TSMC/공정 노드 추이
덤프버전 :
분류
 상위 문서: TSMC
상위 문서: TSMC 1. 개요
2. 초기
3. 0.5 μm (1994년)
4. 0.35 μm (1996년)
5. 0.25 μm (1998년)
6. 0.22 μm (1998년)
7. 0.18 μm (1999년)
8. 0.15 μm (2000년)
9. 0.13 μm (2001년)
10. 0.11 μm (2003년)
11. 90 nm (2004년)
12. 80 nm (2005년)
13. 65 nm (2006년)
14. 55 nm (2007년)
15. 45 nm (2008년)
16. 40 nm (2008년)
17. 28 nm (2011년)
18. 20 nm (2014년)
19. 16 nm (2015년)
20. 12 nm (2016년)
21. 10 nm (2016년)
22. 7 nm (2018년)
23. 6 nm (2020년)
24. 5 nm (2020년)
25. 4 nm (2021년)
26. 3 nm (2022년)
27. 2 nm (2025년)
28. 1.4nm(2027년)
1. 개요[편집]
TSMC의 공정 노드 추이를 정리한 문서.
2. 초기[편집]
초창기에는 3 μm 개발부터 시작해서 1988년 1.5 μm, 1989년 1.2 μm, 1990년 1 μm, 1992년 0.8 μm, 1993년 0.6 μm 공정으로 미세화를 거쳐가면서 역량을 쌓는 시기였다.
3. 0.5 μm (1994년)[편집]
- 3dfx Interactive Voodoo (1996년)
TSMC와 3dfx Interactive의 인연이 시작된 공정 노드.
4. 0.35 μm (1996년)[편집]
- 3dfx Interactive Voodoo Rush (1997년)
- 3dfx Interactive Voodoo 2, Voodoo Banshee (1998년)
- NVIDIA RIVA TNT (1998년)
이때부터 TSMC와 NVIDIA의 인연이 시작된 공정 노드. 그동안 NVIDIA는 STMicroelectronics에 위탁 생산을 맡겼다가 RIVA TNT부터 TSMC로 갈아탔다. 공정의 한계인지 NVIDIA가 원하는 프로세서 클럭만큼 달성하지 못 해서 목표치보다 언더클럭된 상태로 (110 → 90 MHz) 출고할 수밖에 없었다.
5. 0.25 μm (1998년)[편집]
- ATI Rage 128 시리즈 (1998~1999년)
- 3dfx Interactive Voodoo 3 시리즈 (1999년)
- NVIDIA RIVA TNT2 시리즈 (1999년)
- ATI Rage Fury MAXX (2000년)
- 3dfx Interactive Voodoo 5 5500, Voodoo 4 4500 (2000년)
이번에는 TSMC와 ATI의 인연이 시작된 공정 노드. ATI가 기존에 UMC나 STMicroelectronics에 위탁 생산을 맡겼는데 Rage 128부터 TSMC로 옮겼다.
6. 0.22 μm (1998년)[편집]
- NVIDIA RIVA TNT2 Pro (1999년)
- NVIDIA GeForce 256 (1999~2000년)
0.25 μm 공정의 하프 노드.
7. 0.18 μm (1999년)[편집]
TSMC를 메이저 파운드리로 거듭나게 만들어준 일등 공신. 공식 홈페이지에서 공정 노드 소개할 때 0.18 μm부터 강조된 이유이기도 하다.
8. 0.15 μm (2000년)[편집]
- NVIDIA GeForce 3 시리즈 (2001년)
- ATI Radeon 8500 (2001년)
- NVIDIA GeForce 4 시리즈 (2002년)
- ATI Radeon 9700 시리즈, 9500 시리즈 (2002년)
- ATI Radeon 9800 시리즈 (2003년)
0.18 μm 공정의 하프 노드.
9. 0.13 μm (2001년)[편집]
- NVIDIA GeForce FX 시리즈 대부분 (2003년)
- ATI Radeon 9600 시리즈 (2003년)
- ATI Radeon X800 시리즈, X600 시리즈 (2004년)
승승장구하던 TSMC한테 잠시 주춤했던 공정. NVIDIA의 지포스 FX 시리즈에 사용될 GPU 제조로 수주 받았는데, 하필 덜 성숙된 상태에서 생산을 주문받은데다 지포스 FX 시리즈에 채택된 CineFX GPU 마이크로아키텍처가 워낙 비효율적인 혼종 구조로 총체적 난국을 보여줬기 때문에, TSMC한테도 본의 아니게 이미지에 타격을 받았다. 이 여파로 NVIDIA는 FX 시리즈 중에 가장 나중에 투입된 FX 5700 시리즈부터 다음 세대인 지포스 6800 시리즈 일부 라인까지 잠시 IBM 0.13 μm 공정으로 바꾸게 됐다.
10. 0.11 μm (2003년)[편집]
- NVIDIA GeForce 6 시리즈 대부분 (2004~2005년)
- ATI Radeon X700 시리즈, X300 시리즈 (2004~2005년)
- NVIDIA GeForce 7800 시리즈 (2005년)
0.13 μm 공정의 하프 노드.
11. 90 nm (2004년)[편집]
- ATI Radeon X1800 시리즈, X1600 시리즈, X1300 시리즈 (2005년)
- ATI Radeon X1900 시리즈, X1950 XT (2006년)
- NVIDIA GeForce 7 시리즈 대부분 (2006년)
- NVIDIA GeForce 8800 시리즈 일부 (2006~2007년)
12. 80 nm (2005년)[편집]
- ATI Radeon X1650 시리즈, X1950 Pro (2006년)
- NVIDIA GeForce 7600 GT AGP (2007년)
- NVIDIA GeForce 8600 시리즈, 8500 GT, 8400 GS 초기형 (2007년)
- AMD ATI Radeon HD 2900 시리즈 (2007년)
90 nm 공정의 하프 노드.
13. 65 nm (2006년)[편집]
- AMD ATI Radeon HD 2600 시리즈, HD 2400 시리즈 (2007년)
- NVIDIA GeForce 8800 시리즈 일부, GeForce 8400 GS 후기형 (2007~2008년)
- NVIDIA GeForce 9 시리즈 일부, GeForce 200 시리즈 일부 (2008년)
- 퀄컴 스냅드래곤 S1 시리즈 QSD8250 SoC (2008년)
14. 55 nm (2007년)[편집]
- AMD ATI RADEON HD 3000 시리즈 (2007~2008년)
- AMD ATI RADEON HD 4000 시리즈 대부분 (2008~2009년)
- NVIDIA GeForce 9 시리즈 일부, GeForce 200 시리즈 일부 (2008~2009년)
65 nm 공정의 하프 노드.
15. 45 nm (2008년)[편집]
- 퀄컴 스냅드래곤 S2 시리즈 MSM8255 SoC (2010년)
- 퀄컴 스냅드래곤 S3 시리즈 MSM8260 SoC (2011년)
16. 40 nm (2008년)[편집]
- AMD ATI RADEON HD 4770 (2009년)
- AMD ATI RADEON HD 5000 시리즈 (2009~2010년)
- NVIDIA GeForce 200 시리즈 일부 (2009년)
- NVIDIA GeForce 400 시리즈, GeForce 500 시리즈 (2010년)
- AMD RADEON HD 6000 시리즈 (2010~2011년)
45 nm 공정의 하프 노드이자, TSMC의 두 번째 시련이 닥친 공정 노드로 발주처인 AMD와 NVIDIA 둘 다 수율 문제를 겪고 말았다. 특히 NVIDIA의 지포스 GTX 480에 탑재된 GF100은 누설 전류까지 의심할 정도. 그동안 일부 컴덕들만 GPU의 제조 공정이랑 생산 업체가 어디인지 아는 정도였는데, 이 시기에 들어서야 '이게 다 TSMC 때문이다'라는 말장난을 통해 조립 컴퓨터 초보자들까지도 널리 알려지기 시작했다.
17. 28 nm (2011년)[편집]
- AMD RADEON HD 7000 시리즈 (2012~2013년)
- NVIDIA GeForce 600 시리즈 일부 (2012~2013년)
- 퀄컴 스냅드래곤 S4 Plus 시리즈 MSM8960 SoC, S4 Pro 시리즈 APQ8064 SoC (2012년)
- NVIDIA GeForce 700 시리즈 (2013~2014년)
- 텍사스 인스트루먼트 OMAP 5 시리즈 (2013년)
- 퀄컴 스냅드래곤 600 APQ8064T (2013년)
- 퀄컴 스냅드래곤 800 MSM8974 (2013년)
- AMD RADEON Rx 200 시리즈 (2013년)
- 퀄컴 스냅드래곤 801 MSM8974AC, 805 APQ8084 (2014년)
- NVIDIA GeForce 900 시리즈 (2014~2015년)
- AMD RADEON Rx 300 시리즈, R9 FURY 시리즈 (2015년)
AMD와 NVIDIA의 GPU들이 또 다시 공정 문제로 출시가 늦어진 바 있었던 공정. 원래는 TSMC가 32 nm 공정을 건너뛰고 하프 노드인 28 nm를 2011년 하반기 출시 예정이었으나 늘상 그랬듯이 지연됐고, 결국 실질적인 첫 28nm 제품은 2012년이 돼서야 시중에 풀리기 시작. HD7970이 2011년 12월 런칭했으나 사실상 페이퍼 런칭이었고, 실물은 다음 해 1월쯤부터 유통되기 시작했다. 그러나 생산을 시작하고도 수율이 매우 좋지 않아 물량 수급이 원활하지 못했고, AMD와 엔비디아 양 사가 제시했던 공시가인 549$ 499$은 그야말로 숫자에 지나지 않을 만큼 무의미해졌다.
저 공정 문제에 대해 조금 더 보충 설명을 하자면, TSMC는 안정적인 제품을 뽑아낼 수 있는 30nm Half-Bridge 공정을 뛰어넘고 바로 28nm 공정으로 들어갔다. 과거 기록에 따르면, TSMC가 55nm에서 바로 40nm로 점프할 때에도 동일한 증세(불량률이 일시적으로 증가하는 현상)가 나타났는데 이 증세가 또 다시 번진 것이다. 이것으로 가장 큰 피해를 본 것이 GTX 400시리즈. 안 그래도 설계상으로 말이 많았는데 이 문제까지 겹쳐 누설 전류가 미친듯이 증가했고, 결국 GTX 480은 역대 최악의 발열킹으로 이름을 날리게 됐다
그리고 그 이후에 20nm 공정도입도 늦어지더니 그냥 건너 뛰고 각각 16nm, 14nm 공정으로 넘어간다고 선언했을 정도이다. 다만 모바일에 한해서 20나노 공정은 다행히 안착이 가능했다.
그런데 이러한 증세가 TSMC에서만 일어나는 특별한 것으로 착각하는 사람들이 더러 있다. 하지만 원래 반도체 공정 돌입 초기에서는 그러한 증세가 늘 일어나는 일이며, 완전한 공정이 꾸려지지 않았다는 것을 뻔히 알면서도 경쟁적으로 주문 넣은 NVIDIA와 AMD가 너무 조급했다고 볼 수도 있는 것이다. 현재 NVIDIA와 AMD의 공정 세밀화는 기술적으로 요구되는 것이라기 보다는 단순한 브랜드 경쟁이라는 관측이 크다. 실제로 이들 기업에서 생산하고자 하는 반도체는 굳이 28nm 공정으로 만들지 않아도 이전 공정으로도 충분히 생산을 할 수 있는 것들이다. 쉽게 이야기해서 누가 먼저 신공정으로 칩을 뽑아내나 경쟁하다가 TSMC에게 돈 갖다 바치고 라인 시운전을 하게 해준 격이다. 여기에 대한 반론으로는 GPU 같은 칩의 특성상 무작정 때려박는 것이 성능 향상에 있어선 제일 효율적인 방법이기 때문에 신공정일수록 압도적으로 유리하다는 사실이 있긴 하다. 그러니까 그저 단순한 브랜드 경쟁이 아니라, 목표하고자 하는 성능을 내기 위해서는 어쩔 수 없이 감행해야 하는 셈. 같은 성능만큼 때려박더라도 신공정으로 만든 칩의 물리적인 크기, 그에 따른 발열과 전력소모량이 압도적으로 좋기 때문이다.
다만, 반도체 생산 설비를 직접 갖추지 않고 주문만 넣는 팹리스(Fabless) 입장에서는 TSMC의 이러한 행보에 분통이 터질 수밖에 없다. 만일 TSMC의 지위가 지금과 달리 다른 업체와 경쟁적인 상태에 놓여 있었다면 NVIDIA건 AMD건 무리한 주문을 하려고 할 때 완곡히 거절했을 것이다[1]. 하지만 TSMC는 사실상 과점적 파운드리 업체이기 때문에 그냥 무작정 OK를 때렸을 가능성이 높다.
참고로, TSMC의 생산효율 문제로 여러 제품의 공급이 차질을 빚을 때 국내 하드웨어 커뮤니티들에서 등장하는 단골 떡밥으로 삼성에게 파운드리를 맡기자하는 것이 있다. 그런데 이러한 것은 반도체 생산에 대한 지식이 일천하다는 것을 스스로 인정하는 것에 불과하다. 삼성과 TSMC가 가진 기술의 범주가 다르기 때문에 두 회사의 기술력 수준을 비교하는 것이 올바르지 않다. TSMC의 주된 수익은 구세대 공정, 즉 안정화된 공정에서 나온다. 따라서 힘들여서 공정 미세화를 서두를 필요가 없으며, 이는 모바일 시장에 뛰어들어서 공정 미세화가 제품의 품질과 직결되어 있는 삼성전자와는 정반대의 상황. 크기가 작은 모바일 제품군에 비해 CPU나 그래픽 카드는 크기가 큰 빅칩이다.
파운드리라는 것은 기술 확보보다는 경험 축적에 의한 기술 안정화가 필수적이다. 파운드리 서비스를 TSMC처럼 극대규모로, 그리고 장기간 해 본 경험이 없는 삼성전자로서는 아무리 반도체 연구ㆍ개발 기술이 뛰어나다 하더라도 오늘날 TSMC가 담당하고 있는 파운드리 서비싱은 감당하기 어렵다.
일각에서는 TSMC가 공격적으로 라인을 증설하고 기술 개발에 나서야 한다고 이야기하지만 일단 파운드리 서비스가 생각보다 그렇게 남는 장사가 아니기 때문에 공격적으로 투자했다가 망하면 으앙 죽음 꼴 나기 십상이다. 그래서 TSMC에서는 팹리스 기업들에 피해를 떠넘기면서까지 보수적인 라인 증설과 기술 개발을 하고 있는 것이다. 라인 증설이 말이 증설이지, 그렇게 쉬운 일이 아니다. 막대한 자금이 들어가는 것은 물론이고, 일반적인 기계의 생산 라인과들 달리 설계한 대로 뚝딱 만들어지는 것도 아니고 지금과 같은 45nm 이하의 초정밀 공정에서는 반도체 공학뿐만 아니라 양자 역학, 열역학 등과 같은 기초 과학에 속하는 기술까지 총 동원해야 한다.
TSMC가 미적거리는 또 다른 이유로는 TSMC의 파운드리 시장 내에서의 입지를 꼽을 수 있다. TSMC가 싫다고 다른 회사를 찾아가봤자 돌고돌아서 올 수 있는 곳은 TSMC밖에 없다. 사실상 TSMC는 파운드리 시장 내에서 과점 기업이며 좀 오버하자면 독점 기업이라고 해도 과언이 아니다. 이러한 상황에서는 ‘잘 못해줘도 어차피 우리 고객’이 성립하기 때문에 고객의 주문보다는 자신들의 이득을 더 생각할 수밖에 없는 것이다.
어찌됐건 현재의 TSMC 28nm공정은 상당히 안정된 것으로 보이며, 최근에는 2016년 1/4까지의 주문이 완료된 것으로 보인다. TSMC에서 생산하는 반도체에는 컴퓨터와 스마트 폰에 쓰이는 것에서부터 시작해서 가정용 전자제품에 들어가는 MPU, 자동차에 들어가는 EPU 등 미처 생각지도 못한 온갖 것들이 포함된다.
밑에 언급된 Apple의 칩셋 발주 문제도 TSMC 회장이 퀄컴과의 관계를 이유로 들었지만, 실제로는 TSMC 공장이 이미 퀄컴 칩셋을 뽑는 것 자체도 힘에 부친 상황일 가능성이 크다. 그렇기 때문에 불과 몇년 전엔 Apple의 TSMC 미발주 사태는 Apple이 TSMC에 안 맡긴다가 맞았지만, 이후에는 못 맡긴 것이라고 보는 편이 맞을 것이다. iPhone 6 제품군에 장착되는 A8은 TSMC가 수주했다.
18. 20 nm (2014년)[편집]
- Apple A8 SoC (2014년)
- Apple A8X SoC (2014년)
- 퀄컴 스냅드래곤 810 MSM8994, 808 MSM8992 (2015년)
19. 16 nm (2015년)[편집]
- Apple A9 SoC APL1022 한정 (2015년)
- Apple A9X SoC (2015년)
- NVIDIA GeForce 10 시리즈 일부 (2016년)
- Apple A10 Fusion SoC (2016년)[P]
- 관련 자료
세계 파운드리 시장의 기업 순위 목록이다. 1위는 역시 부동의 TSMC. 여러 가지 말은 많지만 아직까지는 넘사벽으로 매출 기준 40%대 후반의 점유율을 보여주고 있다. 그러나 삼성전자 및 경쟁기업들의 점유율 상승이 잠재적 위험이며 글로벌 파운드리 + 삼성전자 연합이 14nm FINFET 양산에 먼저 들어가는데2014년 4분기 양산시작 성공했고삼성 양산 시작, 아이폰 6s 도 다시 삼성으로 돌아갈 줄 알았는데, 애플은 삼성 14nm, TSMC 16nm에 동시에 같은 AP 생산을 맡기는 이례적인 짓을 저질렀다. 같은 AP를 만들며 성능을 누가 더 잘 뽑아내냐는, 비교당하기 딱 좋은 배틀 아레나가 펼쳐진 것이다. 이에 대한 예상은 삼성 AP가 성능상 우세할 것이라는 반응이었으나, 결과는 TSMC AP와 삼성 AP가 유의미한 성능 차이가 없다. 이는 TSMC가 삼성과의 기술력 경쟁에서 이겼다고까지 표현하는 게 오버라면 적어도 절대로 지지는 않았다고 해석될 수 있으며, 삼성으로서는 우려할 만한 상황이라 할 수 있다. 다만 이후 표본이 늘어나면서 이러한 차이가 같은 Fab에서 나온 개별 칩셋끼리 보이는 편차와 큰 차이가 없다는 선에서 정리됐다. 사실 어느 쪽이든 설계는 애플이 맡기 때문에 동일한 성능의 AP를 주문해서 차별 논란을 없애려 했을게 뻔하고, 때문에 큰 차이를 보이는 일이 벌어지기 어려울 수밖에 없다. 여하튼 하도 드문 상황이라 사람들도 정확한 판단을 하기 어려웠다고 보아야 한다.
양산 시기로 따지면 20nm 모바일 AP 상용화 시기는 2014년 하반기로 TSMC와 삼성팹이 비슷한 상황이었지만, 14/16nm 모바일 AP 상용화는 삼성팹이 훨씬 빠른 상황이다. 하지만 소위 빅칩이라 불리는 시스템반도체 제품군들에서는 이제 삼성은 걸음마 단계에 올라와 있는 형국이다. 삼성이 양산기술과 수율이 좋다고 알려져 있지만 이는 작은 모바일 칩이기 때문에 가능하다는 분석도 있다. 물론 최근에는 모바일 AP 시장이 확대되면서 모바일 AP 중에서도 시스템반도체에 육박하는 사이즈를 가진 빅칩이 튀어나오기도 한다. 사이즈와 수율의 상관관계는 다음 글을 참조하자. 요약하자면 불량이 포함된 칩셋은 버리거나 코어를 비활성화해야 하는데 사이즈가 클수록 버려야 하는 부분이 늘어난다는 의미다. 즉 상대적으로 품질관리가 더욱 어렵고 TSMC는 태생부터 빅칩에서 시작한 기업이라 상대적 신뢰성은 삼성보다 높다고 할 수 있다. 삼성 또한 이런 약점을 알고 있기에 2016년 14nm LPP로 폴라리스10/11 GPU를 라이센스 생산함으로써 빅칩 생산을 본격적으로 시작했다. 공정을 라이센스했을 뿐 글로벌 파운더리에서 생산되므로 삼성이 직접 생산하지는 않았지만, 앞으로는 삼성도 직접 도전할 것으로 보인다. 물론 이전에도 남는 팹으로 엔비디아의 엔트리급~로우엔드급 (GK108 / GM206) GPU를 생산한 전력은 있다. 본격적인 생산협력에 대한 양해각서도 체결됐기에 다음 세대부터는 메인스트림급에서도 삼성 생산 엔비디아 GPU를 볼 수 있을지도 모른다.
20. 12 nm (2016년)[편집]
- NVIDIA TITAN V (2017년)
- NVIDIA GeForce 20 시리즈 (2018년)
- NVIDIA GeForce 16 시리즈 (2019년)
16 nm 공정의 하프 노드. 메탈 피치가 더 조밀해져 밀도가 약 19% 상승됐다.
21. 10 nm (2016년)[편집]
- Apple A10X Fusion SoC (2017년)
- Apple A11 Bionic SoC (2017년)
22. 7 nm (2018년)[편집]
- Apple A12 Bionic SoC (2018년)
- Apple A12X Bionic SoC (2018년)
- 퀄컴 스냅드래곤 855 SM8150, 8CX SC8180X, 855+ SM8150-AC (2019년)
- AMD Radeon VII (2019년)
- AMD ZEN 2 마이크로아키텍처 (2019년)
- AMD Radeon RX 5000 시리즈 (2019년)
- 디멘시티 800 (2019년)
- 디멘시티 1000 (2019년)
- 디멘시티 1000L (2019년)
- Apple A13 Bionic SoC (2019년)[P]
- Apple A12Z Bionic SoC (2020년)
- 퀄컴 스냅드래곤 865 SM8250, 865+ SM8250-AB (2020년)[P]
- NVIDIA A100 (2020년)
- AMD ZEN 3 마이크로아키텍처 (2020년)
- AMD Radeon RX 6000 시리즈 (2020년)
- 디멘시티 700(6020) (2020년)
- 디멘시티 720 (2020년)
- 디멘시티 800U (2020년)
- 디멘시티 820 (2020년)
- 디멘시티 1000C (2020년)
- 디멘시티 1000+ (2020년)
최근 반도체 업계에서는 패터닝[2] 선폭을 줄이기 위해 EUV(Extreme Ultra Violet)을 도입하는 추세다. EUV는 극자외선으로 미세 패턴을 형성하는 장비이다. 파장이 짧을수록 선폭이 좁아진다. DVD에서 블루레이로 이행되는 과정과 비슷하다. 이 장비의 개발이 늦어지면서(전량 ASML 생산) 여기에 대해 삼성과 TSMC는 완전히 다른 태도를 보이고 있다. 삼성은 일찌감치 10nm 파생공정을 늘려가면서 EUV 양산이 시작될 때까지 10nm에서 버텨보겠다는 태도를 보이고 있고,
ArFi 멀티패터닝을 이용한 7nm 공정은 멀티패터닝으로 인한 폭발적 비용 증가가 발생하므로 삼성은 EUV가 있어야만 7nm 공정에 돌입할 수 있다는 입장이고 TSMC는 이를 감수하더라도 일단 공정을 선도하고 EUV를 도입하면 그때 그것도 쓰면 된다는 관점. 때문에 당분간은 삼성보다 TSMC가 공정 면에서는 앞서가지만, 대신 최신 공정 물량은 훨씬 적게 나오는 상황(삼성은 7nm ArFi를 대응하는 8nm LPP 공정을 갖추고 있다. 7nm EUV 도입 직전의 공백을 매우기 위함으로 풀이된다. 또한 TSMC의 7nm ArFi 공정과 삼성의 8nm LPP공정은 비슷하다고 볼 수 있다.)이 유지될 것으로 예상 됐다.
2017년 4분기에 7nm ArFi 공정을 테이프 아웃을 했다고 한다. 최초 생산품은 Apple의 모바일 AP인 A12 Bionic이 될 것이라고 한다. 실제로 기기에 탑재되는 시기는 2018년 1분기에서 2분기 사이로 추정되며 이로 인해 확실하게 삼성보다 공정상 우위를 가져오게 됐다. 다만, 한시적이기 때문에 7nm EUV 공정의 양산 일정에 따라 어떻게 될지 결정될 듯하다. 다만, 원가 문제가 존재하지만 성능 게인상 7nm EUV 공정 대비 7nm ArFi 공정이 손해를 보지는 않기 때문에 7nm ArFi 공정으로 생산이 예정되어 있어도 걱정할 부분은 적다는 평가도 있다. 다만 삼성이 7mm EUV 공정의 양산을 준비하고 있고 당초 계획보다 6개월 앞당겼기 때문에 이후 변화가 주목된다. #
그러나 2020년 현 시점에서 되돌아 보았을 때, 삼성은 EUV 공정 양산 시기를 지속적으로 순연시키게 됐고, 그에 따라 TSMC의 N7 공정에서 양산된 A12 Bionic와 퀄컴 스냅드래곤 855와 같은 7nm 모바일 AP들이 각각 18년 하반기, 19년 상반기에 등장했고, AMD와 같은 회사들도 본격적으로 TSMC의 N7 HPC 공정을 활용하여 마티스, 르누아르와 같은 7nm CPU와 APU를 양산할 동안 삼성은 19년 하반기에 삼성 엑시노스 9825를 양산하기 시작하면서 양산 시점에도 확연히 밀리게 됐고, 그에 따라 기존에 보유하고 있던 퀄컴과 같은 고객들도 상당 부분 뺏기게 됐다. 7nm 경쟁에서는 공격적으로 캐파를 확장하여 고객들을 유치한 TSMC가 확연히 앞섰다는 평이 대다수. 그렇지만 이전 서술과 같이 삼성이 자사 시스템 LSI를 제외하면 고객을 아예 유치하지 못했다는 것은 전혀 사실이 아니다.
TSMC는 AMD의 CPU와 APU, 그리고 콘솔용 APU의 수주를 받았고, Apple이나 하이실리콘과 같은 모바일 AP 업계에서 알짜라고 불리는 기업들로부터 수주를 받았고, 향후 인텔과 같은 기업에도 수주를 받을 것으로 전망이 되고 있다. 규모는 웨이퍼 18만장으로 예측이 되고 있다. 모두 시스템반도체 부문의 공룡들이기 때문에 어마어마한 지분의 파이를 가져간 것으로 보인다. 반면 삼성은 자사의 시스템 LSI 부서로부터 수주를 받았고, 7LPP 공정 X50 모뎀칩, 800 라인업을 제외한 퀄컴 스냅드래곤 700 라인업과 퀄컴 스냅드래곤 600 라인업을 수주하는데 성공했다. 855/865를 놓친 것은 치명적이지만 주문한 웨이퍼 수로만 따지면 7LPP, 8LPP 공정에서 나오는 스냅드래곤 6/700 라인업이 압도적으로 많다. 이번해의 765&765G 탑재 스마트폰량이 증명. 삼성 측에서의 언플도 많지만 TSMC측에서의 언플도 디지타임즈를 통하여 대대적으로 이뤄지고 있다. 디지타임즈는 퀄컴 스냅드래곤 765의 수주를 맡은 삼성 7nm 공정의 수율이 나쁘다고 언플을 한 전력이 있다
그리고 IBM으로 부터 POWER10 CPU를 수주하는데 성공했는데 이는 600mm^2 대의 빅칩이다. 그리고 2020년 하반기에는 자사의 7nm 공정은 아닌 8nm LPP 공정을 통하여 엔비디아의 암페어 GPU의 GA100 칩셋을 제외한 게이밍용 라인업을 전량 수주하는데 성공했다. 2019년 6월 그래픽 카드 칩셋 제조사 NVIDIA가 삼성전자를 통해 차세대 GPU를 생산할 것이라는 소식이 있었으나, 2020 CES를 앞둔 젠슨 황의 인터뷰에서 차세대 GPU인 암페어 물량은 기본적으로 TSMC에서 생산하고, 수요가 증가할 경우에만 부분적으로 삼성이 수주할 것이라고 공개됐지만 이후 TSMC와의 협상 결렬, 단가 측면에서의 삼성팹이 메리트가 있다고 판단하여 삼성 팹에서의 생산이 결정됐다. GA102 칩도 600mm^2 대의 크기를 가지는 빅칩이고 NVIDIA Orin 또한 만만치 않은 크기를 가진 빅칩이다. 물론 위에 서술된 것을 다 합해도 점유율 측면에서는 TSMC 측이 더 많다.
23. 6 nm (2020년)[편집]
- 디멘시티 810(6080) (2021년)
- 디멘시티 900 (2021년)
- 디멘시티 920 (2021년)
- 디멘시티 1100(8020) (2021년)
- 디멘시티 1200 (2021년)
- 퀄컴 스냅드래곤 778G, 778G+ (2021년)
- 디멘시티 930(7020) (2022년)
- 디멘시티 1050(7030) (2022년)
- 디멘시티 1080(7050) (2022년)
- 디멘시티 1300(8050) (2022년)
- AMD ZEN 3+ 마이크로아키텍처 (2022년)
- AMD Radeon RX 6000 시리즈 하위 제품군 (2022년)
- 인텔 아크 알케미스트 GPU (2022년)
- AMD ZEN 4 마이크로아키텍처 cIOD (2022년)
- 퀄컴 스냅드래곤 782G (2022년)
- AMD Radeon RX 7000 시리즈 MCD 부분 및 하위 제품군 (2023년)
24. 5 nm (2020년)[편집]
- Apple A14 Bionic SoC (2020년)
- Apple M1 SoC (2020년)
- Apple A15 Bionic SoC (2021년)[P]
- M1 Pro, M1 Max SoC (2021년)
- M1 Ultra SoC (2022년)
- NVIDIA H100 (2022년)[3]
- NVIDIA GeForce 40 시리즈 (2022년)[4]
- Apple M2 SoC (2022년)[P]
- AMD ZEN 4 마이크로아키텍처 (2022년)
- AMD Radeon RX 7000 시리즈 (2022년)
- 디멘시티 8000 (2022년)
- 디멘시티 8100 (2022년)
- Apple M2 Pro, M2 Max, M2 Ultra SoC (2023년)[P]
정식 양산 절차에 돌입하지는 않았으나 5nm 공정도 리스크 생산을 진행 중이다. 리스크 생산이란 파운드리 생산자가 생산에서 수반되는 손실 비용의 상당 부분을 부담하고 초도 공정을 테스트하는 과정. 대상 제품은 일본의 PEZY 컴퓨터 회사의 프로세서 칩셋이다. 2019년 4월 초 초도 리스크 생산 결과 양산 공정을 개발할 수 있는 결과를 얻었다.
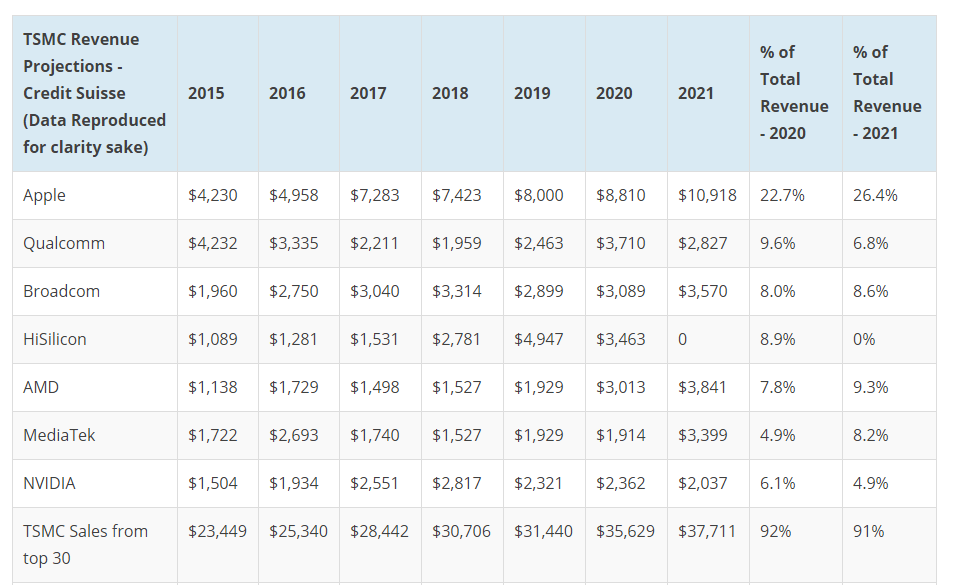

단, 스냅드래곤 888의 수주물량을 전량 삼성에게 빼앗겼다고 한다. 당시에는 이름이 공개되지 않았기 때문에 해당 AP는 네이밍 규칙에 따라서 875가 될 것으로 예상됐으나, 정식 명칭은 888이 됐다. 따라서 여기서 지칭하는 875 = 888이다. 그리고 엔비디아의 8nm GPU에 이어 엔비디아의 5nm GPU까지 삼성 파운드리에서 생산되는 것이 기정사실화 됐다. 그러나, Apple Silicon A14 Bionic의 TSMC 5FF 공정에서의 양산이 확정 됐다. 비록 퀄컴, 엔비디아의 물량을 삼성 파운드리 에게 빼앗기고, 하이실리콘의 물량은 금수조치로 인하여 2021년부터 주문을 받을 수 없다는 점을 감안해도, 여전히 초거대 고객사인 Apple, AMD, 미디어텍[5]의 주문을 받을 수 있기 때문에 회사의 성장세 자체는 계속 유지할 수 있을 것으로 보여진다.
실제로 우측의 표를 참고하면, Apple의 A14 Bionic 프로세서가 월 5만장 단위로 생산이 이뤄지고 있으며, 하이실리콘의 빈자리는 Apple M1이 완벽히 채울수 있을 것으로 전망된다. 또한 AMD 콘솔용 APU 생산만으로도 막대한 분량을 수주한 것으로 추정된다. 콘솔용 APU에 최우선적으로 리소스를 투입하여 AMD 라이젠 5000번대나 라데온 RX 6000번대는 생산에 차질을 빚고 있으며, 엔비디아가 삼성의 8나노 공정을 주문한 것도 이러한 맥락이 어느정도 작용했을 것이다.
2021년 12월, TSMC에 5나노를 기반으로 HPC 제품군에 적합한 N4X 공정을 발표했다. 1.2v에서 N5 대비 15%, N4P 대비 4% 빠른 성능을 보인다고 한다. 2023년 상반기에 리스크 생산을 시작한다고 한다.기사
25. 4 nm (2021년)[편집]
- 디멘시티 9000 (2021년)
- 퀄컴 스냅드래곤 8+ Gen 1 (2022년)
- Apple A16 Bionic SoC (2022년)
- 퀄컴 스냅드래곤 8 Gen 2 & 8 Gen 2 for GALAXY (2022년)
- 디멘시티 8200 (2022년)
- 디멘시티 9000+ (2022년)
- 디멘시티 9200 (2022년)[P]
- 퀄컴 스냅드래곤 7+ Gen 2(2023년)
- AMD ZEN 4 마이크로아키텍처 APU (2023년)
- 퀄컴 스냅드래곤 8 Gen 3 & 8 Gen 3 for GALAXY(2023년)[P]
- 퀄컴 스냅드래곤 7 Gen 3(2023년)
- 퀄컴 스냅드래곤 8s Gen 3 (2024년)
- 디멘시티 7200 (2023년)
- 디멘시티 8300 (2023년)
- 디멘시티 9200+ (2023년)[P]
- 디멘시티 9300 (2023년)[P+]
- 엔비디아 B100 (2024년)[6]
- 엔비디아 B200 (2024년)
26. 3 nm (2022년)[편집]
- Apple A17 Pro SoC (2023년)
- Apple M3, M3 Pro, M3 Max SoC (2023년)
TSMC의 3 nm 공정의 첫 고객은 Apple이 아니라 인텔로 인텔의 차기 GPU와 인텔 CPU용 GPU타일을 생산할 줄 알았으나 2026년으로 미뤄졌다.# 대신 원래대로 최대 고객사인 애플이 첫 번째 타자가 되며, 초기 물량 절대 다수를 차지할 예정이다.
2022년 12월, 타이난시 Fab 18에서 3nm공정의 양산이 공식적으로 시작됐다.#
2023년 첫 제품으로 애플 A17 Pro를 선보였으나, 누설전류 및 수율 측면에서 어려움을 겪고 있는 것으로 보인다. 이 때문인지 A17 Pro를 생산하는 N3B 공정은 사실상 애플만 쓸 예정이다.[7]
N5공정 기반의 M1 출하 당시 실제 총 다이 집적도 향상이 TSMC가 공언한 Area 감소치만큼 딱 들어맞았던 반면 A17 Pro는 그렇지 못했던 점, 기존에 N3라고 불리던 공정을 갑작스럽게 N3B로 명칭변경한 점, M3 계열 MacBook Pro의 가성비 후퇴, 이전 세대 만큼의 성능 향상을 띄지 못한다는 점 등으로 미루어 보아 TSMC 3nm 공정은 목표했던 밀도 향상치/수율을 달성하지 못했음을 짐작할 수 있다.
TSMC는 N3B의 수율이 70%에 도달하지 못하자, 애플을 상대로 웨이퍼가 아니라 동작하는 칩 단위로 가격을 책정하는 다소 이례적이고 불리한 계약을 진행했다고 알려졌다.
2024년 상반기에 양산하여 A18 Pro를 시작으로 하반기에 출시 예정인 N3E에서는 오히려 밀도가 후퇴하고 그 대신 성능과 수율 향상이 예정되어 있다. 이후 각각 2024년 하반기와 2025년에 양산을 시작할 N3P, N3X 등은 N3E의 설계를 바탕으로 하여 기존 N3B의 밀도를 회복하고 N3E 공정에 비해 성능 추가 향상이 예정되어 있다.
그럼에도 불구하고 2024년 1월 컨퍼런스 콜에서는 2023년 4분기에서 3nm 매출 비중이 15%에 달한다고 밝혔다. 직전 분기였던 3분기의 6% 대비 매우 높아진 수치다.#
2026년부터는 애리조나 Fab 21-2에서 월 3만 장 규모의 양산도 시작될 예정이다.
27. 2 nm (2025년)[편집]
2020년 TSMC 연구개발 수석 부사장 YJ Mii에 따르면 2nm 공정을 현실화하기 위해, 차세대 노광장비를 개발 중인 ASML과 협력하고 있다고 밝혔다.[8]
2025년 신주 Fab 20에서 N2를 시작으로 후면전원공급과 GAAFET을 적용 예정이며, 2026년부터 업그레이드 버전인 N2P와 N2X의 본격적인 양산이 시작될 예정이다.
28. 1.4nm(2027년)[편집]
로드맵상으로 A14라는 이름으로 2027년 양산 예정이며 7nm 시절 EUV를 늦게 도입하였듯이 1.4nm에서는 High-NA EUV를 도입하지 않고 A10인 1nm급 공정부터 사용할 예정이다.

 이 문서의 내용 중 전체 또는 일부는 2024-04-08 02:50:16에 나무위키 TSMC/공정 노드 추이 문서에서 가져왔습니다.
이 문서의 내용 중 전체 또는 일부는 2024-04-08 02:50:16에 나무위키 TSMC/공정 노드 추이 문서에서 가져왔습니다.[1] FM대로 하면 파운드리가 팹리스의 요청을 최대한 반영하고 팹리스의 피해를 최소화하는 것이 맞지만 그건 FM이고 현실은 다르다. 매우 현실적으로 보아도 TSMC가 경쟁 시장에 놓여 있다하더라도 시제품을 생산해 볼 건덕지가 없는 파운드리 업체 특성상 팹리스에게 약간의 피해를 돌려서라도 공정을 테스트하려고 들었을 것이다.[P] A B C D E F G H I [2] 웨이퍼를 빛에 반응하는 PR로 덮은 뒤 빛을 조사하고 반응한 부분 혹은 반응하지 않은 부분만 씻겨내어 회로를 새기는 것을 말한다.[3] 다만 H100 생산에 사용된 4N공정은 말만 4nm일 뿐 실제로는 5nm의 파생형으로 추정된다. AD시리즈 칩들은 TSMC N5 초기형에서 생산된 Apple M1과 동급의 트랜지스터 밀도를 보여주는데, 빅칩 HPC용 공정임을 감안해도 4nm라 부르기에는 밀도가 지나치게 낮다.[4] 다만 GeForce 40 생산에 사용된 4N공정은 말만 4nm일 뿐 실제로는 5nm의 파생형으로 추정된다. AD시리즈 칩들은 TSMC N5 초기형에서 생산된 Apple M1과 동급의 트랜지스터 밀도를 보여주는데, 빅칩 HPC용 공정임을 감안해도 4nm라 부르기에는 밀도가 지나치게 낮다.[5] 다만, 2020년 9월 뉴스에 따르면 미디어텍 수주 역시 불발이라고 한다.[P+] [6] 4NP노드로 기존 엔비디아 커스텀 노드인 4N과도 다르다[7] A17 Pro만을 위한 일회용이라는 전망이 있었으나, M3 시리즈가 동일 아키텍처를 가졌으므로 해당 공정을 이용하게 되었다.[8] 국내에서는 잘못된 루머가 퍼지면서 TSMC가 2nm 공정부터 ASML, AMAT의 장비가 아닌, 자체적으로 개발한 장비를 사용한다고 알려졌으나 이는 사실이 아닌 것으로 드러났다. 상식적으로 해당 사업 이력이 전무한 TSMC가 ASML의 독보적인 기술력을 따라잡고 자체적으로 노광장비를 개발하는 것은 거의 불가능하다.