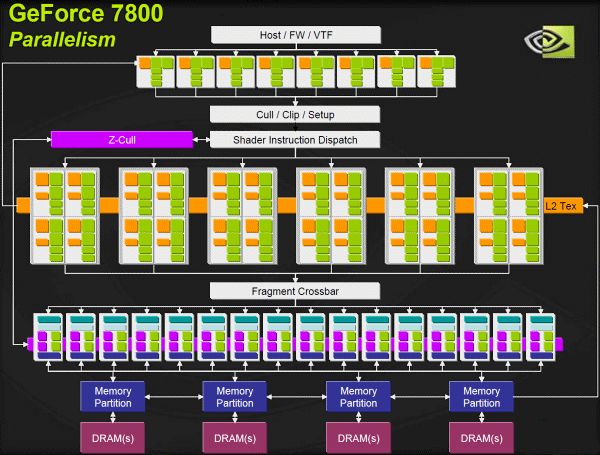
지포스 7800 GTX에 사용된 G70 GPU의 블록 다이어그램.
2015년 2월 24일에 v309.08 버전을 마지막으로 NV40 아키텍처 기반 모든 모델들의 드라이버 공식 지원이 중단되었다.
3.6.1. GeForce 6[편집]
3.6.2. GeForce 7[편집]
3.7. Tesla 아키텍처[편집]
 Tesla 제품군에 대한 내용은 NVIDIA Workstation GPU 일람 문서의 4번째 문단을 참조하십시오.
Tesla 제품군에 대한 내용은 NVIDIA Workstation GPU 일람 문서의 4번째 문단을 참조하십시오. 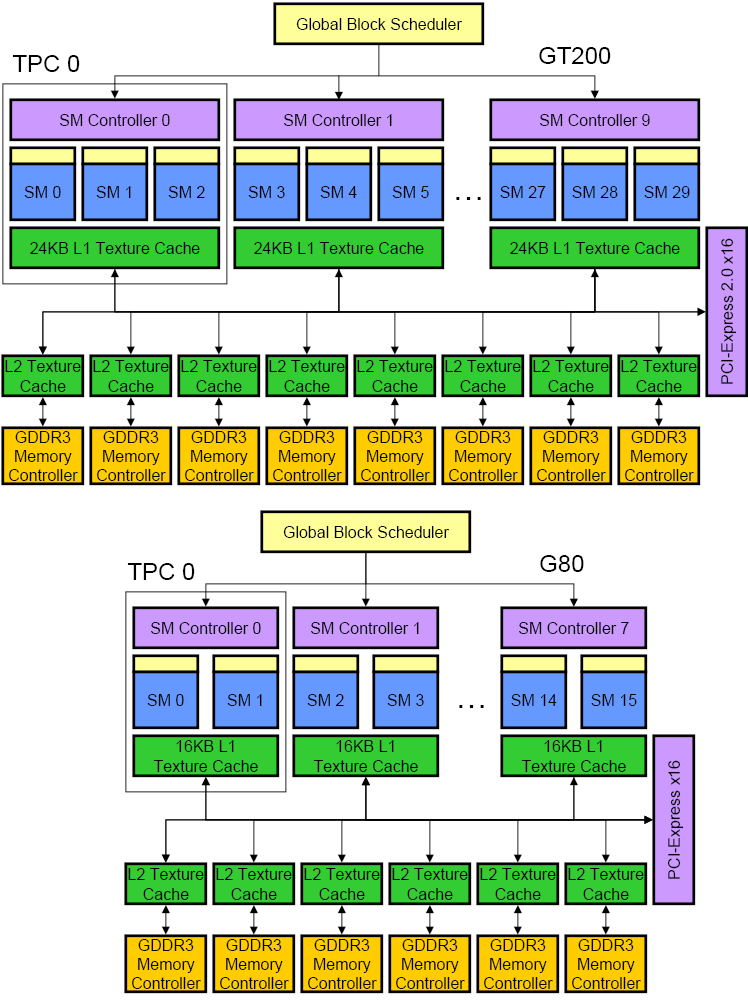
G80과 G200 GPU의 블록 다이어그램 비교.
- 머릿글자 설명
- GPC : Graphics Processing Cluster
- TPC : Texture/Processor Cluster
- SM : Stream Multiprocessor
- SMX : Stream Multiprocessor eXtreme
- SMM : Stream Maxwell Multiprocessor
- SP : Stream Processor[10]
- SFU : Special Funtion Unit (특수 연산 유닛)
- DPU : Double Precision Unit (배정밀도 유닛)
- G80 칩셋의 구성
- TPC 1개당 SM 2개씩 구성.
- SM 1개당 SP 8개씩, SFU 2개씩 구성.
- SP 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op[11]/cycle.
- SFU는 SP의 1/4로 구성되며, 한 사이클당 네 번의 곱셈을 수행하므로 4op/cycle.
- G80 칩셋의 부동소수점 연산 성능 계산
- 단정밀도 연산 : {SP 개수 x 2op/cycle + SFU 개수 x 4op/cycle} x 셰이더 클럭[12]
- 배정밀도 연산 : 미지원.
- G200 칩셋의 구성
- TPC 1개당 SM 3개씩 구성.
- SM 1개당 SP 8개씩, SFU 2개씩, DPU 1개씩 구성.
- SP 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- SFU 한 사이클당 네 번의 곱셈을 수행하므로 4op/cycle.
- DPU 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- G200 칩셋의 부동소수점 연산 성능 계산
- 단정밀도 연산 : {SP 개수 x 2op/cycle + SFU 개수 x 4op/cycle} x 셰이더 클럭
- 배정밀도 연산 : DPU 개수 x 2op/cycle x 셰이더 클럭 (또는 단정밀도 연산 / 8)
여기서부터 아키텍처명에 과학자의 이름을 붙이며, 이전 아키텍처도 소급 적용하게 되었다.
2016년 12월 14일에 v342.01 버전을 마지막으로 테슬라 아키텍처 기반 모든 모델들의 드라이버 공식 지원이 중단되었다.
3.7.1. GeForce 8[편집]
3.7.2. GeForce 9[편집]
3.7.3. GeForce 100[편집]
[3] 일반 가정용/게이밍용 제품군 기준.[4] 지포스 100 시리즈도 존재하지만 200 시리즈보다 나중에 등장한 제품군인데다 데스크탑용 그래픽카드가 전부 OEM용이다.[5] 이전 네이밍 방식의 등급과 약간 다른 기준이지만 근본적인 의미에는 큰 차이가 없다.[6] 100 시리즈에서만 제대로 사용되었고, 200~300 시리즈에서는 공식적으로 사라졌지만 G가 사용된 모델과 없는 모델이 혼재되는 등 흔적 자체는 남아있었으며, 400 시리즈부터 완전히 사라졌다.[7] 100 시리즈부터 완전히 사라졌다.[8] 500 시리즈부터 사용되지 않고 있다.[9] 마찬가지로 100 시리즈부터 완전히 사라졌다. RTX로 대체되었다.[10] 단정밀도 연산을 맡고 있기 때문에 Single Precision Unit이라고도 부르며, 그래픽 연산에서는 셰이딩을 담당하기 때문에 셰이더 유닛(Shader Unit)이라고도 부르지만 NVIDIA에서는 이를 'CUDA'라고 부름.[11] 연산(Operation)의 약자.[12] GPU 전체의 코어 클럭이 아니다.
2009년 3월부터 출시된 7세대 아키텍처 개선판이자 9번째 지포스의 리네이밍 겸 OEM 전용 제품군, 코드네임은 테슬라.
지포스 200 시리즈 칩셋의 출시 이후인 2008년 후반에 기존 칩셋들도 지포스 200 시리즈와 같은 형식의 네이밍으로 변경될거라는 방침에 따라 기존에 8 시리즈 → 9 시리즈로 넘어갈 때에는 공정이라도 개선될 겸 네이밍을 변경했다면, 이번엔 공정 변경도 없이 네이밍만 100 시리즈로 변경되었다.[13]
뚜껑을 열고 보니 지포스 8 시리즈의 65nm 공정 개선판이 지포스 9 시리즈였다면, 이쪽은 지포스 9 시리즈의 55nm 공정 개선판...이 아니라 이미 55nm로 공정 개선된 지포스 9 시리즈 일부를 리네이밍시킨 것(...). OEM용으로만 출시해서 2009년 2분기 즈음부터 출시된 노트북이나 브랜드PC에 확인할 수 있었지만, OEM 전용 라인업이라 인지도가 바닥을 기어가고 있다(...).
3.7.4. GeForce 200[편집]
3.7.5. GeForce 300[편집]
[13] 기존의 복잡한 네이밍 형식에서 벗어나려는 의도라고는 하지만, 그렇다고 시중에서 기존 모델의 네이밍이 새로운 형식으로 저절로 바뀌는게 아니기 때문에 사실상 더 복잡해진거나 다름 없었다.
2009년 11월 말부터 출시된 7.5세대 아키텍처이자 10번째 지포스의 리네이밍 겸 OEM 전용 제품군. 코드네임은 테슬라 2.0
지포스 100 시리즈와 마찬가지로 OEM용으로 출하된 칩셋으로 시중에는 풀리지 않았고 삼성, HP등 브랜드 PC 제조업체의 제품에서만 접할 수 있는 제품군이며, 브랜드 PC 내부에 장착되어 있던 OEM용 그래픽카드가 따로 적출되어 중고로 판매되기도 했다.
3.8. Fermi 아키텍처[편집]

GF100 GPU의 블록 다이어그램.

GF100 GPU와 GF104 GPU의 블록 다이어그램 비교.
- GF100 칩셋의 구성
- GPC 1개당 SM 4개씩 구성.
- SM 1개당 SP 32개씩, SFU 4개씩 구성. DPU는 없음.
- SP 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- SFU에서는 부동소수점 곱셈을 수행하지 않음 (연산 계산에서 제외됨)
- 배정밀도 연산은 2개의 단정밀도 연산 유닛을 이용해서 수행
- GF100 칩셋의 부동소수점 연산 성능 계산
- 단정밀도 연산 : (SP 개수 x 2op/cycle) x 셰이더 클럭
- 배정밀도 연산 : 단정밀도 연산 / 2
- GF104 칩셋의 구성
- GPC 1개당 SM 4개씩 구성.
- SM 1개당 SP 48개씩, SFU 8개씩 구성. DPU는 없음.
- SP 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- SFU에서는 부동소수점 곱셈을 수행하지 않음 (연산 계산에서 제외됨)
- 배정밀도 연산은 SM 내에 전체 SP 중 최대 16개(1/3)까지만 할당되고 4개의 단정밀도 연산 유닛을 이용해서 수행
- GF104 칩셋의 부동소수점 연산 성능 계산
- 단정밀도 연산 : (SP 개수 x 2op/cycle) x 셰이더 클럭
- 배정밀도 연산 : 단정밀도 연산 / 12
2018년 3월 27일에 v391.35 버전을 마지막으로 페르미 아키텍처 기반 모든 모델들의 드라이버 공식 지원이 중단되었다.
3.8.1. GeForce 400[편집]
3.8.2. GeForce 500[편집]
3.9. Kepler 아키텍처[편집]

GK104 GPU의 블록 다이어그램.

GK110 GPU의 블록 다이어그램.
- GK104 칩셋의 구성
- GPC 1개당 SMX 2개씩 구성.
- SMX 1개당 SP 192개씩, SFU 32개씩, DPU 8개씩 구성.
- SP 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- DPU 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- GK104 칩셋의 부동소수점 연산 성능 계산
- 단정밀도 연산 : (SP 개수 x 2op/cycle) x 클럭
- 배정밀도 연산 : (DPU 개수 x 2op/cycle) x 클럭 (또는 단정밀도 연산 / 24)
- GK110 칩셋의 구성
- GPC 1개당 SMX 3개씩 구성.
- SMX 1개당 SP 192개씩, SFU 32개씩, DPU 64개씩 구성.
- SP 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- DPU 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- GK110 칩셋의 부동소수점 연산 성능 계산
- 단정밀도 연산 : (SP 개수 x 2op/cycle) x 클럭
- 배정밀도 연산 : (DPU 개수 x 2op/cycle) x 클럭 (또는 단정밀도 연산 / 3)
3.9.1. GeForce 600[편집]
3.9.2. GeForce 700[편집]
3.9.3. GeForce TITAN[편집]
3.10. Maxwell 아키텍처[편집]

GM107 GPU의 블록 다이어그램.

GM204 GPU의 블록 다이어그램.
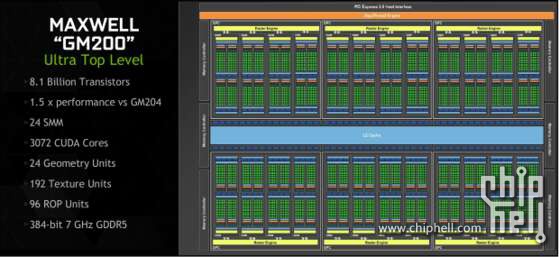
GM200 GPU의 블록 다이어그램.
- GM107 칩셋의 구성
- GPC 1개당 SMM 5개씩 구성.
- SMM 1개당 SP 128개씩, SFU 32개씩, DPU 4개씩 구성.
- SP 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- DPU 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- GM107 칩셋의 부동소수점 연산 성능 계산
- 단정밀도 연산 : (SP 개수 x 2op/cycle) x 클럭
- 배정밀도 연산 : (DPU 개수 x 2op/cycle) x 클럭 (또는 단정밀도 연산 / 32)
- GM200/204 칩셋의 구성
- GPC 1개당 SMM 4개씩 구성.
- SMM 1개당 SP 128개씩, SFU 32개씩, DPU 4개씩 구성.
- SP 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- DPU 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- GM200/204 칩셋의 부동소수점 연산 성능 계산
- 단정밀도 연산 : (SP 개수 x 2op/cycle) x 클럭
- 배정밀도 연산 : (DPU 개수 x 2op/cycle) x 클럭 (또는 단정밀도 연산 / 32)
3.10.1. GeForce 900[편집]
3.10.2. GeForce TITAN X[편집]
3.11. Pascal 아키텍처[편집]

GP104 GPU의 블록 다이어그램.

GP100 GPU의 블록 다이어그램.
- GP104 칩셋의 구성
- GPC 1개당 SM 5개씩 구성.
- SM 1개당 SP 128개씩, SFU 32개씩, DPU 4개씩 구성.
- SP 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- DPU 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- GP104 칩셋의 부동소수점 연산 성능 계산
- 단정밀도 연산 : (SP 개수 x 2op/cycle) x 클럭
- 배정밀도 연산 : (DPU 개수 x 2op/cycle) x 클럭 (또는 단정밀도 연산 / 32)
- 반정밀도 연산 : 단정밀도 연산 / 64
- GP100 칩셋의 구성
- GPC 1개당 SM 10개씩 구성.
- SM 1개당 SP 64개씩, SFU 16개씩, DPU 32개씩 구성.
- SP 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- DPU 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- GP100 칩셋의 부동소수점 연산 성능 계산
- 단정밀도 연산 : (SP 개수 x 2op/cycle) x 클럭
- 배정밀도 연산 : (DPU 개수 x 2op/cycle) x 클럭 (또는 단정밀도 연산 / 2)
- 반정밀도 연산 : 단정밀도 연산 x 2
3.11.1. GeForce 10[14][편집]
3.11.2. TITAN X/Xp[편집]
3.12. Volta 아키텍처[편집]

GV100 GPU의 블록 다이어그램.
- GV100 칩셋의 구성
- GPC 1개당 SM 14개씩 구성.
- SM 1개당 SP 64개씩, SFU 16개씩, DPU 32개씩 구성.
- SP 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- DPU 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- GV100 칩셋의 부동소수점 연산 성능 계산
- 단정밀도 연산 : (SP 개수 x 2op/cycle) x 클럭
- 배정밀도 연산 : (DPU 개수 x 2op/cycle) x 클럭 (또는 단정밀도 연산 / 2)
- 반정밀도 연산 : 단정밀도 연산 x 2
3.12.1. TITAN V[편집]
3.13. Turing 아키텍쳐[편집]
- TU102 칩셋의 구성
- GPC 6개, 기가스레드 엔진 1개, 메모리 채널 12개, PCIe 3.0 호스트 인터페이스 1개, 하이-스피드 허브 1개, NVLink 2 x8 링크로 구성.
- GPC 1개당 TPC 6개씩, 래스터 엔진 1개씩 구성.
- 래스터 엔진은 엣지 셋업, 래스터라이저, Z-컬로 구성.
- TPC 1개당 SM 2개씩, 폴리모프 엔진 1개씩 구성.
- 폴리모프 엔진은 버텍스 페치, 테셀레이터, 뷰포트 트랜스폼, 애트리뷰트 셋업, 스트림 아웃풋으로 구성.
- SM 1개당 FP32 64개씩, INT32 64개씩, 텐서 코어 8개씩, SFU 16개씩, FP64 2개씩, RT 코어 1개씩 구성.
- TU104 칩셋의 구성
- GPC 6개, 기가스레드 엔진 1개, 메모리 채널 8개, PCIe 3.0 호스트 인터페이스 1개, 하이-스피드 허브 1개, NVLink 2 x8 링크로 구성.
- GPC 1개당 TPC 4개씩, 래스터 엔진 1개씩 구성.
- 래스터 엔진은 엣지 셋업, 래스터라이저, Z-컬로 구성.
- TPC 1개당 SM 2개씩, 폴리모프 엔진 1개씩 구성.
- 폴리모프 엔진은 버텍스 페치, 테셀레이터, 뷰포트 트랜스폼, 애트리뷰트 셋업, 스트림 아웃풋으로 구성.
- SM 1개당 FP32 64개씩, INT32 64개씩, 텐서 코어 8개씩, SFU 16개씩, FP64 2개씩, RT 코어 1개씩 구성.
- TU106 칩셋의 구성
- GPC 3개, 기가스레드 엔진 1개, 메모리 채널 8개, PCIe 3.0 호스트 인터페이스 1개로 구성.
- GPC 1개당 TPC 6개씩, 래스터 엔진 1개씩 구성.
- 래스터 엔진은 엣지 셋업, 래스터라이저, Z-컬로 구성.
- TPC 1개당 SM 2개씩, 폴리모프 엔진 1개씩 구성.
- 폴리모프 엔진은 버텍스 페치, 테셀레이터, 뷰포트 트랜스폼, 애트리뷰트 셋업, 스트림 아웃풋으로 구성.
- SM 1개당 FP32 64개씩, INT32 64개씩, 텐서 코어 8개씩, SFU 16개씩, FP64 2개씩, RT 코어 1개씩 구성.
- TU116 칩셋의 구성
- GPC 3개, 기가스레드 엔진 1개, 메모리 채널 6개, PCIe 3.0 호스트 인터페이스 1개로 구성.
- GPC 1개당 TPC 4개씩, 래스터 엔진 1개씩 구성.
- 래스터 엔진은 엣지 셋업, 래스터라이저, Z-컬로 구성.
- TPC 1개당 SM 2개씩, 폴리모프 엔진 1개씩 구성.
- 폴리모프 엔진은 버텍스 페치, 테셀레이터, 뷰포트 트랜스폼, 애트리뷰트 셋업, 스트림 아웃풋으로 구성.
- SM 1개당 FP32 64개씩, INT32 64개씩, FP16 128개씩, SFU 16개씩, FP64 2개씩 구성.
- TU102/104/106 칩셋의 연산 성능 계산
- FP16, INT8, INT4 연산은 텐서 코어를 이용해서 수행.
- INT32 연산은 INT32 연산 전용 유닛을 이용해서 수행.
- FP32 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- INT32 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- FP16 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 64(= 4 × 4 × 4)번씩 수행하므로 총 128op/cycle.
- FP32 연산 : (FP32 개수 × 2) × (GPU 클럭)
- FP64 연산 : (FP64 개수 × 2) × (GPU 클럭) ※ (FP32 연산) ÷ 32
- FP16 연산 : (텐서 코어 개수 × 2) × (GPU 클럭) × 64
- INT32 연산 : (INT32 개수 × 2) × (GPU 클럭)
- INT8 연산 : (텐서 코어 개수 × 2) × (GPU 클럭) × 64 × 2
- INT4 연산 : (텐서 코어 개수 × 2) × (GPU 클럭) × 64 × 4
- 레이 트레이싱 연산 : 1 GigaRays/sec = 100~110 TFLOPS (주어진 제원을 이용한 구체적인 계산 방법은 불명.)
- RTX-OPS : {(FP32 연산) × 0.8} + {(INT32 연산) × 0.28} + {(FP16 연산) × 0.2} + {(레이 트레이싱 연산) × 0.4}
- TU116 칩셋의 연산 성능 계산
- FP16 연산은 FP16 연산 전용 유닛을 이용해서 수행.
- INT8, INT4 연산은 INT32 연산 전용 유닛을 이용해서 수행.
- FP32 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- INT32 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- FP16 한 사이클당 한 번의 덧셈과 한 번의 곱셈을 수행하므로 총 2op/cycle.
- FP32 연산 : (FP32 개수 × 2) × (GPU 클럭)
- FP64 연산 : (FP64 개수 × 2) × (GPU 클럭) ※ (FP32 연산) ÷ 32
- FP16 연산 : (FP16 개수 × 2) × (GPU 클럭) ※ (FP32 연산) × 2
- INT32 연산 : (INT32 개수 × 2) × (GPU 클럭)
- INT8 연산 : (INT32 연산) × 4
- INT4 연산 : (INT32 연산) × 8
3.13.1. GeForce 16[편집]
 자세한 내용은 GeForce 16 문서를 참고하십시오.
자세한 내용은 GeForce 16 문서를 참고하십시오. 3.13.2. GeForce 20[편집]
자세한 내용은 GeForce 20 문서를 참고하십시오. 3.13.3. TITAN RTX[편집]
자세한 내용은 TITAN RTX 문서를 참고하십시오. 3.14. 차세대 아키텍처[편집]
Turing 아키텍처의 뒤를 이을, 아직 정식 명칭이 공개되지 않은 아키텍처이다. 2017년 GTC 유럽 NVIDIA CEO 젠슨 황의 오프닝 키노트에서 발표된 세계 최초의 로봇 택시용 AI 컴퓨터 페가수스(Pegasus)에 이 아키텍처 기반 GPU가 Volta 아키텍처 기반 임베디드 GPU를 탑재한 자비에(Xavier) SoC 프로세서와 함께 결합될 예정이다.
4. 관련 문서[편집]
- NVIDIA
- NVIDIA PureVideo
- NVIDIA Workstation GPU 일람
- NVIDIA 모바일 GPU 일람
- AMD GPU 일람
- 3dfx Voodoo
- 인텔 GPU 일람